标签:timestamp ORC rdbms 初始 binder list postget yarn dmi
把一部分计算移动到数据的存放端。
协处理器允许用户在region服务器上运行自己的代码,允许用户执行region级别的操作,并且可以使用与RDBMS中触发器(trigger)类似的功能。在客户端,用户不用关心操作具体在哪里执行,HBase的分布式框架会帮助用户把这些工作变得透明。
协处理器框架提供了一些类,用户可以通过继承这些类来扩展自己的功能。主要分为以下两大类
observer
这一类协处理器与触发器(trigger)类似:回调函数(也被称作钩子函数,hook)在一些特定事件发生时被执行。这些事件包括一些用户产生的事件,也包括服务器端内部自动产生的事件。
协处理器框架提供的接口如下
RegionObserver:用户可以用这种的处理器处理数据修改事件,它们与表的region联系紧密。
MasterObserver:可以被用作管理或DDL类型的操作,这些是集群级事件。
WALObserver:提供控制WAL的钩子函数
Observer提供了一些设计好的回调函数,每个操作在集群服务器端都可以被调用。
endpoint
除了事件处理之外还需要将用户自定义操作添加到服务器端。用户代码可以被部署到管理数据的服务器端,例如,做一些服务器端计算的工作。
Endpoint通过添加一下远程过程调用来动态扩展RPC协议。可以把它们理解为与RDBMS中类似的存储过程。Endpoint可以与observer的实现组合起来直接作用于服务器端的状态。
所有协处理器的类都必须实现这个接口。它定义了协处理器的基本约定,并使得框架本身的管理变得容易。
Coprocessor.Priority枚举类定义的优先级
SYSTEM:高优先级,定义最先被执行的协处理器
USER:定义其他的协处理器,按顺序执行
协处理器的优先级决定了执行的顺序:系统(SYSTEM)级协处理器在用户(USER)级协处理器之前执行。
在同一个优先级中还有一个序号(sequence number)的概念,用来维护协处理器的加载顺序。序号从0开始依次增加。
这个数字的作用并不大,但用户可以依靠它们来为同一优先级的协处理器排序:在同一优先级下,它们按照其序号递增的顺序执行,即定义了执行顺序。
在协处理器生命周期中,它们由框架管理。Coprocessor接口提供了以下两个方法
void start(CoprocessorEnvironment env) throws IOException; void stop(CoprocessorEnvironment env) throws IOException;
这两个方法在协处理器开始和结束时被调用。CoprocessorEnvironment用来在协处理器的生命周期中保持其状态。协处理器实例一直被保存在提供的环境中。
CoprocessorEnvironment类提供的方法
|
int getVersion(); |
返回Coprocessor版本 |
|
String getHBaseVersion(); |
以字符串的格式返回HBase版本 |
|
Coprocessor getInstance(); |
返回加载的协处理器实例 |
|
int getPriority(); |
返回协处理器的优先级 |
|
int getLoadSequence(); |
协处理器的序号,当协处理器加载时被设置,这反映了它的执行顺序 |
协处理器应当只与提供给它们的环境进行交互。这样的好处是可以保证没有会被恶意代码用来破坏数据的后门。
注意:协处理器应当使用getTable方法访问表数据。注意这个方法实际上在默认的HTable类上添加了特定的安全措施。例如,协处理器不可以对一行数据加锁。
在协处理器实例的生命周期中,Coprocessor接口的start和stop方法会被框架隐式调用,处理过程中的每一步都有一个状态。
Coprocessor.State枚举类定义的状态
|
UNINSTALLED |
协处理器最初的状态,没有环境,也没有被初始化 |
|
INSTALLED |
实例装载了它的环境参数 |
|
STARTING |
协处理器将要开始工作,也就是说start方法将要被调用 |
|
ACTIVE |
一旦start方法被调用,当前状态设置为active |
|
STOPPING |
Stop方法被调用之前的状态 |
|
STOPPED |
一旦stop方法将控制权 交给框架,协处理器会被设置为状态stopped |
CoprocessorHost类,它维护所有协处理器实例和它们专用的环境。它有一些子类,这些子类应用在不同的使用环境,例如,master和region服务器等环境
Coprocessor、CoprocessorEnvironment和CoprocessorHost这3个类形成了协处理器类的基础,基于这三个类能够实现更高级的功能。它们支持协处理器的生命周期,管理协处理器的状态,同时提供了执行时的环境参数,以保证协处理器正确执行。此外,这些类也提供了一个抽象层方便用户更简单的构建自己的实现。
客户端的调用与一系列的协处理器进行交互
需要将协处理器jar包放入HBASE_CLASSPATH指定的路径下
在hbase-site.xml中配置,会对所有的表都加上
<property>
<name>hbase.coprocessor.region.classes</name>
<value>class1,class2</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>class1,class2</value>
</property>
<property>
<name>hbase.coprocessor.wal.classes</name>
<value>class1,class2</value>
</property>
配置完成后重启HBase.
