标签:home data 溢出 kkk 是什么 ast tachyon div lips
1.是什么:
? Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。2012年,它是由加州伯克利大学AMP实
验室开源的类 Hadoop MapReduce 的通用并行计算框架,Spark 拥有Hadoop MapReduce 所具有的优点;但不
同于MapReduce 的是 Job 中间输出结果可以保存在内存中,从而不再需要读写 HDFS,因此 Spark 能更好地适用
于数据挖掘与机器学习等需要迭代的 MapReduce 的算法。
2.spark VS hadoop:
发展历程:hadoop:2005 spark:2012
速度效率:两者都是分布式计算框架,Spark 基于内存,MR 基于 HDFS。Spark 处理数据的能力一般是 MR 的十倍以上,Spark 中除了基于内存计算外,还有 DAG 有向无环图来切分任务的执行先后顺序
3.spark运行模式:
①Local--->多用于本地测试,如在 eclipse,idea 中写程序测试等
②Standalone 是--->Spark 自带的一个资源调度框架,它支持完全分布式。
③Yarn--->Hadoop 生态圈里面的一个资源调度框架,Spark 也是可以基于 Yarn来计算的。
④Mesos-->资源调度框架。要基于 Yarn 来进行资源调度,必须实现 AppalicationMaster 接口,Spark 实现了这个接口,所以可以基于 Yarn。
二、sparkcore
1.RDD---弹性分布式数据集。
特点:①RDD 是由一系列的 partition 组成的、②函数是作用在每一个 partition(split)上的、③RDD 之间有一系列的依赖关系、④分区器是作用在 K,V 格式的 RDD 上、⑤RDD 提供一系列最佳的计算位置
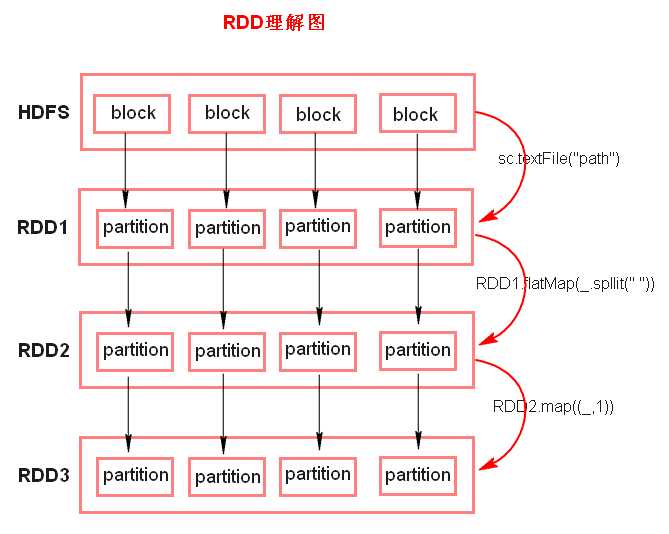
◆ 注意: ? textFile 方法底层封装的是读取 MR 读取文件的方式,读取文件之前 先 split,默认 split 大小是一个 block 大小。 ? RDD 实际上不存储数据,这里方便理解,暂时理解为存储数据。 ? 什么是 K,V 格式的 RDD? ? 如果 RDD 里面存储的数据都是二元组对象,那么这个 RDD 我们 就叫做 K,V 格式的 RDD。 ? 哪里体现 RDD 的弹性(容错)? ? partition 数量,大小没有限制,体现了 RDD 的弹性。 ? RDD 之间依赖关系,可以基于上一个 RDD 重新计算出 RDD。 ? 哪里体现 RDD 的分布式? ? RDD 是由 Partition 组成,partition 是分布在不同节点上的。 ? RDD 提供计算最佳位置,体现了数据本地化。体现了大数据中“计 算移动数据不移动”的理念。
2.pycharm的环境部署(参考:https://blog.csdn.net/TreasureNow/article/details/79076266简单!)
