标签:eof pointer ESS this == 源码 生产环境 rediscli poc
对于并发请求很高的生产环境,单个Redis满足不了性能要求,通常都会配置Redis集群来提高服务性能。3.0之后的Redis支持了集群模式。
Redis官方提供的集群功能是无中心的,命令请求可以发送到任意一个Redis节点,如果该请求的key不是由该节点负责处理,则会返回给客户端MOVED错误,提示客户端需要转向到该key对应的处理节点上。支持集群模式的redis客户端会自动进行转向,普通模式客户端则只返回MOVED错误。
先看下常见的Redis集群结构:
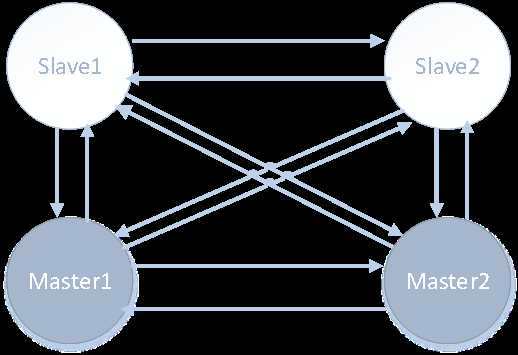
节点两两之间都有连接,只有主节点可以处理客户端的命令请求;从节点复制主节点数据,并在主节点下线后,升级为主节点。每个主节点可以挂多个从节点,在主节点下线后从节点需要竞争,只有一个从节点会被选举为主节点。
考虑以下几个关键点:
接下来几篇会从这几个关键问题入手来分析Redis集群源码;首先先看集群的基本数据结构,以及节点之间是如何建立连接的
Redis集群是无中心的,每个节点会存储整个集群各个节点的信息。我们看下Redis源码中存储集群节点信息的数据结构:
struct clusterNode { //clusterState->nodes结构 集群数据交互接收的地方在clusterProcessPacket mstime_t ctime; /* Node object creation time. */
char name[REDIS_CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */ int flags; /* REDIS_NODE_... */ //取值可以参考clusterGenNodeDescription uint64_t configEpoch; /* Last configEpoch observed for this node */ unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */ int numslots; /* Number of slots handled by this node */ int numslaves; /* Number of slave nodes, if this is a master */ struct clusterNode **slaves; /* pointers to slave nodes */ struct clusterNode *slaveof; /* pointer to the master node */ //注意ClusterNode.slaveof与clusterMsg.slaveof的关联 mstime_t ping_sent; /* Unix time we sent latest ping */ mstime_t pong_received; /* Unix time we received the pong */ mstime_t fail_time; /* Unix time when FAIL flag was set */ mstime_t voted_time; /* Last time we voted for a slave of this master */ mstime_t repl_offset_time; /* Unix time we received offset for this node */ long long repl_offset; /* Last known repl offset for this node. */ char ip[REDIS_IP_STR_LEN]; /* Latest known IP address of this node */ int port; /* Latest known port of this node */ A节点 B节点 clusterNode-B(link1) ---> link2(该link不属于任何clusterNode) (A发起meet到B) 步骤1 link4 <---- clusterNode-A(link3) (该link不属于任何clusterNode) (B收到meet后,再下一个clusterCron中向A发起连接) 步骤2 */ //clusterCron如果节点的link为NULL,则需要进行重连,在freeClusterLink中如果和集群中某个节点异常挂掉,则本节点通过读写事件而感知到,
//然后在freeClusterLink置为NULL clusterLink *link; /* TCP/IP link with this node */ //还有个赋值的地方在clusterCron,当主动和对端建立连接的时候赋值
list *fail_reports; /* List of nodes signaling this as failing */ //链表中成员类型为clusterNodeFailReport }; typedef struct clusterNode clusterNode;
clusterNode结构体存储了一个节点的基本信息,包括节点的IP,port,连接信息等;Redis节点每次和其他节点建立连接都会创建一个clusterNode用来记录其他节点的信息, 这些clusterNode都会存储到clusterState结构中,每个节点自身只拥有一个clusterState,用来存储整个集群系统的状态和信息。
typedef struct clusterState { //数据源头在server.cluster //集群相关配置加载在clusterLoadConfig clusterNode *myself; /* This node */ uint64_t currentEpoch; int state; /* REDIS_CLUSTER_OK, REDIS_CLUSTER_FAIL, ... */ int size; /* Num of master nodes with at least one slot */ //默认从1开始,而不是从0开始 dict *nodes; /* Hash table of name -> clusterNode structures */ ......
