目前hadoop1的稳定版本是1.2.1,我们以版本1.2.1为例详细的介绍hadoop1的安装,此过程包括OS安装与配置,JDK的安装,用户和组的配置,这些过程在hadoop2也有可能用到。
Hadoop 版本:1.2.1
OS 版本: Centos6.4
Jdk 版本: jdk1.6.0_32
环境配置
|
机器名 |
Ip地址 |
功能 |
|
Hadoop1 |
192.168.124.135 |
namenode, datanode, secondNameNode jobtracker, tasktracer |
|
Hadoop2 |
192.168.124.136 |
Datanode, tasktracker |
|
Hadoop3 |
192.168.124.137 |
Datanode, tasktracker |
OS安装
从Centos官网上下载Centos6.4版本的系统,然后在Vmware Player虚拟机中安装虚拟机
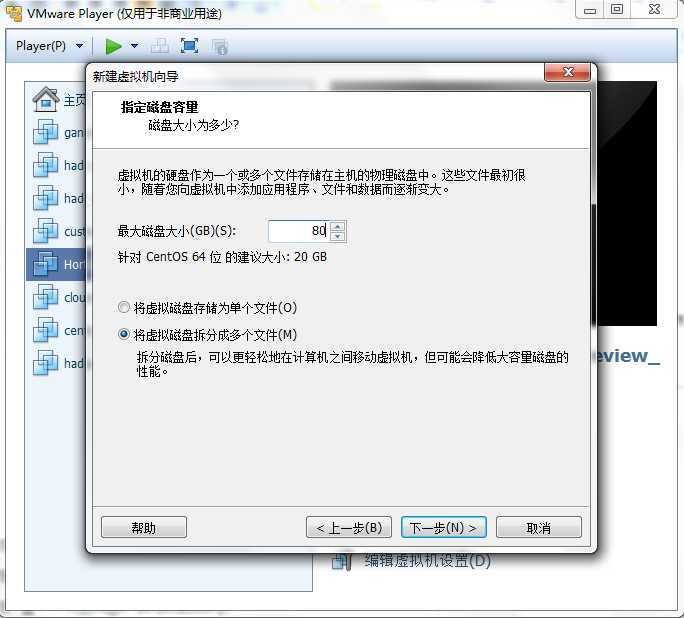
默认的20G空间可能不够用,修改为80G空间
点下一步,可以看出虚拟机的默认配置,1G内存,NAT网卡
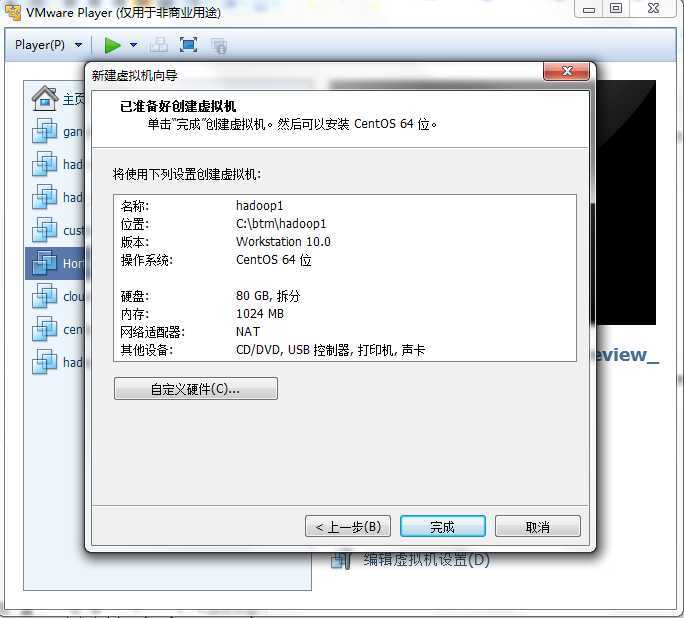
