简单爬虫R实现
1、广度优先搜索策略
网页的结构通常是一个页面包含正文和多个链接,这些链接大部分是域内链接,但也含有域外链接。通过对这些链接进行遍历,一层一层地搜索就可以搜索到所有页面。
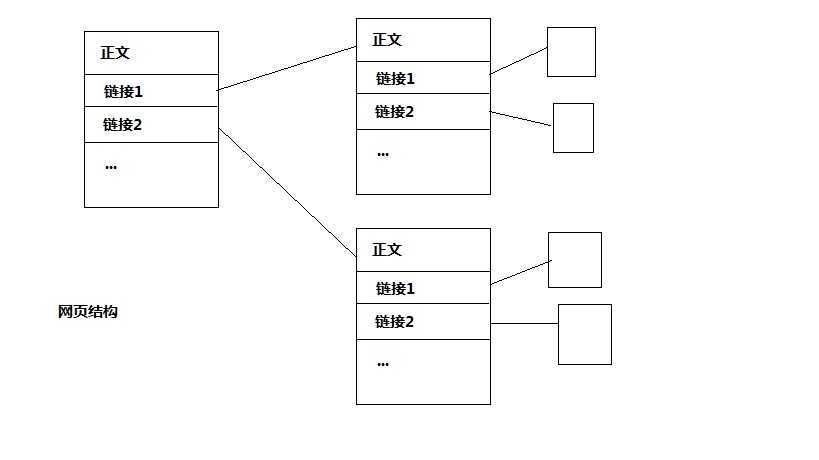
如图,网页结构已经很好的显示了一种图的层次结构。在这种图的结构中,简单地实现遍历,我们就可以采用两种遍历方式,广度优先和宽度优先搜索。形象的说,广度优先就是一层一层的搜索,先搜索父节点,然后搜索父节点的所有子节点,再搜索后面的。宽度优先呢,就是一条路走到底,然后再回过去继续。
很明显,广度优先就是利用队列的思想,宽度优先就是利用栈的思想了。这里谈谈,怎么利用广度优先思想搜索页面。
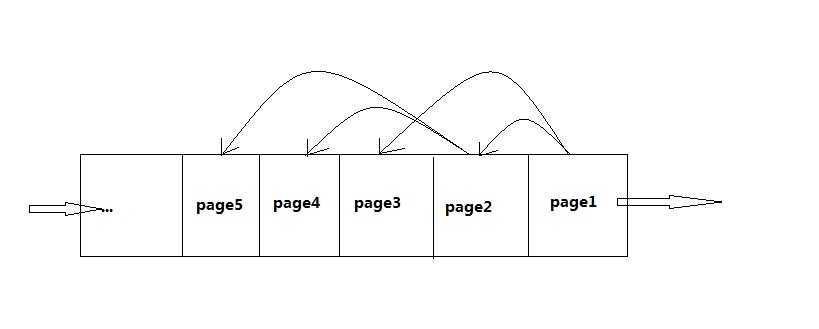
如图显示了页面进入队列的情况,每次搜索一个页面后,就提取页面所有的链接。将这些页面加入到队尾。搜索网页时,就从队首出去一个页面的url。
但仅仅这样是不够的,网页并非是树形结构,而是一个加权有向图。因此,就存在如下的一些问题:
◎环路问题
◎权重衡量的问题
针对环路问题,比较容易解决,就是利用一张hash表记住已经访问过的页面。但是这张hash表却会随着访问的增长越变越大,大到hash表已经几乎失去hash的优势了。
对于权重衡量的问题解决就很复杂了,这里从两个方面提供策略。
1、 链接的内容,从链接的内容着手可以很方便的解决权重问题。一是通过锚文本的内容相关性解决,如果访问的是一个java开发的网站,而锚文本却是一个心理学的内容,一般情况是没多大关系的。二是通过链接内容来分辨,链接的英文字符应该跟本站主题有一定程度的相似性,但链接文本不太好分辨,很多网站的域名或是目录、文件名都没多大规则。三是可以忽略掉一些链接,如图片的链接,很多广告都是这类链接。
2、 链接-页面之间的相关性。看看Google的pagerank算法,这里不作过多的介绍。网站的页面被分为两种,中枢和权威。中枢是一个枢纽,会指向很多的权威页面。而权威则是由多个中枢指定的页面。
2、准备工作
好了,回到正题,这里主要讲一下通过R语言实现网络爬虫。不过这里实现的爬虫不是像Google这样的广义的爬虫,而是基于某一个主题的爬取。这里是心理学方面的。针对不同的爬取需要,可对爬虫策略进行相应的变换。从应用的角度我们可以大致的将爬虫划分为如下几个模块,如图:
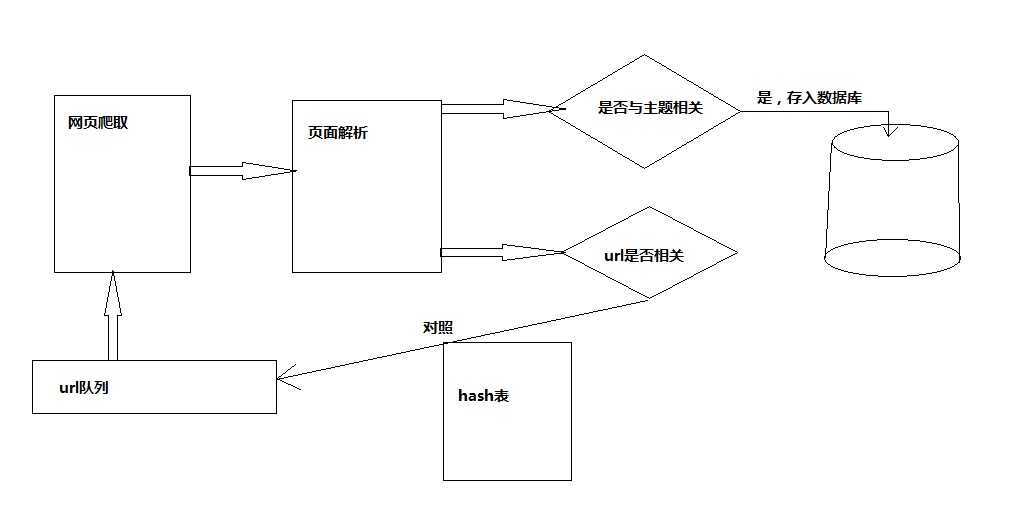
模块分析
1、 数据库模块配置
Windows下配置DNS的数据源,配置过程略。
数据库及表的创建(本例中)
mysql> create table pagetext(
-> href varchar(30) primary key,
-> text text
-> );
2、主题词获取
下载主题词库,然后从外部导入
文本相关度求法à对文本进行分词之后,与主题词进行匹配,看看存在多少个主题相关的词汇,大于k值则表示与主题相关。
3、 代码
library(XML)
library(RODBC)
library(hash)
library(rJava)
library(Rwordseg)
#############################################################
# 模块一,建立主题词库,以数据框的形式保存
#############################################################
data=read.table("F:/psychDict.txt", header=T)
#包含主题词的个数
dataLen=length(data[,1])
countFun=function(vector)
{
count=0;
#此处需要优化,在R里面时间也太长了吧
for(i in 1:length(vector))
{
for(j in 1:dataLen)