// 例如 slots[i] = clusterNode_A 表示槽 i 由节点 A 处理 clusterNode *slots[REDIS_CLUSTER_SLOTS];
zskiplist *slots_to_keys; /* The following fields are used to take the slave state on elections. */ ...... } clusterState;
clusterState结构中还有很多是故障迁移时需要用到的成员,与集群连接初始化关系不大,可以先不关注,后面再分析。nodes* 存储的就是本节点所知的集群所有节点的信息。
集群节点在初始化前都是孤立的Redis服务节点,还没有连成一个整体。其他节点的信息是如何被该节点获取的,整个集群是如何连接起来的呢?
这里有两种途径:
1)人为干预指定让节点和其他节点连接,也就是通过cluster meet命令来指定要连入的其他节点;
2)集群自发传播,靠集群内部的gossip协议自发扩散其他节点的信息。想象下如果没有集群内部的自发传播,任意两个节点间的连接都需要人为输入命令来建立;节点数如果为n, 整个集群建立的总连接数量会达到n*(n-1);要想建立起整个集群,让每个节点都知道完整的集群信息,需要的cluster meet指令数量是O(n2),节点多起来的话初始化的成本会很高。所以说内部自发的传播是很有必要的。
下面来看两种方式的源码实现:
Meet指令
CLUSTER MEET <ip> <port>
该指令会指定另一个节点的ip和port,让接收到MEET命令的Redis节点去和该ip和端口建立连接;
struct redisCommand redisCommandTable[] = { //sentinelcmds redisCommandTable 配置文件加载见loadServerConfigFromString 所有配置文件加载见loadServerConfigFromStringsentinel {"get",getCommand,2,"r",0,NULL,1,1,1,0,0}, {"set",setCommand,-3,"wm",0,NULL,1,1,1,0,0}, {"setnx",setnxCommand,3,"wm",0,NULL,1,1,1,0,0}, ...... {"cluster",clusterCommand,-2,"ar",0,NULL,0,0,0,0,0}, ...... }
可以看出Redis服务处理cluster meet指令的函数是clusterCommand。
//CLUSTER 命令的实现 void clusterCommand(redisClient *c) { // 不能在非集群模式下使用该命令 if (server.cluster_enabled == 0) { addReplyError(c,"This instance has cluster support disabled"); return; } if (!strcasecmp(c->argv[1]->ptr,"meet") && c->argc == 4) { /* CLUSTER MEET <ip> <port> */ // 将给定地址的节点添加到当前节点所处的集群里面 long long port; // 检查 port 参数的合法性 if (getLongLongFromObject(c->argv[3], &port) != REDIS_OK) { addReplyErrorFormat(c,"Invalid TCP port specified: %s", (char*)c->argv[3]->ptr); return; } //A通过cluster meet bip bport B后,B端在clusterAcceptHandler接收连接,A端通过clusterCommand->clusterStartHandshake连接服务器 // 尝试与给定地址的节点进行连接 if (clusterStartHandshake(c->argv[2]->ptr,port) == 0 && errno == EINVAL) { // 连接失败 addReplyErrorFormat(c,"Invalid node address specified: %s:%s", (char*)c->argv[2]->ptr, (char*)c->argv[3]->ptr); } else { // 连接成功 addReply(c,shared.ok); } ...... }
A节点收到cluster meet B指令后,A进入处理函数clusterCommand,并在该函数中调用clusterStartHandshake连接B服务器。这个函数实质上也只是创建一个记录了B节点信息的clusterNode(B),并将clusterNode(B)的link置为空。真正发起连接的是集群的时间事件处理函数clusterCron。clusterCron会遍历A节点上所有的nodes,并向link为空的节点发起连接。这里的连接又用到前面介绍的文件事件机制,不再赘述。
Gossip消息扩散
Gossip消息的扩散是利用节点之间的ping消息,在通过meet建立连接之后为了对节点在线状态进行检测,每个节点都要对自己已知集群节点发送ping消息,如果在超时时间内返回了pong则认为节点正常在线。
假定对于A、B、C三个节点,初始只向A节点发送了如下两条meet指令:
Cluster meet B
Cluster meet C
对于A来讲,B和C都是已知的节点信息;A会向B、C分别发送ping消息;在A发送ping消息给B时,发送方A会在gossip消息体中随机带上已知的节点信息(假设包含C节点);接收到ping消息的B节点会解析这gossip消息体中的节点信息,发现C节点是未知节点,那么就会向C节点进行握手,并建立连接。那么对B来讲,C也成为了已知节点。
看下接收gossip消息并处理未知节点的函数实现:
