标签:变量 flume 用户画像 地址映射 应用程序 app 存储类型 分布式协调 模块
Hadoop hive hbase flume kafka sqoop spark flink …….
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
2.现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
3.而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
1、HADOOP应用于数据服务基础平台建设
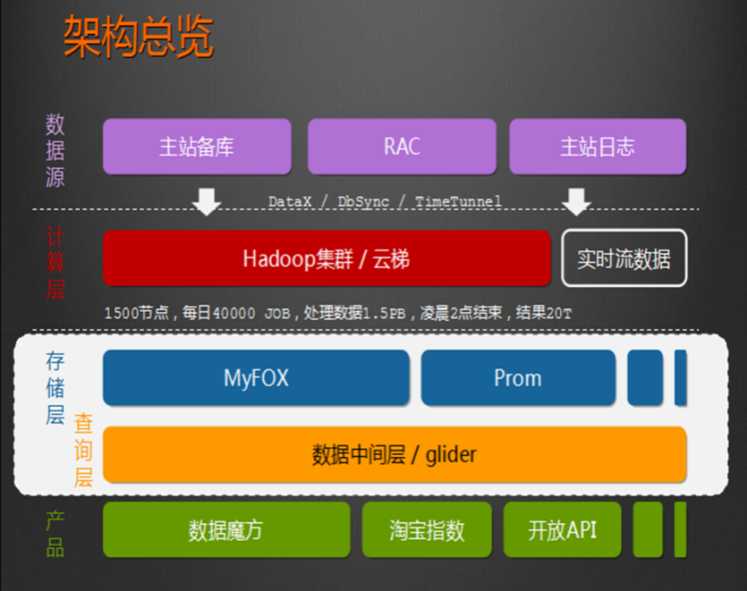
2、HADOOP用于用户画像

3、HADOOP用于网站点击流日志数据挖掘
1、 HADOOP就业整体情况
2、 HADOOP就业职位要求
大数据是个复合专业,包括应用开发、软件平台、算法、数据挖掘等,因此,大数据技术领域的就业选择是多样的,但就HADOOP而言,通常都需要具备以下技能或知识:
3、 HADOOP相关职位的薪资水平
大数据技术或具体到HADOOP的就业需求目前主要集中在北上广深一线城市,薪资待遇普遍高于传统JAVAEE开发人员
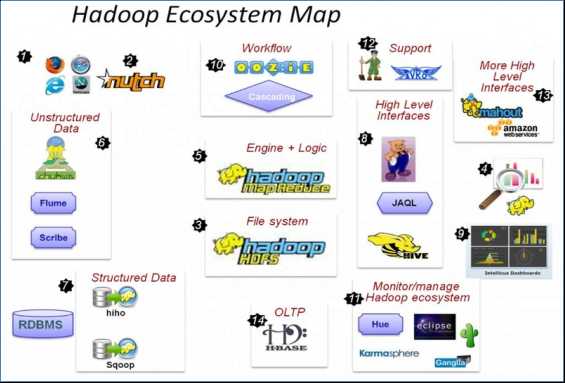
各组件简介
重点组件:
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
注:由于大数据技术领域的各类技术框架基本上都是分布式系统,因此,理解hadoop、storm、spark等技术框架,都需要具备基本的分布式系统概念
2 该软件系统会划分成多个子系统或模块,各自运行在不同的机器上,子系统或模块之间通过网络通信进行协作,实现最终的整体功能