3.spark的代码流程
1. 创建 SparkConf 对象 ? 可以设置 Application name。 ? 可以设置运行模式及资源需求。 2. 创建 SparkContext 对象 3. 基于 Spark 的上下文创建一个 RDD,对 RDD 进行处理。 4. 应用程序中要有 Action 类算子来触发 Transformation 类算子执行。 5. 关闭 Spark 上下文对象 SparkContext。
代码实例
from pyspark import SparkContext from pyspark import SparkConf conf = SparkConf().setAppName(‘count‘).setMaster(‘local[*]‘) sc = SparkContext(conf=conf) data = [‘hehe yi kkk nys os‘,‘ni shi kak‘,‘na laen is lie‘] datardd = sc.parallelize(data) # result = datardd.map(lambda x:x.split(‘ ‘)).collect() # print(result) result =datardd.flatMap(lambda x:x.split(‘ ‘)).map(lambda w:(w,1)).collect() print(result)
4.算子---转换算子和行动算子
(1)Transformations 转换算子:Transformations 类算子是一类算子(函数)叫做转换算子,如map,flatMap,reduceByKey 等。Transformations 算子是延迟执行,也叫懒加载执行。
流程
? map 将一个 RDD 中的每个数据项,通过 map 中的函数映射变为一个 新的元素。 特点:输入一条,输出一条数据。 ? flatMap 先 map 后 flat。与 map 类似,每个输入项可以映射为 0 到多个 输出项。 ? reduceByKey 将相同的 Key 根据相应的逻辑进行处理。 ? sortby ? sortByKey 作用在 K,V 格式的 RDD 上,对 key 进行升序或者降序排序。
(2)Action 行动算子:Action 类算子也是一类算子(函数)叫做行动算子,如foreach,collect,count 等。Transformations 类算子是延迟执行,Action 类算子是触发执行。一个 application 应用程序中有几个Action 类算子执行,就有几个 job 运行。
流程:
? collect 将计算结果回收到 Driver 端。
? foreach 可以循环迭代取出各节点服务器上的内容
代码分享:
from pyspark import SparkContext from pyspark import SparkConf ‘‘‘ count ‘‘‘ # 系统设置conf conf =SparkConf().setAppName(‘count‘).setMaster(‘local‘) context = SparkContext(conf=conf) data = [‘zhang san is a student ‘,‘lisi like play basketball‘,‘wanger like durking‘,‘zl sick of study‘,‘hehe is a boy‘] # map(lambda x:x.split(" ")) # 对数据进行序列化 datardd = context.parallelize(data) # result = datardd.flatMap(lambda x:x.split(‘ ‘)).map(lambda w: (w,1)).reduceByKey(lambda a,b:a+b).collect() # print(result) # 这里用map把原来的data数据按引号划分成五个部分,通过reduceByKey来统计各部分出现的次数. # result = datardd.map(lambda w: (w,1)).reduceByKey(lambda a,b:a+b).collect() # print(result) # 这里的map ,它返回的是由一个个元素组成的小列表,最终由这些小列表组成一个大列表 # result = datardd.map(lambda x:x.split(‘ ‘)).collect() # print(result) #这里用的是flatmp 它返回的是由一个个打散的元素组成的列表 # result = datardd.flatMap(lambda x:x.split(‘ ‘)).collect() # print(result) # 这里最终的打印结果用foreach来处理,它最大的好处在于:不像collect把所有的数据全部放在列表里 # 这样很容易导致内存被撑爆,所以在不知道数据量大小的情况下最好少用collect,这里就用到了foreach # 通过遍历循环将数据结果挨个挨个打印出来. result = datardd.flatMap(lambda x:x.split(‘ ‘)) def f(x): print(x) re = result.foreach(f) print(re)
