标签:bho pagerduty manager oba 存储 rar 图形 gate config
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: ‘codelab-monitor‘
# A scrape configuration containing exactly one endpoint to scrape:
# Here it‘s Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: ‘prometheus‘
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: [‘localhost:9090‘]
- job_name: ‘node_10.90.187.55‘ # 一定要全局唯一, 采集本机的 metrics,需要在本机安装 node_exporter
scrape_interval: 10s
static_configs:
- targets: [‘10.90.187.55:9100‘] # 本机 node_exporter 的 endpointdocker run -p 9090:9090 -v ~/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus Prometheus 组成及架构
Prometheus 生态圈中包含了多个组件,其中许多组件是可选的:
Prometheus Server: 用于收集和存储时间序列数据。
Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
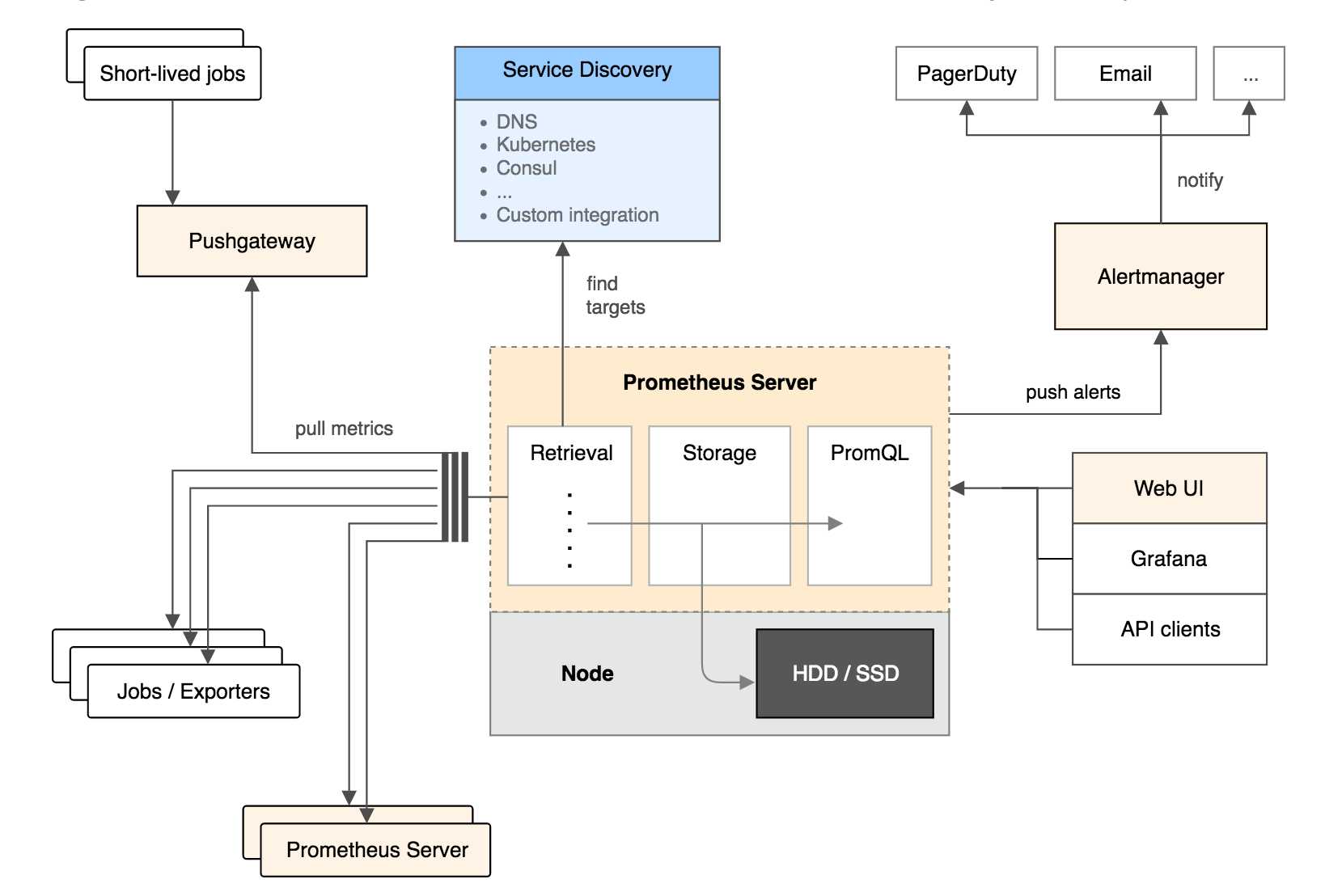
其大概的工作流程是:
Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
在图形界面中,可视化采集数据。
标签:bho pagerduty manager oba 存储 rar 图形 gate config
原文地址:https://www.cnblogs.com/abcyrf/p/9550225.html