标签:汉字 har oct img 命名 htm 计算 通过 com
由于计算机只能处理数字,因此,当需要用计算机来处理字符(以及字符串)的时候,就要有一种机制来实现字符到数字的转换,这便是字符串的编码。
最开始的时候,计算机只有英文字符,故需要编码的符号比较少。此时用的编码为ASCII编码,其中包括大小写英文字母、数字以及一些符号(如图)。
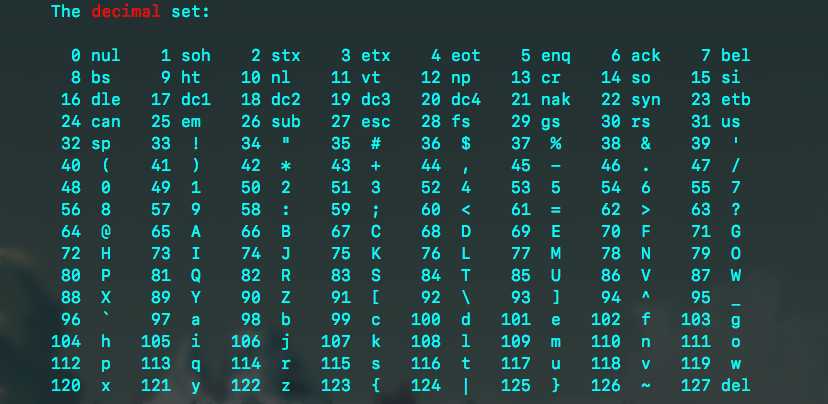
此时实现这些字符的编码,只需要一个字节就够了(即8位)。但是对于中文来说,需要对汉字进行编码时,一个字节是远远不够的。考虑到不能和当时已有的ASCII编码冲突,中文最初制定了GB2312编码。其中包括6763个汉字和682个其它符号。95年重新修订了编码,命名GBK1.0,共收录了21886个符号。 之后又推出了GBK18030编码,共收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字,现在Windows平台必需要支持GBK18030编码。
通过制定了这样的编码标准,使得编码对简体中文汉字、繁体中文汉字实现了有效的支持,但是这个编码体系对于非拉丁字母语言国家来说,还是存在问题。
为了实现所有字符(包括各个国家的语言字符)放在一起时,也不会显示乱码的目标,相关国家的标准化组织和文字工作者共同致力于制定一种新的编码方式,于是,Unicode编码便诞生了。
Unicode的学名为“Universal Multiple-Octet Coded Character Set”,简称UCS。每个Unicode编码的字符都只需要两个字节。
然而,这样的编码规则依旧存在问题,因为当使用Unicode进行编码时,对于ASCII的字符集而言,这些字符的编码直接在其字符编码前加‘0x00‘,但这样会加入一些控制符,如‘/‘,对于Unix以及C语言程序来说,这个字符无疑是十分敏感而又危险的,因此人们在Unicode的基础上,进一步进行了改善,即制定了UTF-8字符集。UTF-8表示在Unicode的基础上进一步修改编码,使得每个字符都能用8的整数倍位来进行存储(即一个字符需要0~3个字节表示存储)。这样的扩充,使得ASCII的字符保留了原始的编码,即这些字符依旧为单字节字符,而汉字则大部分变成了3字节的编码。因此,如今的UTF-8编码标准下,基本中文字符的编码都在3个字节。通过UTF-8这种较为灵活的编码机制,使得上述谈到的所有问题得以解决,这也是当前国际间最流行的存储字符的编码格式。

综上而言,汉字的编码,经历的GB2312、GBK1.0、GBK18030等编码机制后,迈向国际的编码体系,即Unicode编码,及其演化的编码体系UTF-8等,这便是中文汉字编码方案的变化过程。值得一提的是,对于中国大陆而言,Unicode并不被中国政府很好地接受,中国政府要求在中国大陆出售的软件必须支持GBK18030编码格式。
本博客引用文章/博客链接: 《中文繁简字编码知识库》http://www.yuneach.com/soft/sctc.asp
《汉字编码方案》https://wenku.baidu.com/view/d24d71cb852458fb760b561a.html
2018年9月3日,于哈工大软件学院
标签:汉字 har oct img 命名 htm 计算 通过 com
原文地址:https://www.cnblogs.com/stevenshen123/p/9579243.html