2 比如分布式操作系统、分布式程序设计语言及其编译(解释)系统、分布式文件系统和分布式数据库系统等。
总结:利用多个节点共同协作完成一项或多项具体业务功能的系统就是分布式系统。
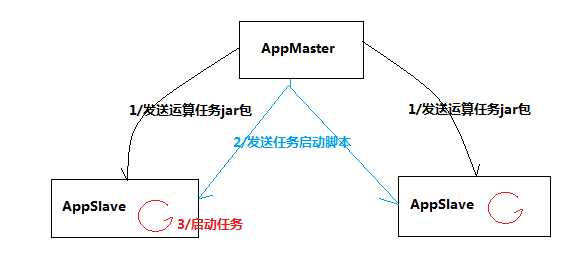
需求:可以实现由主节点将运算任务发往从节点,并将各从节点上的任务启动;
程序清单:
AppMaster
AppSlave/APPSlaveThread
Task
程序运行逻辑流程:
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包)
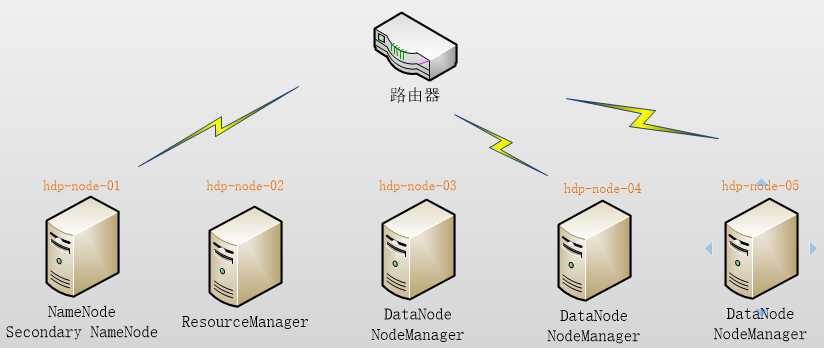
本集群搭建案例,以5节点为例进行搭建,角色分配如下:
hdp-node-01 NameNode SecondaryNameNode hdp-node-02 ResourceManager hdp-node-03 DataNode NodeManager hdp-node-04 DataNode NodeManager hdp-node-05 DataNode NodeManager
部署图如下:
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
1、 Vmware 14.0
2、Centos 6.7 64bit
创建虚拟机:
1.点击文件,新建一个虚拟机
2.安装时选则自定义,下一步,兼容性直接点下一步
3.点稍后安装操作系统,下一步
4.客户机操作系统选择Linux,版本Centos 64位 ,下一步
5.修改虚拟机名称 指定虚拟机存放位置 下一步
6.处理器数量1 核心数量2 下一步
7.设置虚拟机大小2GB 下一步
8.网络连接类型选NAT 下一步
9.SCSI控制器选择推荐的 下一步
10.虚拟磁盘类型选择推荐的 下一步