点击播放虚拟机,点击Playerà 可移动设备àCD/DVD(IDE)à设置,在弹出的对话框中设置:使用ISO映像文件,选择Centos系统的文件
然后一步步的安装系统,可以按照下面的流程做

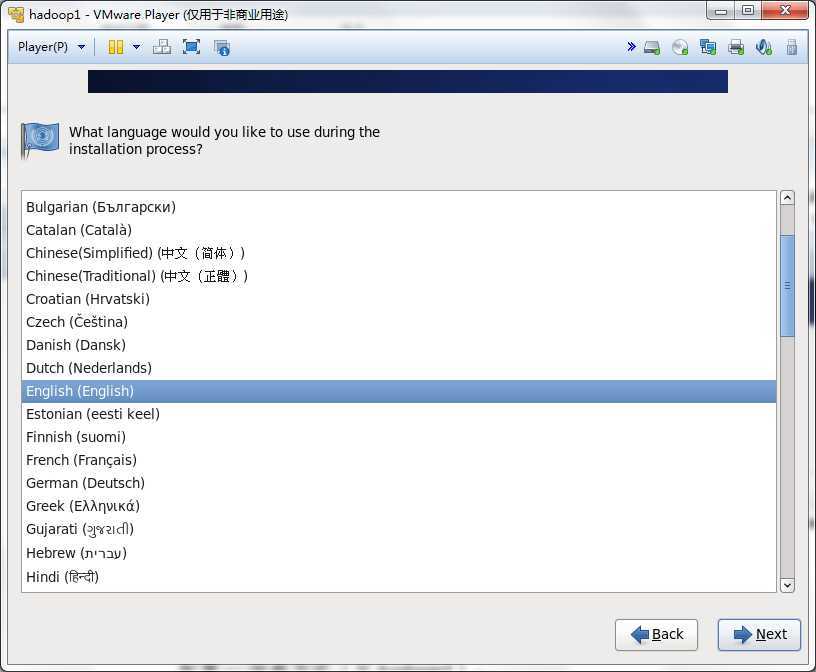
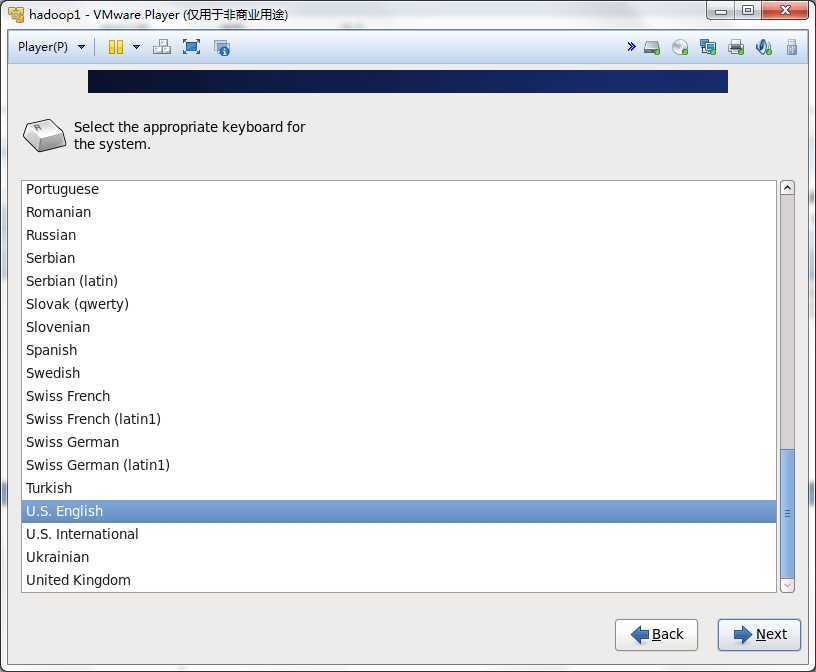
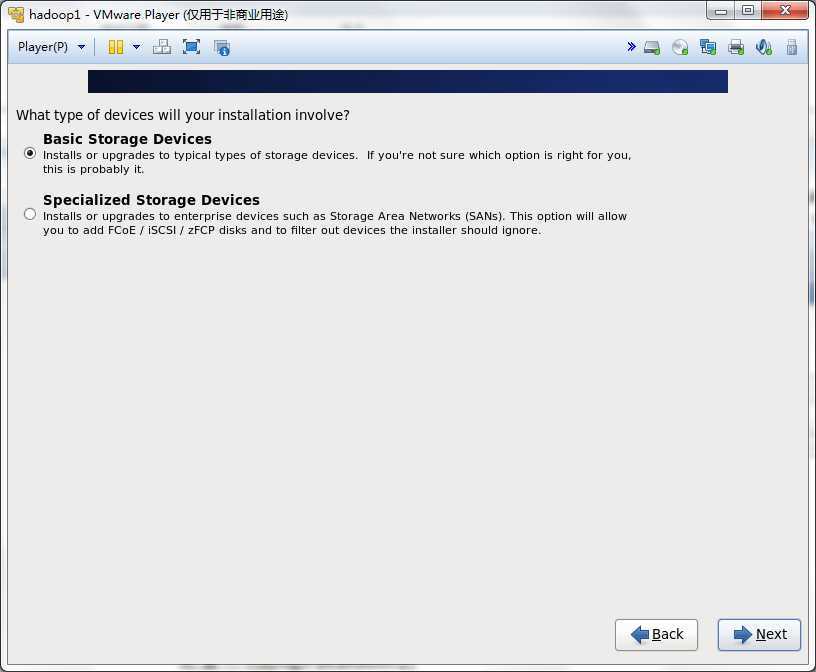
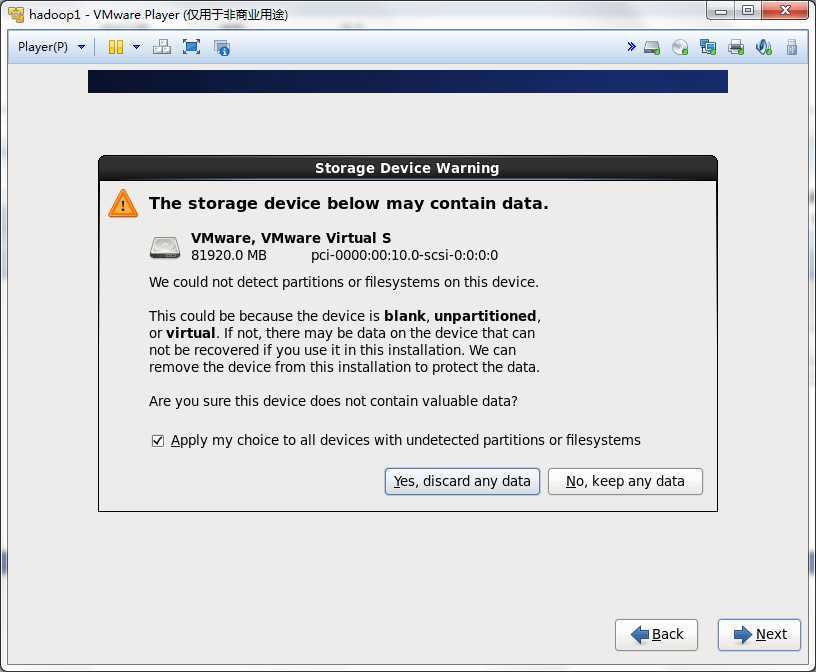
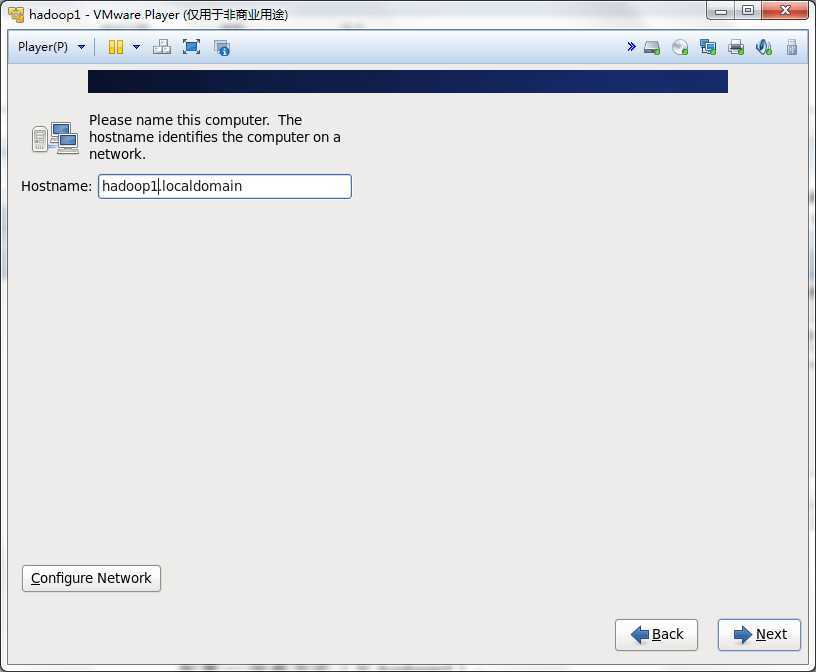
这一步一定要配置Configure Network,否则网卡就不会工作的
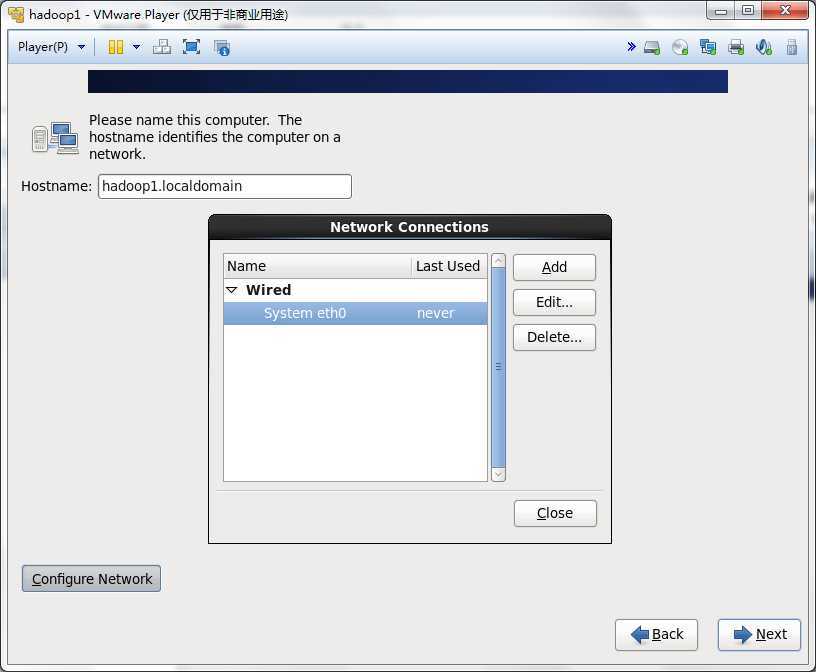
选中Connect automatically
如果密码过短或者比较简单,会出现下面的问题,不用管它,点击Use Anyway
一定要将变化写进磁盘,点击Write changes to disk
在Desktop, Mininal Desktop, Minimal, Basic Server, Database Server, Web Server, Virtual Host, Software Development Workstation 中,选择Minimal可以保证最清洁的hadoop集群。
