标签:rand fonts ssi rom image for 并行执行 tcl 技术分享
代码实现:
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Tue Sep 4 09:38:57 2018 4 5 @author: zhen 6 """ 7 8 from sklearn.ensemble import RandomForestClassifier 9 from sklearn.model_selection import train_test_split 10 from sklearn.metrics import accuracy_score 11 from sklearn.datasets import load_iris 12 import matplotlib.pyplot as plt 13 14 iris = load_iris() 15 x = iris.data[:, :2] 16 y = iris.target 17 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.33, random_state=42) 18 19 # n_estimators:森林中树的个数(默认为10),建议为奇数 20 # n_jobs:并行执行任务的个数(包括模型训练和预测),默认值为-1,表示根据核数 21 rnd_clf = RandomForestClassifier(n_estimators=15, max_leaf_nodes=16, n_jobs=1) 22 rnd_clf.fit(x_train, y_train) 23 24 y_predict_rf = rnd_clf.predict(x_test) 25 26 print(accuracy_score(y_test, y_predict_rf)) 27 28 for name, score in zip(iris[‘feature_names‘], rnd_clf.feature_importances_): 29 print(name, score) 30 31 # 可视化 32 plt.plot(x_test[:, 0], y_test, ‘r.‘, label=‘real‘) 33 plt.plot(x_test[:, 0], y_predict_rf, ‘b.‘, label=‘predict‘) 34 plt.xlabel(‘sepal-length‘, fontsize=15) 35 plt.ylabel(‘type‘, fontsize=15) 36 plt.legend(loc="upper left") 37 plt.show() 38 39 plt.plot(x_test[:, 1], y_test, ‘r.‘, label=‘real‘) 40 plt.plot(x_test[:, 1], y_predict_rf, ‘b.‘, label=‘predict‘) 41 plt.xlabel(‘sepal-width‘, fontsize=15) 42 plt.ylabel(‘type‘, fontsize=15) 43 plt.legend(loc="upper right") 44 plt.show()
结果:

可视化(查看每个预测条件的影响):
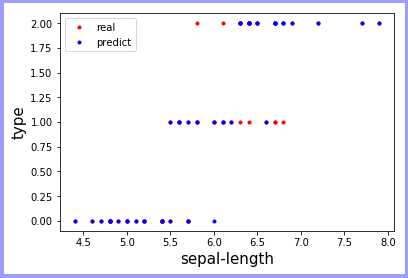
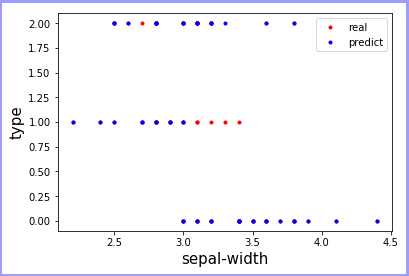
分析:鸢尾花的花萼长度在小于6时预测准确率很高,随着长度的增加,在6~7这段中,预测出现较大错误率,当大于7时,预测会恢复到较好的情况。宽度也出现类似的情况,在3~3.5这个范围出现较高错误,因此在训练中建议在训练数据中适量增加中间部分数据的训练量(该部分不容易区分),以便得到较好的训练模型!
标签:rand fonts ssi rom image for 并行执行 tcl 技术分享
原文地址:https://www.cnblogs.com/yszd/p/9583420.html