{
if(vector[i]==data[1,])
{
count = count+1
break
}
}
}
return(count)
}
###########################################################
# 模块二、爬虫流程模块
###########################################################
minCorCount=10 #主题词汇最少个数
#建立一个hash表,保存已经访问过的url
closedH=hash()
#将初始链接加入队列,我们用一个向量来模拟队列
urlQueue=c("http://www.baidu.com/")
for(time in 1:100)
{
#取出队头,下载页面
page=htmlParse(urlQueue[1])
#提取正文
text=xmlValue(xmlRoot(page))
#去掉非中文字符
text=gsub("[^\u4e00-\u9fa5]","",text)
#检测正文内容是否相关
textV=segmentCN(text)
textCor=countFun(textV)
#如果相关,则将其加入数据库
if(textCor>=minCorCount)
{
sqlAddpage(urlQueue[1],text)
}
#获取所有链接
links=getNodeSet(page,"//a")
#遍历每个链接节点
for(i in 1:length(links))
{
#提取链接href
href=xmlGetAttr(links[[i]],"href")
#提取锚文本
linkText=xmlValue(links[[i]])
#如果锚文本主题相关,则将其加入队列
linkV=segmentCN(linkText)
corCount=countFun(linkV)
if(corCount>0)
{
#如果这个链接不在close表里面
if(closedH[[href]]==NULL)
{
#加入到队列
urlQueue=c(urlQueue,href)
}
}
#如果不相关,则将其加入hash表中
else
{
.set(closedH,keys=href,values=linkText)
}
}
#将遍历过的URL加入close表并且从队列里面删除
.set(closedH,keys=href,values=linkText)
urlQueue=urlQueue[-1]
}
##############################################################
# 模块三、数据库访问模块
##############################################################
#将正文加入数据库
sqlAddPage=function(href,text)
{
channel=odbcConnect("mysqldata",uid="root",pwd="chenzhi2014")
sql=paste("insert into pagetext values(‘",href,"‘,‘",text,"‘)")
#建议数据保存使用这种简单的方式
sqlQuery(channel,sql)
close(channel)
}
4、 改进地方
上述有很多地方都是需要改进的,下面列出几个。
l 主题词汇词典的表示,一般词典都是通过2字hash索引建立的,在R语言里面可以使用hash类直接建立索引,这其实是一个必须改动的地方,不然会非常非常慢。
l 文档与主题的相似度求法,这里直接给的一个阈值恒定,可以利用相关度的概率论公式进行求解。
l 还有之间说过的 hash表的问题,如何解决hash表无限膨胀的问题。
原文地址:http://www.cnblogs.com/mixes/p/3725297.html