然后启动安装过程,大约需要安装211个rpm包,安装过程大约5分钟
最后重启
按照上面的过程安装hadoop2和hadoop3
配置Centos系统
Selinux
将/etc/sysconfig/selinux 中的SELINUX置为disabled
SELINUX=disabled
Hosts文件
192.168.124.135 hadoop1.localdomain hadoop1
192.168.124.136 hadoop2.localdomain hadoop2
192.168.124.137 hadoop3.localdomain hadoop3
防火墙
Centos默认是开机启动防火墙,我们需要把它关闭,运行下面两个命令
service iptables stop
chkconfig iptables off
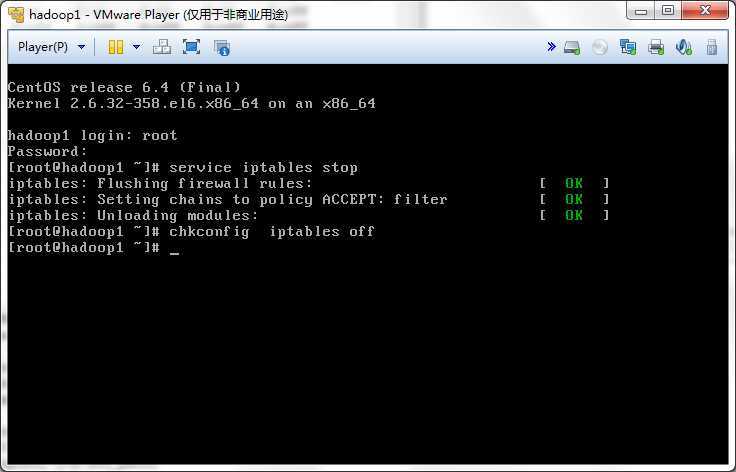
介绍一下防火墙的命令
启动/停止防火墙service iptables start/stop
开机启动/停止防火墙chkconfig iptables off/on
创建用户和组
创建组groupadd hadoop
创建用户useradd -g hadoop hadoop
切换用户su - hadoop
配置ssh
安装ssh客户端yum install openssh-clients