11.创建新虚拟磁盘 下一步
12.磁盘大小20G(一般为20G-50G) 拆分为多个文件 下一步
13.下一步
14.完成
15.之后在VMware窗口 选择刚刚装好的虚拟机 点击 cd/dvd 然后选择 使用ISO映象文件 浏览选择
16.点击 VMware上方的 编辑 选择虚拟网络编辑器
17.进去后(win10需要点击右下方的 更改设置) 选择VMnet8(NAT模式) 设置子网IP:192.168.59.0 子网掩码:255.255.255.0
18.启动虚拟机 点击skip 之后选择下一步 然后选择中文 下一步 选择简体中文 下一步
19.选择存储类型 Basic 下一步
20.Yes 格式化硬盘 下一步
21.设置主机名 (主机名可更改) 下一步
22.设置时间 上海 点击上海的位置 下一步
23.设置root用户密码 123456 记住密码 密码简单 选择use anyway 下一步
24.磁盘划分使用默认划分方式 next
25.write change to disk , next 等待安装 Reboot
26.重启之后 输入用户名: root 密码 :123456
之后 在3.1.4
1. 采用NAT方式联网
2. 3个服务器节点IP地址:192.168.59.130、192.168.59.131、192.168.59.132
3. 子网掩码:255.255.255.0
添加映射(添加主机名和ip地址映射 即其他虚拟机所在位置)
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.59.130 hadoop
192.168.59.131 hadoop001
192.168.59.132 hadoop002
设置主机名
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop
