标签:分割 keep key 结构 配置 行记录 文件 之间 serve
 Hbase概述
Hbase概述Hbase是Hadoop生态系统的一个组成部分
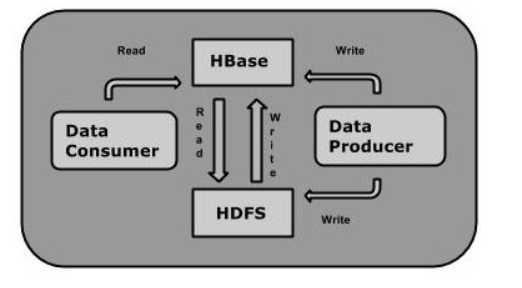
| HDFS | HBase |
| HDFS是适于存储大容量文件的分布式文件系统。 | HBase是建立在HDFS之上的数据库。 |
| HDFS不支持快速单独记录查找 | HBase提供在较大的表快速查找 |
| 它提供了高延迟批量处理;没有批处理概念。 | 它提供了数十亿条记录低延迟访问单个行记录(随机存取) |
| 它提供的数据只能顺序访问。 | HBase内部使用哈希表和提供随机接入,并且其存储索引,可将在HDFS文件中的数据进行快速查找。 |
HBase是一个面向列的数据库,在表中它由行排序。表模式定义只能列族,也就是键值对。
一个表有多个列族以及每一个列族可以有任意数量的列。
后续列的值连续地存储在磁盘上。表中的每个单元格值都具有时间戳。
下面给出的表中是HBase模式的一个例子
| Rowkey | Time Stamp | Column Family | Column Family | Column Family | ||||||
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | ||
| 1 | t1 | a | b | c | a1 | a2 | a3 | |||
| t2 | e | f | g | b1 | b2 | b3 | ||||
| 2 | t3 | |||||||||
| 3 | t4 | |||||||||
Row Key:HBase是采用KeyValue的列存储,那Rowkey就是KeyValue的Key了,表示唯一一行,即表中每条记录的“主键”。
Rowkey也是一段二进制码流,最大长度为64KB,内容可以由使用的用户自定义。数据加载时,一般也是根据Rowkey的二进制序由小到大进行的。
Column Family:拥有一个名称(string),并且包含一个或者多个相关列
Column:属于某一个column family,包含在某一列中 familyName:columnName