运行ssh-keygen -t rsa 生成一对公钥/私钥
然后在/home/hadoop/.ssh下,可以看到两个文件:id_rsa id_rsa.pub
cp .ssh/id_rsa.pub .ssh/authorized_keys
将hadoop2和hadoop3中的.ssh/id_rsa.pub文件内存添加到hadoop1中的.ssh/authorized_keys
然后通过下面两条命令,可以讲.ssh/authorized_keys复制到hadoop2和hadoop3上
scp .ssh/authorized_keys hadoop@hadoop2:/home/hadoop/.ssh/authorized_keys
scp .ssh/authorized_keys hadoop@hadoop2:/home/hadoop/.ssh/authorized_keys
这样,hadoop1,hadoop2,haoop3都可以用hadoop用户登录到其他机器,并且不需要密码。
测试是否登录成功
ssh hadoop2

安装 jdk和hadoop
使用FileZilla将jdk-6u32-linux-x64.bin和Hadoop-1.2.1上传到hadoop1,hadoop2,hadoop3
赋予jdk执行权限
chown a+x jdk-6u32-linux-x64.bin
运行安装./ jdk-6u32-linux-x64.bin
然后jdk就安装在/home/hadoop/jdk1.6.0_32目录下
测试一下jdk是否安装成功
/home/hadoop/jdk1.6.0_32/bin/java –version

hadoop的安装很简单,只需要解压压缩包即可
tar xzvf hadoop-1.2.1.tar.gz
配置hadoop-1.2.1
进入hadoop-1.2.1目录
cd hadoop-1.2.1
vi conf/hadoop-env.sh,修改jdk目录
export JAVA_HOME=/home/hadoop/jdk1.6.0_32
vi conf/core-site.xml,需要配置temp目录和hdfs地址
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/repo4/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:9000</value>
</property>
</configuration>
vi conf/hdfs-site.xml,需要配置name node,data node的目录,以及一个replication因子