分享二:
from pyspark import SparkContext from pyspark import SparkConf import pickle conf = SparkConf().setAppName(‘count‘).setMaster(‘local[*]‘) sc = SparkContext(conf=conf) text_file =sc.textFile(r‘E:\Hbase\api\text_file‘) counts = text_file.flatMap(lambda x: x.split(" ")) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b).collect() print(counts) f = open(‘test.txt‘,‘wb‘) pickle.dump(counts,f)
5.Spark 任务执行原理
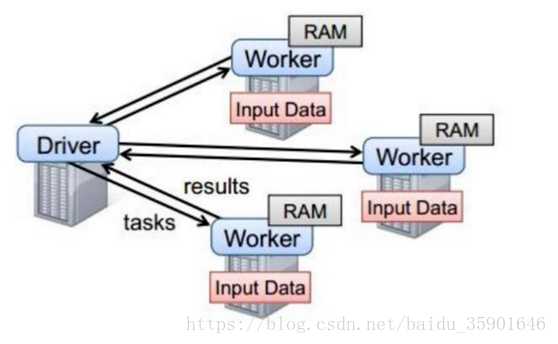
以上图中有四个机器节点,Driver 和 Worker 是启动在服务器节点上的进程,这些进程都运行在 JVM 中
上述图的运行步骤:
Driver 与集群节点之间有频繁的通信。
Driver 负责任务(tasks)的分发和结果的回收、任务的调度。如果 task的计算结果非常大就不要回收了,会造成 OOM(内存溢出)。
Worker 是 Standalone 资源调度框架里面资源管理的从节点,也是JVM 进程。
Master 是 Standalone 资源调度框架里面资源管理的主节点。也是JVM 进程。
6.spark缓存策略

eOffHeap, _deserialized, _replication(默认值为1) 5.MEMORY_ONLY_SER SER做序列化。会消耗CPU。 参数:_useDisk, _useMemory, _useOffHeap, _deserialized, _replication(默认值为1) 6.MEMORY_ONLY_SER_2 参数:_useDisk, _useMemory, _useOffHeap, _deserialized, _replication(默认值为1) 7.MEMORY_AND_DISK 内存中若放不下,则多出的部分放在机器的本地磁盘上,区别于MEMORY_ONLY(内存中若放不下,则多出的部分原来在哪就还在哪) 参数:_useDisk, _useMemory, _useOffHeap, _deserialized, _replication(默认值为1) 8.MEMORY_AND_DISK_2 参数:_useDisk, _useMemory, _useOffHeap, _deserialized, _replication(默认值为1) 9.MEMORY_AND_DISK_SER 参数:_useDisk, _useMemory, _useOffHeap, _deserialized, _replication(默认值为1) 10.MEMORY_AND_DISK_SER_2 参数:_useDisk, _useMemory, _useOffHeap, _deserialized, _replication(默认值为1) 11.OFF_HEAP(不使用堆,比如可以使用Tachyon) 参数:_useDisk, _useMemory, _useOffHeap, _deserialized, _replication(默认值为1)
三.集群搭建-----standlone
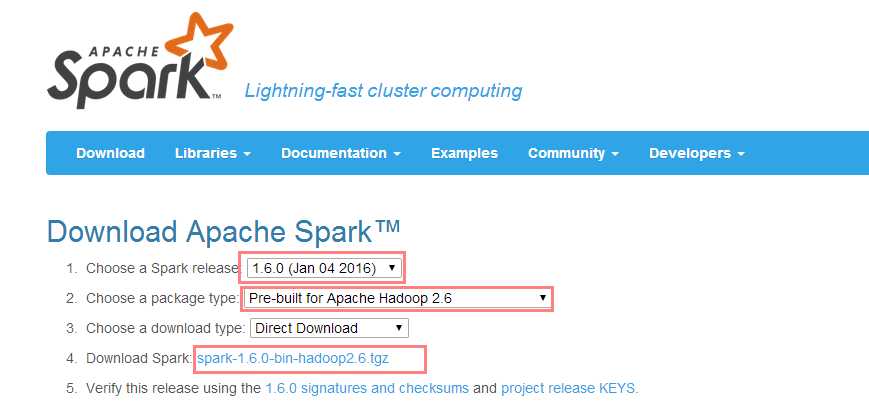
1).下载安装包、解压、改名


2).进入安装包的 conf 目录下,修改 slaves.template 文件,添加从节点。


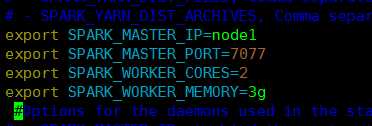
3).修改 spark-env.sh
SPARK_MASTER_IP:master 的 ip SPARK_MASTER_PORT:提交任务的端口,默认是 7077 SPARK_WORKER_CORES:每个 worker 从节点能够支配的 core 的个 数 SPARK_WORKER_MEMORY:每个 worker 从节点能够支配的内存数
注意:拷贝到其它节点:scp -r spark-1.6 node02:/home/mysoft
4)启动集群:记住sbin目录 ./start-all.sh
标签:home data 溢出 kkk 是什么 ast tachyon div lips
原文地址:https://www.cnblogs.com/luren-hometown/p/9557753.html