Version Number:数据版本号,默认值是系统时间戳,也可由用户提供(无需以递增的顺序插入)
行存储与列存储对比
| 行式数据库 | 列式数据库 |
|
数据是按行存储的 |
数据是按列存储-每一列单独存放 |
|
没有索引的查询使用大量I/O |
数据即是索引 |
| 建立索引需要花费大量时间和资源 | 只访问查询涉及的列-大量降低系统I/O |
| RDBMS有它的模式,描述表的整体结构的约束。 | HBase无模式,它不具有固定列模式的概念;仅定义列族 |
| RDBMS是事务性的。 | 没有任何事务存在于HBase。 |
| 用于结构化数据非常好。 | 它用于半结构以及结构化数据是非常好的。 |
所有操作均是基于rowkey的;
支持CRUD(Create、Read、Update和Delete)和Scan;
单行操作:put get scan
多行操作:Scan,Multiput
没有内置join操作,可使用MapReduce解决
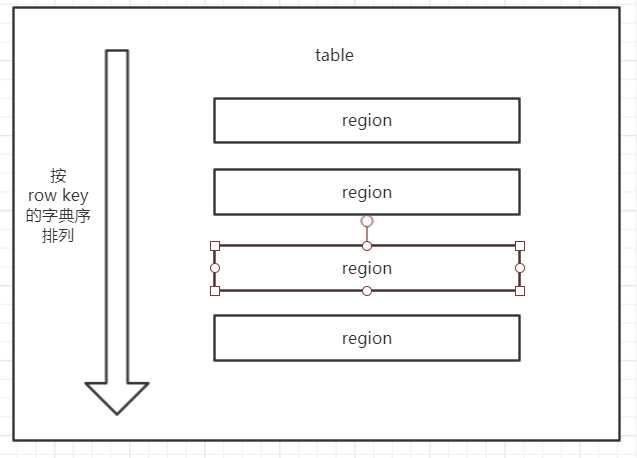
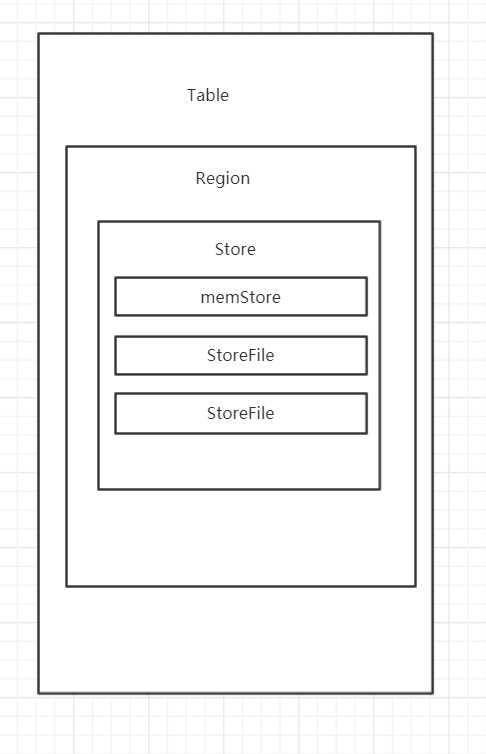
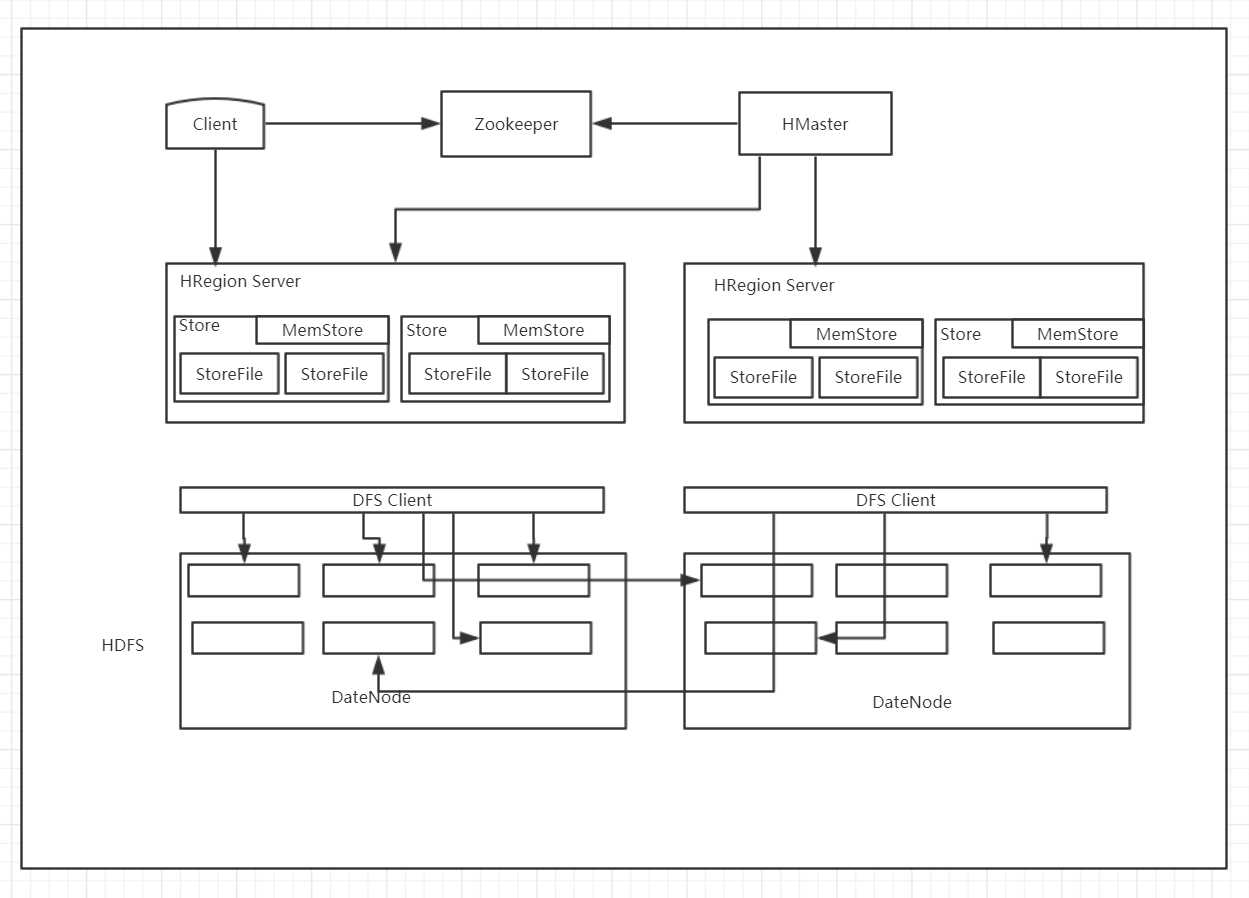
Region按大小分割的,每个表开始只有一个region,随着数据增多, region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region;
Region由一个或者多个Store组成,每个store保存一个columns family
每个Store又由一个memStore和0至多个StoreFile组成;
memStore存储在内存中, StoreFile存储在HDFS上。
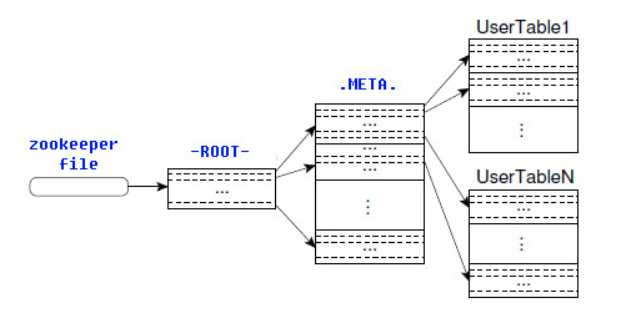
ROOT表和META表
标签:分割 keep key 结构 配置 行记录 文件 之间 serve
原文地址:https://www.cnblogs.com/hollowcabbage/p/9581068.html