标签:style blog http ar sp 2014 问题 c on
考虑一个分类问题:
根据一个动物的特征来区分该动物是大象(y=1)还是狗(y = 0).利用逻辑回归找到一条直线,即分界线,将训练集中的大象和狗分开,当给定一个新的动物特征时,检查该动物位于分界线的哪一边,然后做出判断是大象,还是狗,就是对p(y|x;θ)进行建模。
这里我们来看另一种不同的思路,首先根据训练集,我们找出大象有什么特征,然后找出狗有什么特征,当要对一个新的动物进行分类的时候,我们就对比该动物是与大象的特征更加匹配还是与狗的特征更加匹配,从而进行分类。
直接学习p(y|x)的算法是直接把特征x映射到类别{0,1},被称为判别式学习算法(discriminative learning algorithms).这里,我们将要讨论另外一种学习算法:生成式学习算法(generative learning algorithms).例如,如果y表示某一个样本是狗(y=0)还是大象(y=1),那么p(x|y=0)就是狗的特征分布,p(x|y=1)表示大象的特征分布。
在我们知道p(y)(这个值可以根据训练集中各个类别的多少容易统计出来),并且对p(x|y)建模后,利用贝叶斯规则,就可以得到在给出x时y的后验分布:
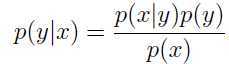
分母p(x) = p(x|y=1)p(y=1)+p(x|y=0)p(y=0).
1.高斯判别分析(Gaussian discriminant analysis,GDA)
用多元正态分布对p(x|y)进行建模:
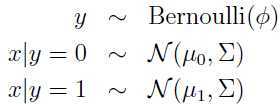
其中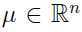 是均值向量,
是均值向量,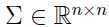 是协方差矩阵,y不是0就是1,显然服从伯努利(Bernoulli)分布.
是协方差矩阵,y不是0就是1,显然服从伯努利(Bernoulli)分布.
把上面的表达式展开写:
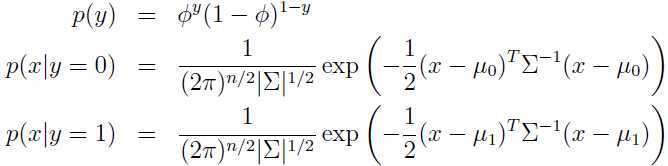
这个模型的参数有: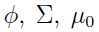 和
和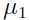 ,于是参数的对数似然函数:
,于是参数的对数似然函数:
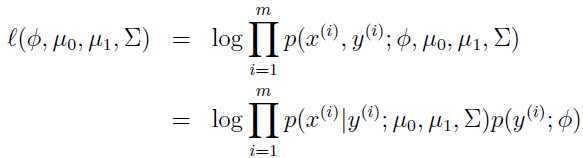
通过对上述对数似然函数进行最大化(通过程序,逐步迭代),可以得出各个参数的最大似然评估(下面是理论上数学计算出的具有最大似然性的参数值):
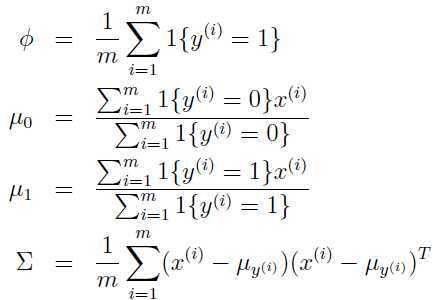
2. GDA和逻辑回归
如果我们把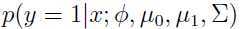 看作是关于
看作是关于 的函数,则可以发现下面有趣的现象:
的函数,则可以发现下面有趣的现象:
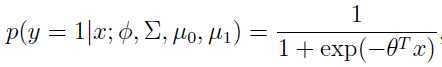
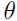 是关于
是关于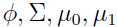 的函数,等式右边正是逻辑回归的模型——一种判别式算法,用来建模p(y=1|x).
的函数,等式右边正是逻辑回归的模型——一种判别式算法,用来建模p(y=1|x).
但是哪一个模型更好呢?GDA还是逻辑回归?由上面的等式可以看出,如果p(x|y)是多元的高斯分布,可以得出p(y|x)必然就是一种逻辑函数,但是反过来说就不对了。
也就是说GDA比逻辑回归对模型的假设更强。事实证明,当我们的假设正确(就是假设p(x|y)服从高斯分布)的时候,没有那个算法在严格意义上比GDA好(即准确地估计出p(y|x)).
但需要注意的是,GDA好的前提是假设正确(假设p(x|y)服从高斯分布),即GDA作为一个强假设模型,它对假设的正确与否很敏感,当假设不正确的时候,结果往往很糟糕。
而逻辑回归作为一个弱假设,对假设的正确与否没有强假设那么敏感,即使假设不正确,逻辑回归的同样可以做出不错的预测。正是由于这个原因,在实践中,逻辑回归要比GDA用的更加
频繁。
标签:style blog http ar sp 2014 问题 c on
原文地址:http://www.cnblogs.com/90zeng/p/generative_learning_algorithms.html