标签:knn and 分享 pyplot 技术 http san save size
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
diabetes = pd.read_csv('./diabetes.csv')
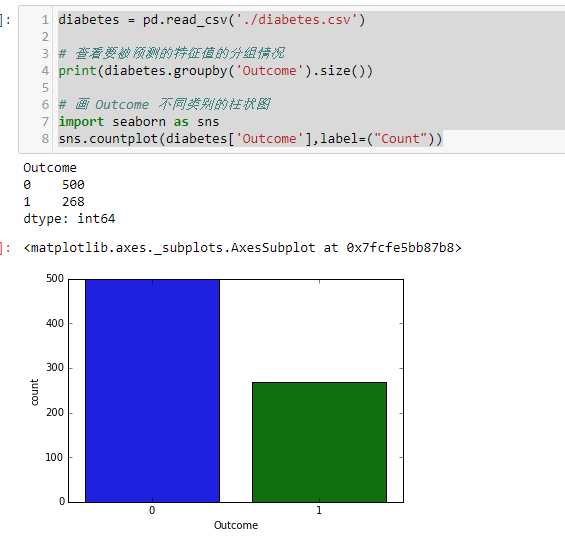
# 查看要被预测的特征值的分组情况
print(diabetes.groupby('Outcome').size())
# 画 Outcome 不同类别的柱状图
import seaborn as sns
sns.countplot(diabetes['Outcome'],label=("Count"))
from sklearn.model_selection import train_test_split
# 参数stratify: 依据标签y,按原数据y中各类比例,分配给train和test,使得train和test中各类数据的比例与原数据集一样。
X_train,X_test, y_train, y_test = train_test_split(diabetes.loc[:,diabetes.columns != 'Outcome'],diabetes['Outcome'],stratify=diabetes['Outcome'],random_state=66)
# 开始 KNN
from sklearn.neighbors import KNeighborsClassifier
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
# build the model
knn = KNeighborsClassifier(n_neighbors=n_neighbors)
knn.fit(X_train,y_train)
# record training set accuracy
training_accuracy.append(knn.score(X_train,y_train))
test_accuracy.append(knn.score(X_test,y_test))
plt.plot(neighbors_settings,training_accuracy,label="training accuracy")
plt.plot(neighbors_settings,test_accuracy,label="test accuracy")
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.legend()
plt.savefig('knn_compare_model')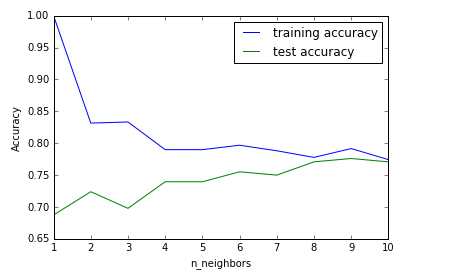
# 线性逻辑回归
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression(C=1).fit(X_train,y_train)
print("Training set accuracy score: {:.3f}".format(logreg.score(X_train,y_train)))
print('Test set accuracy score: {:.3f}'.format(logreg.score(X_test,y_test)))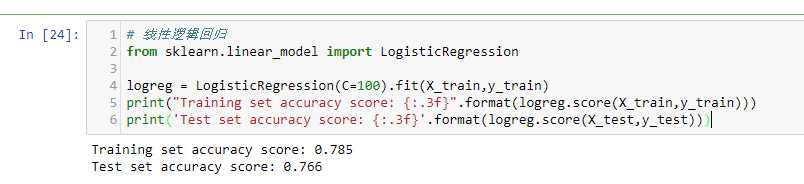
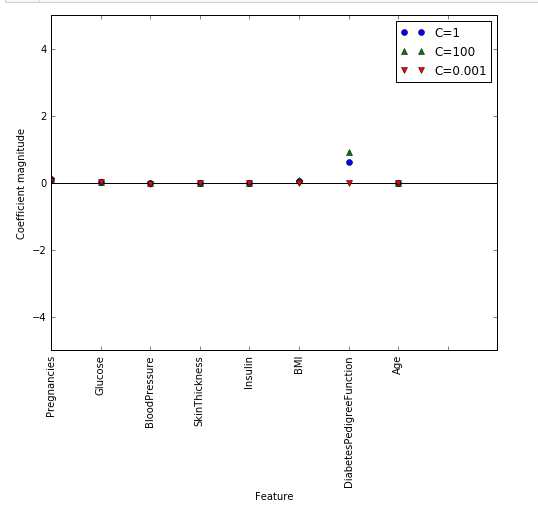
# 正则化参数为 100
logreg100 = LogisticRegression(C=100).fit(X_train,y_train)
logreg001 = LogisticRegression(C=0.001).fit(X_train,y_train)
diabetes_features = [x for i,x in enumerate(diabetes.columns) if i!=8]
plt.figure(figsize=(8,6))
plt.plot(logreg.coef_.T, 'o',label="C=1")
plt.plot(logreg100.coef_.T, '^',label="C=100")
plt.plot(logreg001.coef_.T, 'v', label="C=0.001")
plt.xticks(range(diabetes.shape[1]), diabetes_features,rotation=90)
plt.hlines(0,0,diabetes.shape[1])
plt.ylim(-5,5)
plt.xlabel("Feature")
plt.ylabel("Coefficient magnitude")
plt.legend()
plt.savefig("log_coef")
# 决策树分类器
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(random_state=0)
tree.fit(X_train,y_train)
print("Accuracy on training set: {:.3f}".format(tree.score(X_train,y_train)))
print("Accuracy on test set: {:.3f}".format(tree.score(X_test,y_test)))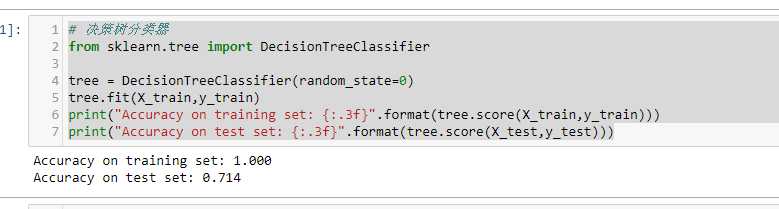
训练集的准确度可以高达100%,而测试集的准确度相对就差了很多。这表明决策树是过度拟合的,不能对新数据产生好的效果。因此,我们需要对树进行预剪枝。
我们设置max_depth=3,限制树的深度以减少过拟合。这会使训练集的准确度降低,但测试集准确度提高。
标签:knn and 分享 pyplot 技术 http san save size
原文地址:https://www.cnblogs.com/Frank99/p/9555103.html