配置文件中配置项的顺序决定了执行顺序。所有协处理器都是以系统级优先级进行加载的。
配置文件首先在HBase启动时被检查。虽然还可以在其他地方增加系统级优先级的协处理器,但是在配置文件中配置的协处理器是被最先执行的。
针对特定表,所以加载的协处理器只针对这个表的region,同时也只被这些region的region服务器使用。换句话说,用户只能在与region相关的协处理器上使用这种方法,而不能在master或WAL相关的协处理器上使用。
由于它们是使用表的上下文加载的,所以与配置文件中加载的协处理器影响所有表相比,这种方法加载的协处理器更具有针对性。用户需要在表描述符中利用HTableDescription.setValue方法定义它们。键必须以COPROCESSOR开头,值必须符合以下格式
<path-to-jar>|<classname>|<priority>
如下,一个使用系统优先级,一个使用用户优先级
alter ‘socialSecurityTest‘,METHOD=>‘table_att‘,‘coprocessor‘=>‘hdfs://cluster1/user/solr/hbase/observer/HBaseCoprocessor.jar|com.hbase.coprocessor.HbaseDataSyncSolrObserver|SYSTEM‘ alter ‘socialSecurityTest‘,METHOD=>‘table_att‘,‘coprocessor‘=>‘ /user/solr/hbase/observer/HBaseCoprocessor.jar|com.hbase.coprocessor.HbaseDataSyncSolrObserver|USER
path-to-jar可以是一个完整的HDFS地址或其他Hadoop FileSystem类支持的地址。第二个协处理器使用了本地路径。
Classname定义了具体的实现类。由于JAR可能包含许多协处理器类,但只能给一张表设定一个协处理器。用户应该使用标准的java包命名规则来命名指定类。
Priority只能是SYSTEM或USER
注意:不要在协处理器定义中添加空格。解释十分严格,添加头尾或间隔字符会使整个配置条目无效。
使用${number}后缀可以改变定义中的顺序,即协处理器的加载顺序。虽然只有COPROCESSOR的前缀会被检查,但是还是推荐使用数字后缀定义顺序。
package com.hbase.coprocessor;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.Coprocessor;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.TableNotFoundException;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.log4j.Logger;
/**
* @author:FengZhen
* @create:2018年8月30日
* 协处理器
*/
public class CoprocessorCreateTest {
private static String addr="HDP233,HDP232,HDP231";
private static String port="2181";
Logger logger = Logger.getLogger(getClass());
private static Connection connection;
public static void getConnection(){
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum",addr);
conf.set("hbase.zookeeper.property.clientPort", port);
try {
connection = ConnectionFactory.createConnection(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
/*
* 关闭连接
*
*/
public static void close() {
/**
* close connection
**/
if (connection != null) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
getConnection();
try {
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("test_hbase"));
Path path = new Path("/user/hdfs/coprocessor/test.jar");
hTableDescriptor.setValue("COPROCESSOR", path.toString() + "|" + "class" + "|" + Coprocessor.PRIORITY_SYSTEM);
Admin admin = connection.getAdmin();
admin.createTable(hTableDescriptor);
} catch (TableNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
close();
}
}
一旦表被启用,且region被打开,框架会首先加载配置文件中定义的协处理器,然后再加载表描述符中的协处理器。
属于observer协处理器:当一个特定的region级别的操作发生时,它们的钩子函数会被触发。
这些操作可以被分为两类:region生命周期变化和客户端API调用。
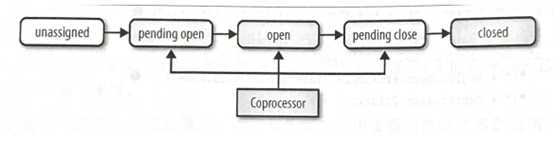
这些observer可以与pending open、open和pending close状态通过钩子链接。每一个钩子都被框架隐式地调用。
状态:pending open。Region将要被打开时会处于这个状态。监听的协处理器可以搭载这个过程或阻止这个过程。
void preOpen(final ObserverContext<RegionCoprocessorEnvironment> c) throws IOException; void postOpen(final ObserverContext<RegionCoprocessorEnvironment> c);
