首页
Web开发
Windows程序
编程语言
数据库
移动开发
系统相关
微信
其他好文
会员
首页
>
其他好文
> 详细
SVM原理
时间:
2018-08-30 19:55:15
阅读:
286
评论:
0
收藏:
0
[点我收藏+]
标签:
org
inf
数据
处理
lse
泛化
梯度
exp
分离
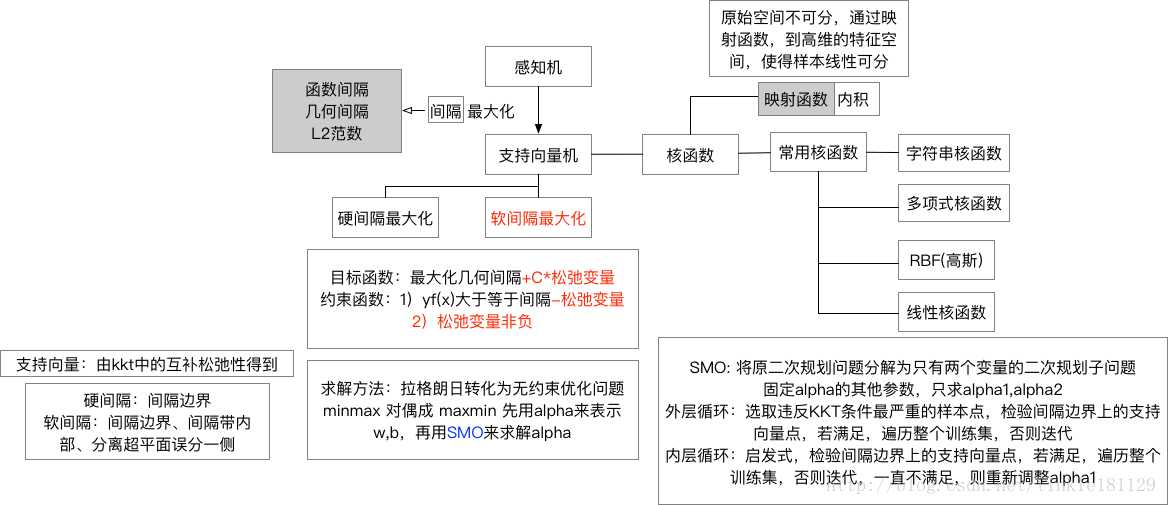
SVM的原理是什么?
有别于感知机,SVM在特征空间中寻找间隔最大化的分离超平面的线性分类器
SVM为什么采用间隔最大化?
超平面可以有无穷多个,但是几何间隔最大的分离超平面是唯一的,这样的分类结果也是鲁棒的,对未知实例的泛化能力最强。
什么是支持向量?
对于硬间隔,支持向量就是间隔边界上的样本点
对于软间隔,支持向量就是间隔边界、间隔带内、分离超平面误分类一侧的样本点
在确定分类超平面时只有支持向量起作用,因此SVM由很少的“重要的“训练样本确定
为什么要将SVM的原始问题转化为对偶问题?
更容易求解(引入拉格朗日乘子,将约束优化转化为无约束优化问题)
引入核函数 (
?
(
x
)
?
(
x
)
?(x)?(x)),推广到非线性分类
为什么要scale the inputs?(对数据进行归一化处理)
SVM对特征规模非常敏感,如果不对特征进行规范化,会导致生成的间隔带依赖于scale大的那个特征,即生成不合适的svm
为什么SVM对缺失数据敏感?
不同于决策树,SVM没有处理缺失值的策略,它希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要
什么是核函数?
当样本在原始空间线性不可分时,可以将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。这个映射函数我们记为
?
(
x
)
?(x)
在原始问题的对偶问题中需要求解
?
(
x
)
?
(
y
)
?(x)?(y),直接计算比较困难,因此找一个核函数
k
(
x
,
y
)
=
?
(
x
)
?
(
y
)
k(x,y)=?(x)?(y),即在特征空间的内积等于它们在原始样本空间中进行核函数
k
k计算
常用的核函数有哪些,如何选择?