*/ //解释 MEET 、 PING 或 PONG 消息中和 gossip 协议有关的信息。 void clusterProcessGossipSection(clusterMsg *hdr, clusterLink *link) { // 记录这条消息中包含了多少个节点的信息 uint16_t count = ntohs(hdr->count); // 指向第一个节点的信息 clusterMsgDataGossip *g = (clusterMsgDataGossip*) hdr->data.ping.gossip; // 取出发送者 clusterNode *sender = link->node ? link->node : clusterLookupNode(hdr->sender); // 遍历所有节点的信息 while(count--) { sds ci = sdsempty(); // 分析节点的 flag uint16_t flags = ntohs(g->flags); // 信息节点 clusterNode *node; // 取出节点的 flag if (flags == 0) ci = sdscat(ci,"noflags,"); if (flags & REDIS_NODE_MYSELF) ci = sdscat(ci,"myself,"); if (flags & REDIS_NODE_MASTER) ci = sdscat(ci,"master,"); if (flags & REDIS_NODE_SLAVE) ci = sdscat(ci,"slave,"); if (flags & REDIS_NODE_PFAIL) ci = sdscat(ci,"fail?,"); if (flags & REDIS_NODE_FAIL) ci = sdscat(ci,"fail,"); if (flags & REDIS_NODE_HANDSHAKE) ci = sdscat(ci,"handshake,"); if (flags & REDIS_NODE_NOADDR) ci = sdscat(ci,"noaddr,"); if (ci[sdslen(ci)-1] == ‘,‘) ci[sdslen(ci)-1] = ‘ ‘; redisLog(REDIS_DEBUG,"GOSSIP %.40s %s:%d %s", g->nodename, g->ip, ntohs(g->port), ci); sdsfree(ci); /* Update our state accordingly to the gossip sections */ // 使用消息中的信息对节点进行更新 node = clusterLookupNode(g->nodename); // 节点已经存在于当前节点 if (node) { /* We already know this node. Handle failure reports, only when the sender is a master. */ if (sender && nodeIsMaster(sender) && node != myself) { if (flags & (REDIS_NODE_FAIL|REDIS_NODE_PFAIL)) {//发送端每隔1s会从集群挑选一个节点来发送PING,参考CLUSTERMSG_TYPE_PING // 添加 sender 对 node 的下线报告 if (clusterNodeAddFailureReport(node,sender)) { //clusterProcessGossipSection->clusterNodeAddFailureReport把接收的fail或者pfail添加到本地fail_reports redisLog(REDIS_VERBOSE, "Node %.40s reported node %.40s as not reachable.", sender->name, node->name); //sender节点告诉本节点node节点异常了 } // 尝试将 node 标记为 FAIL markNodeAsFailingIfNeeded(node); // 节点处于正常状态 } else { // 如果 sender 曾经发送过对 node 的下线报告 // 那么清除该报告 if (clusterNodeDelFailureReport(node,sender)) { redisLog(REDIS_VERBOSE, "Node %.40s reported node %.40s is back online.", sender->name, node->name); } } } /* If we already know this node, but it is not reachable, and * we see a different address in the gossip section, start an * handshake with the (possibly) new address: this will result * into a node address update if the handshake will be * successful. */ // 如果节点之前处于 PFAIL 或者 FAIL 状态 // 并且该节点的 IP 或者端口号已经发生变化 // 那么可能是节点换了新地址,尝试对它进行握手 if (node->flags & (REDIS_NODE_FAIL|REDIS_NODE_PFAIL) && (strcasecmp(node->ip,g->ip) || node->port != ntohs(g->port))) { clusterStartHandshake(g->ip,ntohs(g->port)); } // 当前节点不认识 node } else { if (sender && !(flags & REDIS_NODE_NOADDR) && !clusterBlacklistExists(g->nodename)) //如果本节点通过cluster forget把某个节点删除本节点集群的话,那么这个被删的节点需要等黑名单过期后本节点才能发送handshark { clusterStartHandshake(g->ip,ntohs(g->port)); //这样本地就会创建这个不存在的node节点了,本地也就有了sender里面有,本地没有的节点了 } } /* Next node */ // 处理下个节点的信息 g++; } }
Gossip协议的原理通俗来讲就是一传十,十传百;互相之间传递集群节点信息,最终可以达到系统中所有节点都能获取到完整的集群节点。在ping消息中附加集群节点信息,带来的额外负担就是每次接收到ping消息都要预先遍历下gossip消息中所有节点信息,并判断是否有包含自身未知的节点,还要建立连接。为了减轻接收方的负担,gossip消息可以不附带所有节点信息,附带随机节点也可以最终达到所有节点都去到完整集群信息的目的。
标签:eof pointer ESS this == 源码 生产环境 rediscli poc
原文地址:https://www.cnblogs.com/gogoCome/p/9563491.html