这些方法会在region被打开前或刚刚打开后被调用。用户可以在自己的协处理器实现中使用这两个方法,例如,使用preOpen方法告知框架这次打开操作应当被放弃,或勾住postOpen方法来触发一次缓存预热或其它一些操作。
Region经过pending open,且在打开状态之前,region服务器可能需要从WAL(Write-Ahead-logging,预写系统日志)中应用一些记录到region中,这时会触发以下方法。
void preWALRestore(final ObserverContext<? extends RegionCoprocessorEnvironment> ctx,
HRegionInfo info, WALKey logKey, WALEdit logEdit) throws IOException;
void postWALRestore(final ObserverContext<? extends RegionCoprocessorEnvironment> ctx,
HRegionInfo info, WALKey logKey, WALEdit logEdit) throws IOException;
这些方法让用户可以细粒度地控制在WAL重做时那些修改需要被实施。用户可以访问修改记录,因此用户就可以监督那些记录被实施了。
状态:open。当一个region被部署到一个region服务器中,并可以正常工作时,这个region会被认为处于open状态。
可用的钩子函数如下
InternalScanner preFlush(final ObserverContext<RegionCoprocessorEnvironment> c, final Store store,
final InternalScanner scanner) throws IOException;
void postFlush(final ObserverContext<RegionCoprocessorEnvironment> c, final Store store,
final StoreFile resultFile) throws IOException;
InternalScanner preCompact(final ObserverContext<RegionCoprocessorEnvironment> c,
final Store store, final InternalScanner scanner, final ScanType scanType,
CompactionRequest request) throws IOException;
void postCompact(final ObserverContext<RegionCoprocessorEnvironment> c, final Store store,
StoreFile resultFile, CompactionRequest request) throws IOException;
void preSplit(final ObserverContext<RegionCoprocessorEnvironment> c, byte[] splitRow)
throws IOException;
void preSplit(final ObserverContext<RegionCoprocessorEnvironment> c, byte[] splitRow)
throws IOException;
pre方法在事件执行前被调用,post方法在事件执行后被调用。例如:使用preSplit钩子函数可以有效地禁止region拆分,然后手动执行这些操作。
状态:pending close。最后一组region监听器的钩子函数可以监听pending close状态。这个状态在region状态从open到closed转变时发生。在region被关闭之前和之后,一下钩子函数将被执行。
void preClose(final ObserverContext<RegionCoprocessorEnvironment> c,
boolean abortRequested) throws IOException;
void postClose(final ObserverContext<RegionCoprocessorEnvironment> c,
boolean abortRequested);
abortRequested参数包含了region被关闭的原因。通常情况下,region会在正常操作中被关闭,例如,region由于负载均衡被移动到其它region服务器时被关闭。也有可能是由于region服务器被撤销,且需避免一些副作用。当这些情况发生时,所有它管理的region都会被撤销,同时用户从这个参数中可以看到是否符合这种情况。
与生命周期事件相比,所有的客户端API调用都显示地从客户端应用中传输到region服务器。用户可以在这些调用执行前或刚刚执行后拦截它们。
|
void preGet() void postGet() |
在客户端Table.get请求之前和之后调用 |
|
void prePut() void postPut() |
在客户端Table.put请求之前和之后调用 |
|
void preDelete() void postDelete () |
在客户端Table.delete请求之前和之后调用 |
|
boolean preCheckAndPut() boolean postCheckAndPut () |
在客户端Table. checkAndPut请求之前和之后调用 |
|
boolean preCheckAndDelete() boolean postCheckAndDelete () |
在客户端Table. checkAndDelete请求之前和之后调用 |
|
void preGetClosestRowBefore() void postGetClosestRowBefore () |
在客户端Table.getClosestRowBefore请求之前和之后调用 |
|
boolean preExists() boolean postExists () |
在客户端Table.exists请求之前和之后调用 |
|
