标签:list users 数据 upper duplicate pre 实现 分享图片 pen
代码实现:
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Thu Aug 30 08:48:18 2018 4 5 @author: zhen 6 """ 7 8 import numpy as np 9 from sklearn.tree import DecisionTreeRegressor 10 import pandas as pd 11 import matplotlib.pyplot as plt 12 13 file_path = ‘C:/Users/zhen/Desktop/jupyter_python/物资数据.csv‘ 14 #读取物资类采购目录sheet页 15 pfzwkytz = pd.read_csv(file_path, engine=‘python‘, encoding=‘utf-8‘) 16 dic = dict() 17 # 对数据进行预处理,决策树需要使用数值型数据,因此把字符型数据转成对应的数值,相同字符对应的数值相同 18 def strlist_to_intlist(coll): 19 flt_list = [] 20 loc = 0 21 for col in coll: 22 if not dic.__contains__(col): 23 dic[col] = loc 24 flt_list.append(loc) 25 loc = loc + 1 26 else: 27 flt_list.append(dic.get(col)) 28 return flt_list 29 30 31 # 抽样获取测试数据和训练数据 32 train_data = pfzwkytz.sample(frac=0.8) 33 test_data = pfzwkytz.append(train_data).drop_duplicates(keep=False) 34 35 train_x = np.array(strlist_to_intlist(train_data[‘四级分类‘])).reshape(-1, 1).astype(‘int‘) 36 train_y = np.array(train_data[‘批复数量‘]).reshape(-1, 1).astype(‘int‘) 37 38 decision_tree_regressor = DecisionTreeRegressor(max_depth=10) 39 decision_tree_regressor.fit(train_x, train_y) 40 41 # 创建测试数据 42 test_x = np.array(strlist_to_intlist(test_data[‘四级分类‘])).reshape(-1, 1).astype(‘int‘) 43 test_y = np.array(test_data[‘批复数量‘]).reshape(-1, 1).astype(‘int‘) 44 45 y_hat = decision_tree_regressor.predict(test_x) 46 47 plt.plot(test_x, test_y, "y^", label="actual") 48 plt.plot(test_x, y_hat, "b.", label="predict") 49 50 plt.legend(loc="upper right") 51 plt.grid() 52 plt.show()
基于决策树回归:
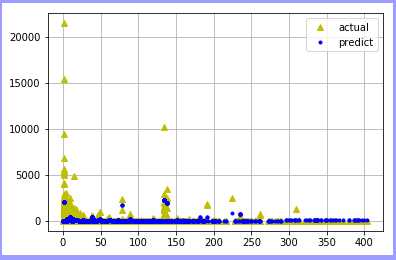
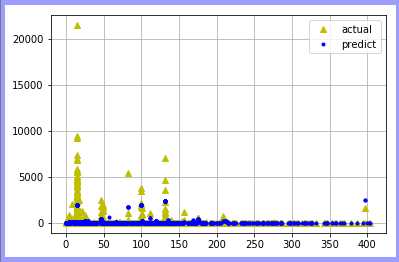
基于决策树分类:
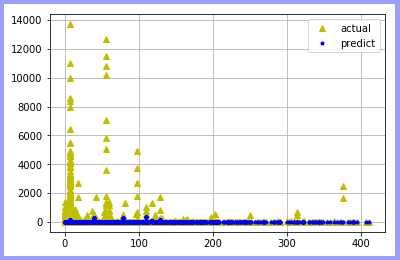
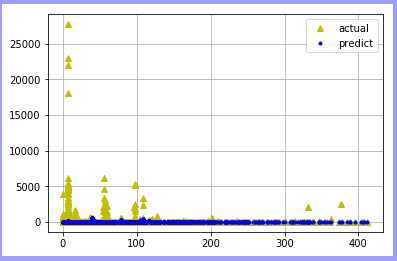
总结:可知在使用同一数据源抽样训练模型中,使用回归进行拟合比使用分类效果更好!
标签:list users 数据 upper duplicate pre 实现 分享图片 pen
原文地址:https://www.cnblogs.com/yszd/p/9560644.html