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/repo4/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/repo4/data</value>
</property>
</configuration>
需要注意的是需要创建如下几个目录
Mkdir –p /home/hadoop/repo4/name
Mkdir –p /home/hadoop/repo4/data
Mkdir –p /home/hadoop/repo4/tmp

vi conf/mapred-site.xml,仅仅只需要配置jobtracker的地址
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://hadoop1:9001</value>
</property>
</configuration>
vi conf/masters
hadoop1
vi conf/slaves
hadoop1
hadoop2
hadoop3
将这些配置文件,复制到hadoop2和hadoop3上
cp -r conf/* hadoop@hadoop2:/home/hadoop/hadoop-1.2.1/conf/
cp -r conf/* hadoop@hadoop3:/home/hadoop/hadoop-1.2.1/conf/
在启动hadoop集群之前,需要格式化namenode
bin/hadoop namenode –format
启动hadoop集群
bin/start-all.sh

可以看出,先启动namenode, data, secondarynamenode, jobtracker, tasktracker
通过jps验证是否启动
在 hadoop1上, 运行jps
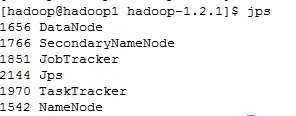
在hadoop2上,运行jps
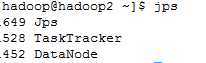
在hadoop3上,运行jps
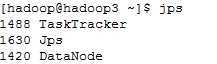
很显然,NameNode, DataNode, SecondaryNameNode, JobTracker, TaskTracker都已启动了
查看hadoop集群状态
bin/hadoop dfsadmin -report
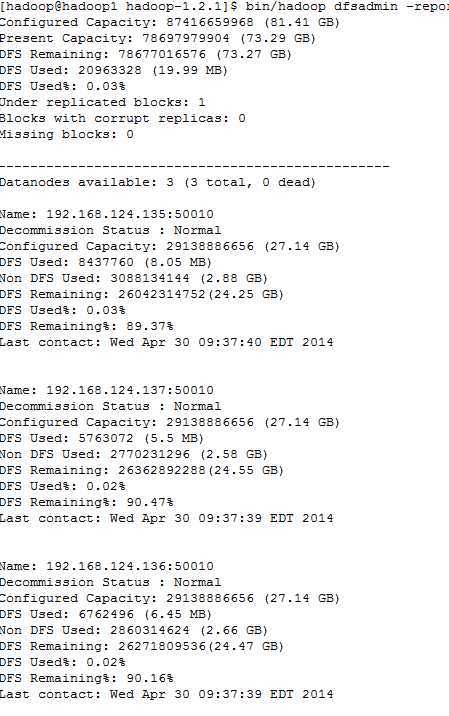
hadoop提供了web页面的接口
在浏览器里输入:http://hadoop1:50070
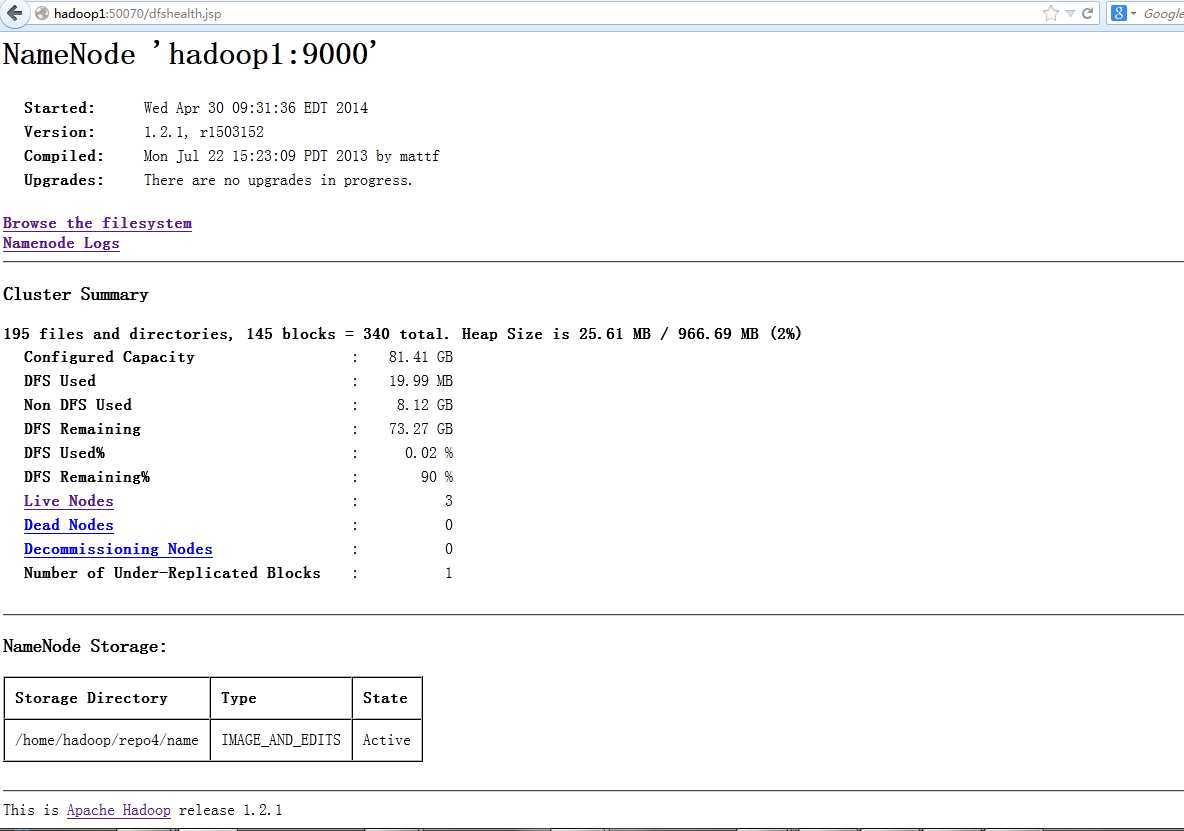
