标签:ble provides switch next let ssi lead within automatic
the core of HADOOP/distributed systems is storeage(HDFS) and resource manager(YARN) for computing engines built on it.
Master/Slave: The character of distribution system follows M/S pattern.
NN is the master and single active node. it contains / manges the namespace of files/dirs so called metadata , keeps block location andallocate data nodes.
Metadata is just like the one in linux file system including file name,size,owner/user,group,permission(umask) and HDFS specified elements like block ids , replication factor and block size and so on. Meta is in both memory and disk for fast access and restore respectively. NN also contains block location but it does not save it which is actually from DN. When a client access HDFS, it talks to NN first , NN checks the the permission, file existing just like the normal operation in a non-distributed linux system.
The one actually stores files in form of blocks.
once a NN starts up, it sends its block report to NN like ‘I(NN-1) has blocks #1,#2....‘ and it sends it periodically. So,NN can build a mapping of which bock in which DNs to serve file access request. DN also sends heartbeat information every 3 seconds to report its status along with actual data storage(total, free, used space and data transfer current in progress....) which is used for block allocating and and load banlancing by NN. a DN is considered dead if NN does not receive the HB within 10 mins. What is about the replication? It is for fault tolerance. If a block lost or a DN goes down, there is other nodes containing the same blocks. Also, based on the replciation, the system will also automatically replica the blocks if the number of copies does not meet the level.
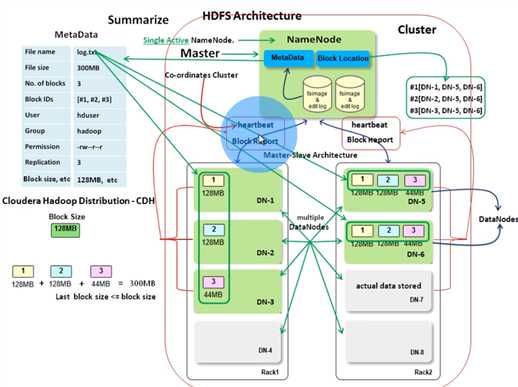
Rack is nothing but a box with machines. dedicated power suply and network switch.
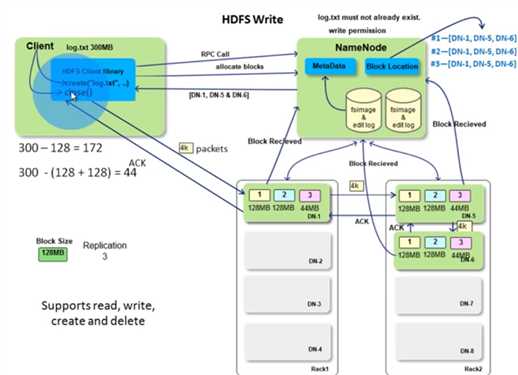
It should be easy to understand if you know the hdfs arch. client uses the hdfs client lib to manuplicate files. The communication is done thru RPC call. As mentioned before, NN will check metadata to see if client is qualified to write files. Then clients request NN to allocates blocks and NN returns the DN list(NN knows the status for each DN). for client to write the first 128MB block which is accumulated in the client library‘s managed space. This is the leader-folower pattern.The write to DNs is a pipleline so it is synchronized writing? client/leader writes data in a 4k packets and followers sends ACK so i guess it is synchronized writing. DNs also send the information to NN once it recieved the blocks. So, NN can build the block location in the write process as well. Then it contines to write the next 128 MB blocks. It loops till reach the EOF of the file. finally the client close() and indicates the operation is completed.
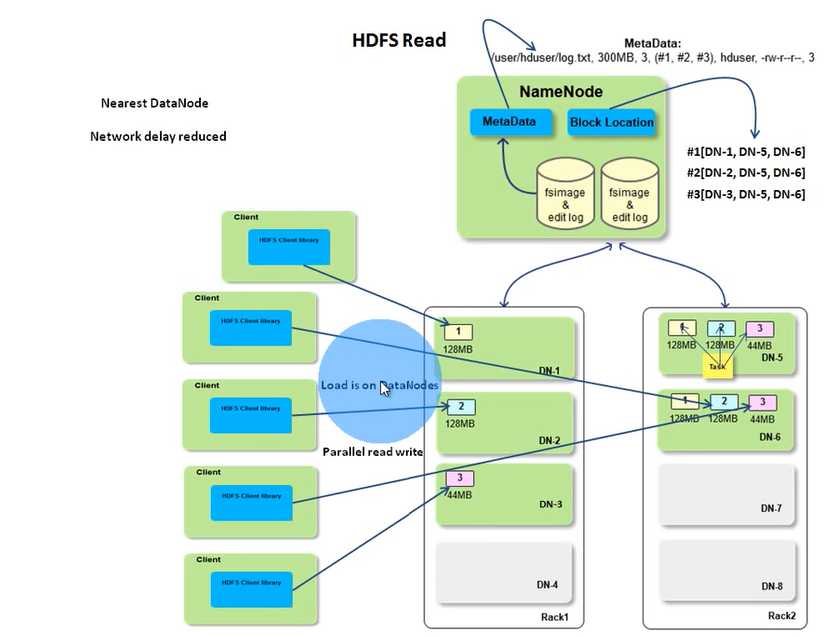
As mentioned before, you need HDFS java client library to perform the read operation like open the file, read the stream. client will call NN thru RPC to get the block id and block location. NN metadata has the block IDs for a file and the block location holds the mapping. Both of them are in memory and it should be fast. The actually read is between client and the DN. If the client is in a DN like a map task, the NN will return the block location with a list of network distance sort so the network delay will be reduced between racks. If the DN the map task is running on contains the blocks it needs, it will read directly locally. If the reading fails, client will switch to another node to read in the location list. Because of the data transfermation is between clients(you may have many current reads) and data nodes and name node only provides the block location, so, the load is distributed across the cluster. That‘s why HDFS is scalable. It may be not good to store vary large number of small files as name node may response poorly due to managing too much metadata.
标签:ble provides switch next let ssi lead within automatic
原文地址:https://www.cnblogs.com/nativestack/p/9529298.html