RBF核/高斯核 :
k
(
x
i
,
x
j
)
=
e
x
p
(
?
|
|
x
i
?
x
j
|
|
2
2
σ
2
)
k(xi,xj)=exp(?||xi?xj||22σ2),其中
σ
σ为高斯核的带宽
多项式核:
k
(
x
i
,
x
j
)
=
(
x
T
i
x
j
)
d
k(xi,xj)=(xiTxj)d,当d=1时退化为线性核
拉普拉斯核:
k
(
x
i
,
x
j
)
=
e
x
p
(
?
|
|
x
i
?
x
j
|
|
2
σ
)
k(xi,xj)=exp(?||xi?xj||2σ)
Sigmoid核:
k
(
x
i
,
x
j
)
=
t
a
n
h
(
β
x
T
i
x
j
+
θ
)
k(xi,xj)=tanh(βxiTxj+θ)
字符串核
选择方法:经验+实验
(吴恩达)
如果Feature的数量很大,跟样本数量差不多,LR or Linear Kernel SVM
如果Feature的数量比较小,样本数量一般,不大不小,Gaussian Kernel SVM
如果Feature的数量比较小,而样本数量很多,手工添加Feature+LR or Linear Kernel SVM
如果一个SVM用RBF导致过拟合了,应该如何调整
σ
σ和C的值?
RBF的外推能力随着
σ
σ的增加而减小,相当于映射到一个低维的子空间,如果
σ
σ很小,则可以将任意的数据线性可分,但是会产生过拟合问题,因此要增大
σ
σ和减小
C
C
为什么说SVM是结构风险最小化模型?
SVM在目标函数中有一项
1
2
|
|
w
|
|
2
12||w||2,它自带正则
SVM如何处理多分类问题?
one vs one
one vs 多,bias 较高
SVM和LR的比较
样本点对模型的作用不同,SVM仅支持向量(少量样本点)而LR是全部样本点
损失函数不同,SVM hinge LR log
输出不同。 LR可以有概率值,而SVM没有
过拟合能力不同。 SVM 自带正则,LR要添加正则项
处理分类问题能力不同。 SVM 二分类,需要 one vs one or one vs all 。 LR可以直接进行多分类
计算复杂度。 海量数据中SVM效率较低
数据要求。 SVM需要先对样本进行标准化
能力范围。 SVM 可以用于回归
KKT条件
支撑平面:和支持向量相交的平面;分割平面:支撑平面中间的平面(最优分类平面)
SVM不是定义损失,而是定义支持向量之间的距离为目标函数
正则化参数对支持向量数的影响:
正则化参数越大,说明惩罚越多,则支持向量数越少
感知机 (判别模型)
目标函数:
f
(
x
)
=
s
i
g
n
(ω
x
+
b
)
f(x)=sign(ωx+b)
损失函数:
L
(ω
,
b
)
=
?
∑
x
i
∈
M
y
i
(ω
x
i
+
b
)
L(ω,b)
解决方法:随机梯度下降,每一次随机选取一个误分类点使其梯度下降
SVM原理
标签:
org
inf
数据
处理
lse
泛化
梯度
exp
分离
原文地址:https://www.cnblogs.com/zwjhq/p/9559110.html
踩
(
0
)
赞
(
0
)
举报
评论
一句话评论(
0
)
登录后才能评论!
分享档案
更多>
2021年07月29日 (22)
2021年07月28日 (40)
2021年07月27日 (32)
2021年07月26日 (79)
2021年07月23日 (29)
2021年07月22日 (30)
2021年07月21日 (42)
2021年07月20日 (16)
2021年07月19日 (90)
2021年07月16日 (35)
周排行
更多
分布式事务
2021-07-29
OpenStack云平台命令行登录账户
2021-07-29
getLastRowNum()与getLastCellNum()/getPhysicalNumberOfRows()与getPhysicalNumberOfCells()
2021-07-29
【K8s概念】CSI 卷克隆
2021-07-29
vue3.0使用ant-design-vue进行按需加载原来这么简单
2021-07-29
stack栈
2021-07-29
抽奖动画 - 大转盘抽奖
2021-07-29
PPT写作技巧
2021-07-29
003-核心技术-IO模型-NIO-基于NIO群聊示例
2021-07-29
Bootstrap组件2
2021-07-29
友情链接
兰亭集智
国之画
百度统计
站长统计
阿里云
chrome插件
新版天听网
关于我们
-
联系我们
-
留言反馈
© 2014
mamicode.com
版权所有 联系我们:gaon5@hotmail.com
迷上了代码!