在浏览器里输入:http://hadoop1:50030
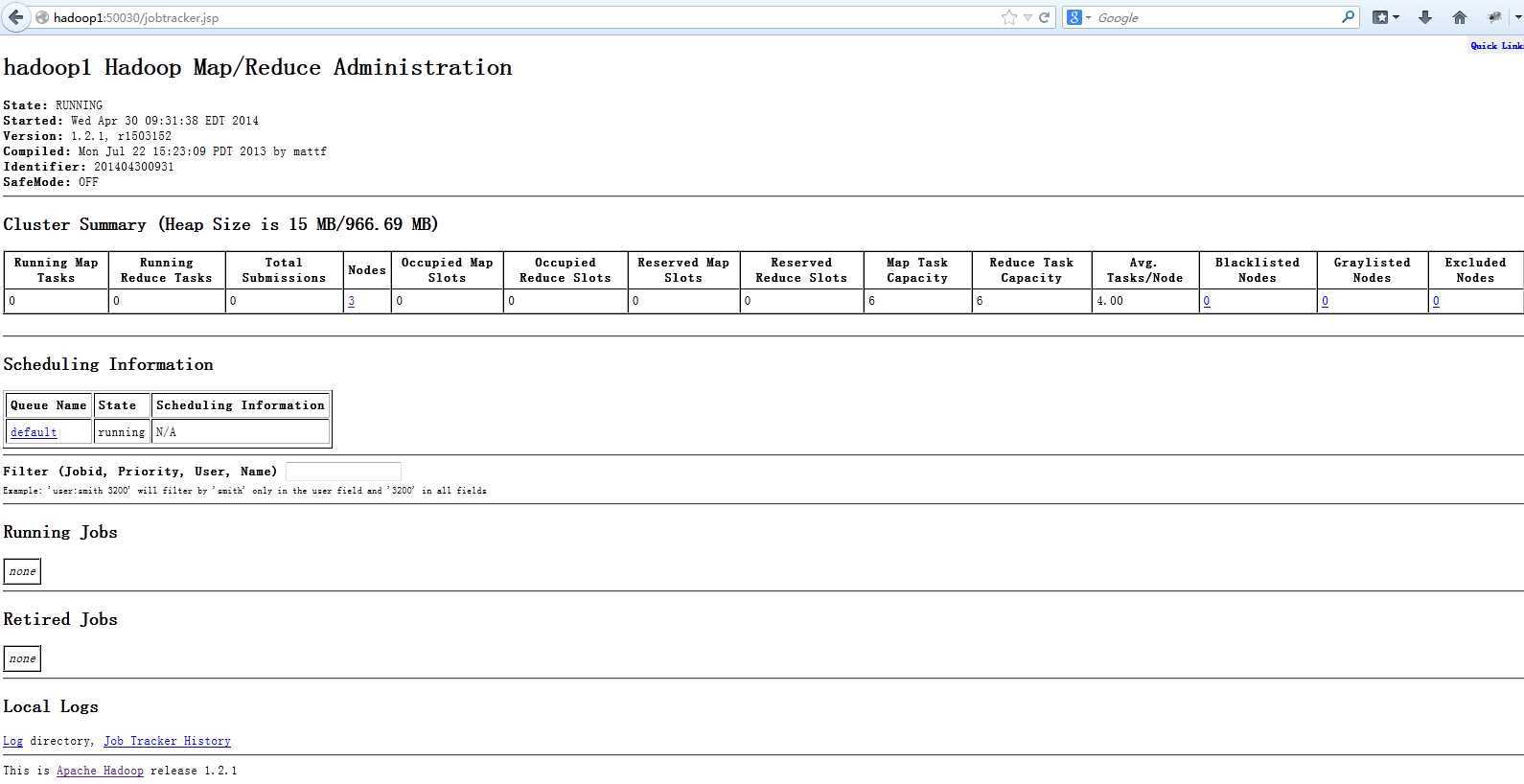
到目前为止hadoop的安装就结束了
测试一下mapred的程序,我们运行hadoop自带的wordcount
创建一个输入目录:
bin/hadoop dfs -mkdir /user/hadoop/input
上传一些文件
bin/hadoop dfs -copyFromLocal conf/* /user/hadoop/input/
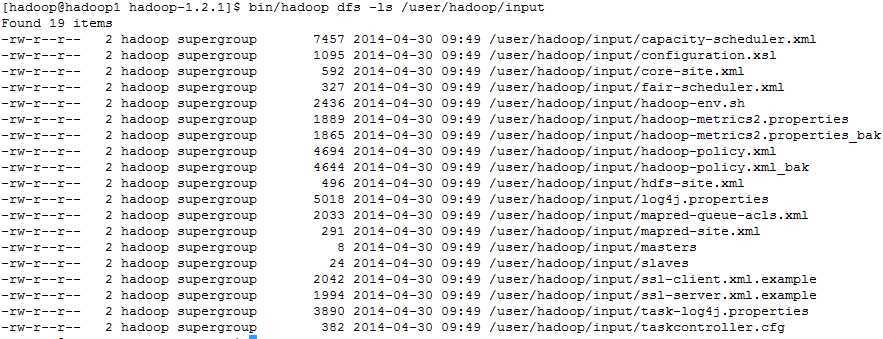
看一下文件
bin/hadoop dfs -ls /user/hadoop/input
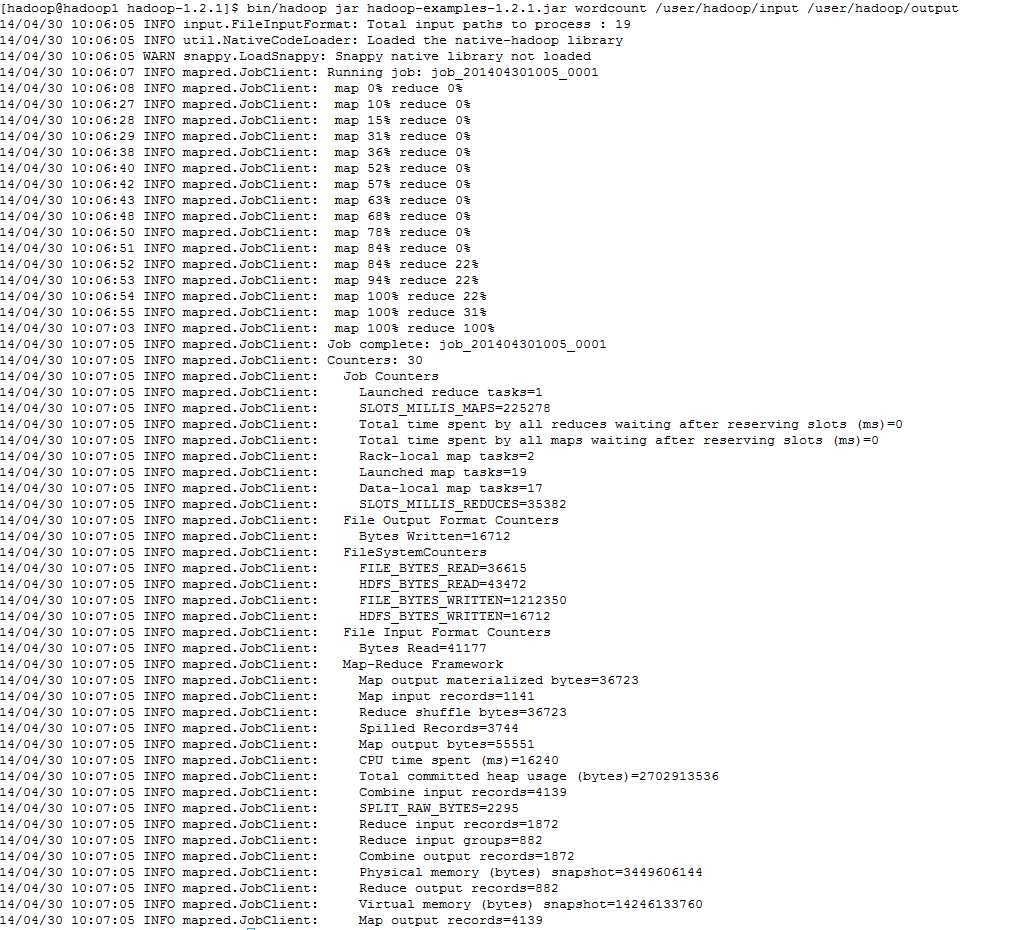
启动mapred程序
bin/hadoop jar hadoop-examples-1.2.1.jar wordcount /user/hadoop/input /user/hadoop/output
自此,hadoop-1.2.1已经成功安装了,hadoop安装的难点在于要非常熟悉linux系统,了解ssh的配置,防火墙,用户和组。希望大家都能安装好自己的hadoop系统。
原文地址:http://www.cnblogs.com/easycloud/p/3725053.html