long preIncrementColumnValue() long postIncrementColumnValue () |
在客户端Table.incrementColumnValue请求之前和之后调用 |
|
void preIncrement() void postIncrement () |
在客户端Table. increment请求之前和之后调用 |
|
InternalScanner preScannerOpen() InternalScanner postScannerOpen () |
在客户端Table.getScannerOpen请求之前和之后调用 |
|
boolean preScannerNext() void postScannerNext () |
在客户端ResultScanner.next请求之前和之后调用 |
|
void preScannerClose() void postScannerClose () |
在客户端ResultScanner.close请求之前和之后调用 |
实现RegionObserver类的协处理器环境的实例是基于RegionCoprocessorEnvironment类的,RegionCoprocessorEnvironment实现了CoprocessorEnvironment接口。
RegionCoprocessorEnvironment类提供的方法及子类方法
|
Region getRegion(); |
返回监听器监听的region的应用 |
|
RegionServerServices getRegionServerServices(); |
返回共享的RegionServerServices实例 |
getRegion方法可以用于得到目前正在管理的HRegion实例,同时可以执行这个类提供的方法。
RegionServerServices类提供的方法
|
boolean isStopping(); |
当region服务正在停止服务时,返回true |
|
WAL getWAL(HRegionInfo regionInfo) throws IOException; |
提供访问WAL实例的功能 |
|
CompactionRequestor getCompactionRequester(); |
提供访问共享的CompactionRequestor实例的功能,可以在协处理器内部发起合并 |
|
FlushRequester getFlushRequester(); |
提供访问共享的FlushRequester,可以用于发起memstore刷写 |
|
RegionServerAccounting getRegionServerAccounting(); |
提供访问共享RegionServerAccounting实例的功能。用户可以利用它得到当前服务进程资源的占用状态,例如当前memstore的大小 |
|
void postOpenDeployTasks(final PostOpenDeployContext context) throws KeeperException, IOException; |
内部调用,在region服务器内部使用 |
|
RpcServerInterface getRpcServer(); |
提供访问共享RpcServerInterface实例的功能,包含当前服务端RPC统计信息 |
RegionObserver类提供的所有回调函数都需要一个特殊的上下文作为共同的参数: ObserverContext类,它不仅提供了访问当前系统环境的入口,同时也添加了一些关键功能用以通知协处理器框架在回调函数完成时需要做什么。
所有的协处理器在执行时共用一个上下文实例,并会随着环境一起变化。
ObserverContext类提供的方法
|
E getEnvironment() |
返回当前协处理器环境的应用 |
|
void bypass() |
当用户代码调用此方法时,框架将使用用户提供的值,而不使用框架通常使用的值 |
|
void complete() |
通知框架后续的处理可以被跳过,剩下没有被执行的协处理器也会被跳过。这意味着当前协处理器的响应是最后的一个协处理器 |
|
boolean shouldBypass() |
框架内部用来检查标志位 |
|
boolean shouldComplete() |
框架内部用来检查标志位 |
|
void prepare(E env) |
使用特定的环境准备上下文。这个方法只供内部使用。它被静态方法createAndPrepare使用 |
|
static <T extends CoprocessorEnvironment> ObserverContext<T> createAndPrepare( |
初始化上下文的静态方法。当提供的context参数是null时,它会创建一个新实例 |
两个重要的方法是bypass和complete。它们会为用户的协处理器实现提供了选择,以控制框架后续行为。Complete的调用会影响后面执行的协处理器,同时bypass方法可以停止当前服务进程的处理过程。例如,可以使用e.bypass停止region的自动拆分。
public void preSplit(ObserverContext<RegionCoprocessorEnvironment> e) throws IOException {
e.bypass();
}
这个类可以作为所有用户实现监听类型协处理器的基类。它实现了所有RegionObserver接口的空方法,所以在默认情况下继承这个类的协处理器没有任何功能。
示例,协处理器代码去下
package com.hbase.coprocessor;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.util.Bytes;
/**
* @author:FengZhen
* @create:2018年8月31日
*/
public class RegionObserverExample extends BaseRegionObserver{
public static final byte[] FIXED_ROW = Bytes.toBytes("@@@GETTIME@@@");
@Override
public void preGetOp(ObserverContext<RegionCoprocessorEnvironment> e, Get get, List<Cell> results)
throws IOException {
//检查请求的行键是否匹配
if (Bytes.equals(get.getRow(), FIXED_ROW)) {
//创建一个特殊的keyvalue,只包含当前的服务器时间。
KeyValue keyValue = new KeyValue(get.getRow(), FIXED_ROW, FIXED_ROW, Bytes.toBytes(System.currentTimeMillis()));
results.add(keyValue);
}
}
}
create ‘test_coprocessor‘, ‘info‘
上传至HDFS
/data/fz/hbase/coprocessor/RegionObserverExample.jar
hbase(main):004:0> disable ‘test_coprocessor‘ hbase(main):006:0> alter ‘test_coprocessor‘,METHOD=>‘table_att‘,‘COPROCESSOR‘=>‘hdfs://cluster1/data/fz/hbase/coprocessor/RegionObserverExample.jar|com.hbase.coprocessor.RegionObserverExample|1001‘ hbase(main):007:0> enable ‘test_coprocessor‘
hbase(main):009:0> desc ‘test_coprocessor‘
Table test_coprocessor is ENABLED
test_coprocessor, {TABLE_ATTRIBUTES => {METADATA => {‘COPROCESSOR$1‘ => ‘hdfs://cluster1/data/fz/hbase/coprocessor/RegionObserverExample.jar|com.hbase.coprocess
or.RegionObserverExample|1001‘}}
COLUMN FAMILIES DESCRIPTION
{NAME => ‘info‘, BLOOMFILTER => ‘ROW‘, VERSIONS => ‘1‘, IN_MEMORY => ‘false‘, KEEP_DELETED_CELLS => ‘FALSE‘, DATA_BLOCK_ENCODING => ‘NONE‘, TTL => ‘FOREVER‘,
COMPRESSION => ‘NONE‘, MIN_VERSIONS => ‘0‘, BLOCKCACHE => ‘true‘, BLOCKSIZE => ‘65536‘, REPLICATION_SCOPE => ‘0‘}
行键@@@GETTIME@@@被observer的preGet捕获,然后添加当前服务器时间。
如下
hbase(main):054:0> get ‘test_coprocessor‘,‘@@@GETTIME@@@‘ COLUMN CELL @@@GETTIME@@@:@@@GETTIME@@@ timestamp=9223372036854775807, value=\x00\x00\x01e\x8E\xC6ad 1 row(s) in 0.0450 seconds
插入一条行键为@@@GETTIME@@@的数据
hbase(main):055:0> put ‘test_coprocessor‘,‘@@@GETTIME@@@‘,‘info:name‘,‘nimei‘ 0 row(s) in 0.0540 seconds
此时再次使用get
hbase(main):057:0> get ‘test_coprocessor‘,‘@@@GETTIME@@@‘ COLUMN CELL @@@GETTIME@@@:@@@GETTIME@@@ timestamp=9223372036854775807, value=\x00\x00\x01e\x8E\xC7\xD3\x9B info:name timestamp=1535698764962, value=nimei 2 row(s) in 0.0130 seconds
如果捕获的该行键恰巧在表中同时存在,就会出现上面的情况,为了避免这种情况,可以使用e.bypass。更新步骤如下
alter ‘test_coprocessor‘,METHOD => ‘table_att_unset‘,NAME =>‘COPROCESSOR$1‘
代码如下
package com.hbase.coprocessor;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.util.Bytes;
/**
* @author:FengZhen
* @create:2018年8月31日
*/
public class RegionObserverWithBypassExample extends BaseRegionObserver{
public static final byte[] FIXED_ROW = Bytes.toBytes("@@@GETTIME@@@");
@Override
public void preGetOp(ObserverContext<RegionCoprocessorEnvironment> e, Get get, List<Cell> results)
throws IOException {
//检查请求的行键是否匹配
if (Bytes.equals(get.getRow(), FIXED_ROW)) {
//创建一个特殊的keyvalue,只包含当前的服务器时间。
KeyValue keyValue = new KeyValue(get.getRow(), FIXED_ROW, FIXED_ROW, Bytes.toBytes(System.currentTimeMillis()));
results.add(keyValue);
//一旦特殊的keyvalue被添加,之后的操作都会被跳过
e.bypass();
}
}
}
disable ‘test_coprocessor‘ hbase(main):034:0> alter ‘test_coprocessor‘,METHOD=>‘table_att‘,‘COPROCESSOR‘=>‘hdfs://cluster1/data/fz/hbase/coprocessor/RegionObserverWithBypassExample.jar|com.hbase.coprocessor.RegionObserverWithBypassExample|1001‘ enable ‘test_coprocessor‘
hbase(main):036:0> desc ‘test_coprocessor‘
Table test_coprocessor is ENABLED
test_coprocessor, {TABLE_ATTRIBUTES => {METADATA => {‘COPROCESSOR$1‘ => ‘hdfs://cluster1/data/fz/hbase/coprocessor/RegionObserverWithBypassExample.jar|com.hbase.c
oprocessor.RegionObserverWithBypassExample|1001‘}}
COLUMN FAMILIES DESCRIPTION
{NAME => ‘info‘, BLOOMFILTER => ‘ROW‘, VERSIONS => ‘1‘, IN_MEMORY => ‘false‘, KEEP_DELETED_CELLS => ‘FALSE‘, DATA_BLOCK_ENCODING => ‘NONE‘, TTL => ‘FOREVER‘,
COMPRESSION => ‘NONE‘, MIN_VERSIONS => ‘0‘, BLOCKCACHE => ‘true‘, BLOCKSIZE => ‘65536‘, REPLICATION_SCOPE => ‘0‘}
1 row(s) in 0.0160 seconds
hbase(main):037:0> get ‘test_coprocessor‘,‘@@@GETTIME@@@‘ COLUMN CELL @@@GETTIME@@@:@@@GETTIME@@@ timestamp=9223372036854775807, value=\x00\x00\x01e\x8E\xDA\xDB\xC5 1 row(s) in 0.0210 seconds
成功。
由于默认的get操作被跳过,只有人工添加的一列被返回,并且是返回的唯一一列数据。可以注意到返回列的时间戳是9223372036854775807,这个只是Long.MAX_VALUE预计得到的值。因为示例代码创建keyvalue时并没有指定时间戳,所以被默认设为HConstants.LATEST_TIMESTAMP,即Long.MAX_VALUE..
为了处理master服务器的所有回调函数。与关系型数据库中DDL类似,它们可以被归类到数据处理操作中。
MasterCoprocessorEnvironment封装了一个MasterObserver实例,它同样实现了CoprocessorEnvironment接口,因此它能提供getTable之类的方法帮助用户在自己的实现中访问数据。
MasterCoprocessorEnvironment类提供的非继承方法
MasterServices getMasterServices();提供可访问的共享MasterServices实例
MasterServices类提供的方法
|
AssignmentManager getAssignmentManager(); |
使用户可以访问AssignmentManager实例,它负责为所有的region分操作,例如分配、卸载和负载均衡等 |
|
MasterFileSystem getMasterFileSystem(); |
提供一个与master操作相关的文件系统抽象层,例如,创建表或日志文件的目录 |
|
ServerManager getServerManager(); |
返回ServerManager实例。它可以访问所有的服务器进程,无论进程处于存活、死亡或其它状态 |
|
ExecutorService getExecutorService(); |
执行服务被master用来调度系统级事件 |
|
void checkTableModifiable(final TableName tableName) |
检查表是否已经存在以及是否已经离线,如果是就可以修改它 |
用户可以直接实现MasterObserver接口,或扩展BaseMasterObserver类来实现自己的功能。BaseMasterObserver为接口的每个方法完成一个空的实现。不做任何改变直接使用这个类不会有任何反馈。
例子:创建新表时创建一个单独的目录
<property>
<name>hbase.coprocessor.master.classer</name>
<value>com.hbase.coprocessor.MasterObserverExample</value>
</property>
hbase(main):011:0> create ‘test_master_observer‘,‘f1‘ 0 row(s) in 2.6390 seconds => Hbase::Table - test_master_observer
[root@HDP1-231 lib]# hadoop fs -ls /user/hdfs/hbase/processor/ SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/hdp/2.6.1.0-129/hadoop/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/hdp/2.6.1.0-129/hadoop-yarn/ProcessLog-0.0.1-SNAPSHOT-jar-with-dependencies.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Found 1 items drwxr-xr-x - hbase hdfs 0 2018-09-03 09:52 /user/hdfs/hbase/processor/test_master_observer-blobs
成功。
标签:timestamp ORC rdbms 初始 binder list postget yarn dmi
原文地址:https://www.cnblogs.com/EnzoDin/p/9577561.html