网卡配置
vi /etc/sysconfig/network-scripts/ifcfg-eth0
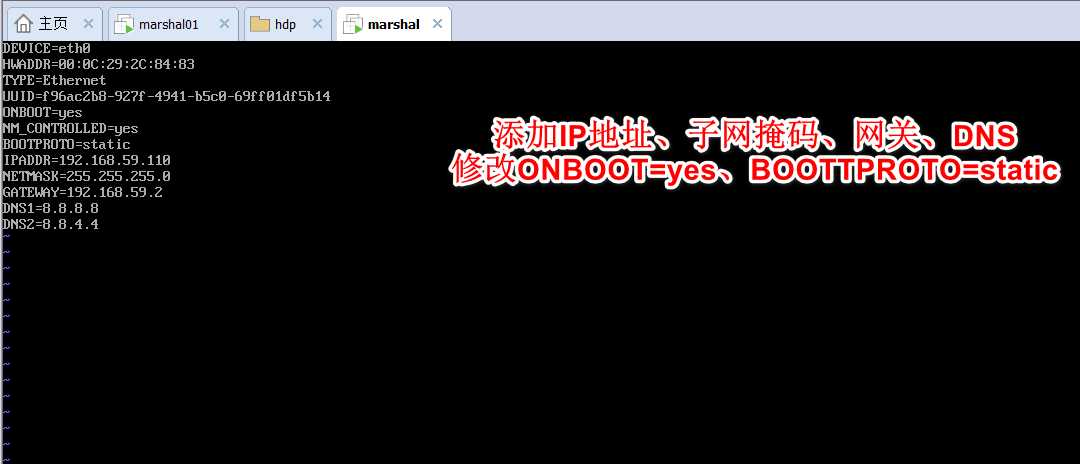
本机进入 C:\Windows\System32\drivers\etc 修改hosts 添加
192.168.59.130 hadoop
192.168.59.131 hadoop001
192.168.59.132 hadoop002
# ip地址 主机名
查看防火墙状态
service iptables status
关闭防火墙
service iptables stop
安装ssh
yum install -y openssh-clients
使用xshell连接虚拟机
主机那里输入192.168.59.130 或者 hadoop都可以(输入hadoop必须把本机hosts配置好)
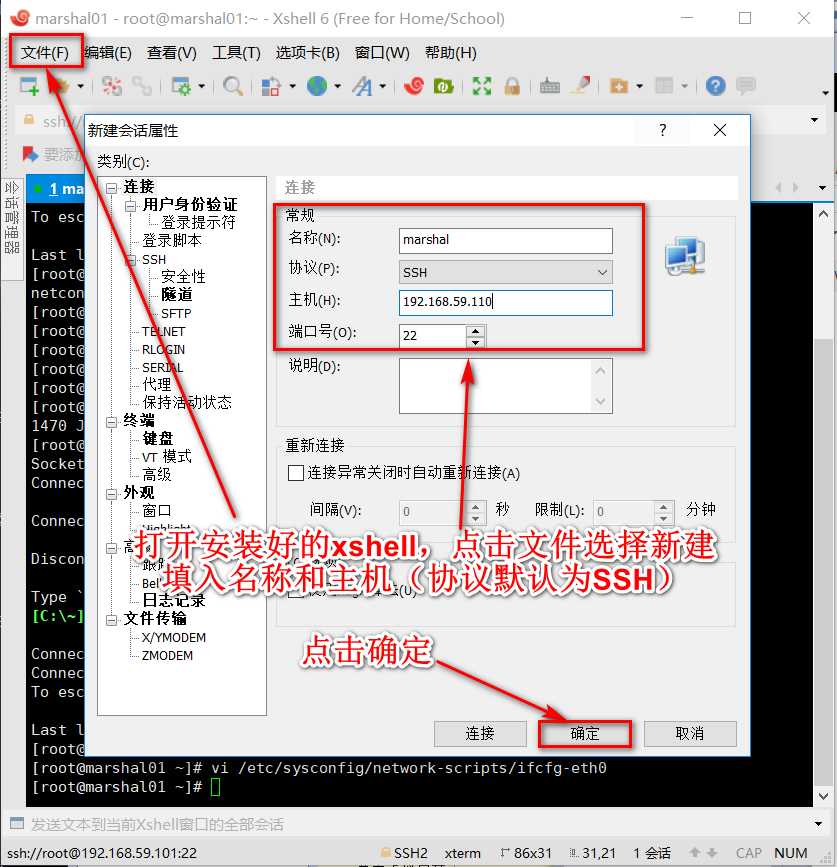
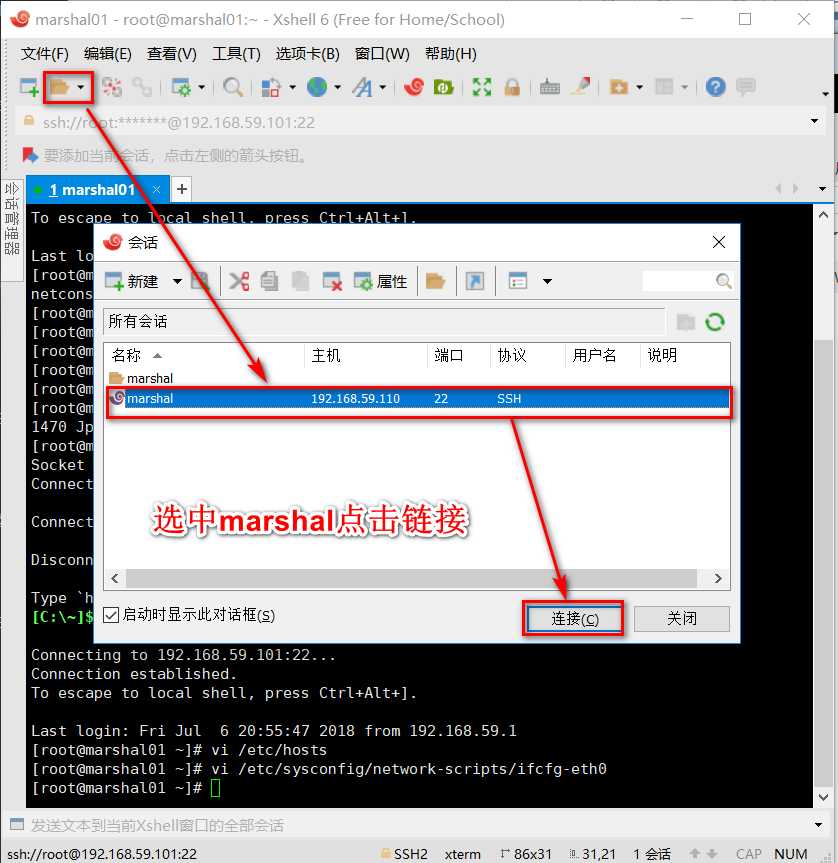
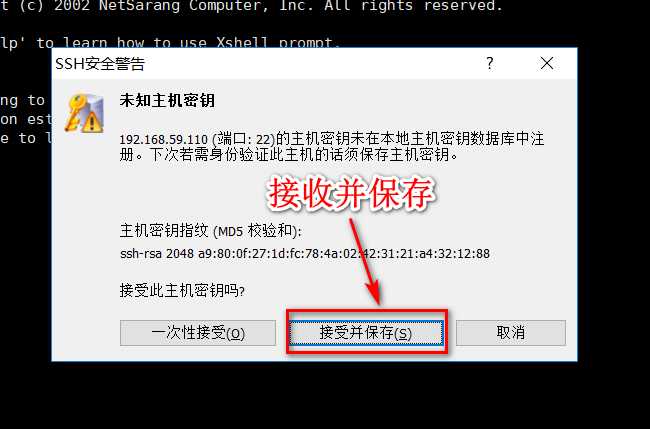
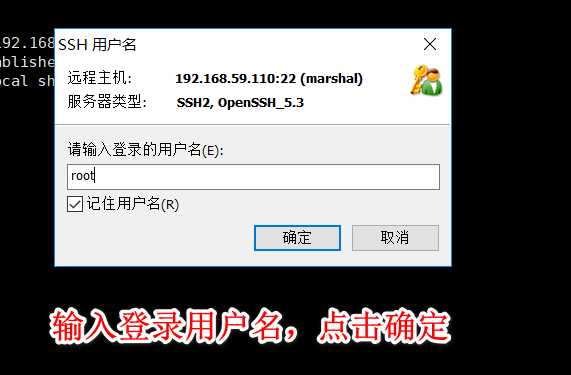
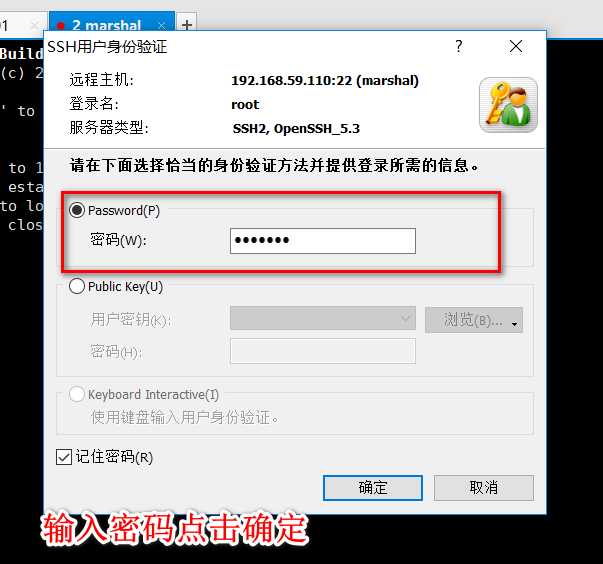
此时就可以用xshell连接虚拟机
上传jdk安装包
规划安装目录 /home/hadoop/apps/jdk_1.8.65
解压安装包
配置环境变量 /etc/profile
上传HADOOP安装包
规划安装目录 /home/hadoop/apps/hadoop-2.8.3
解压安装包
修改配置文件 $HADOOP_HOME/etc/hadoop/
最简化配置如下:
在hadoop目录/etc/hadoop下
vi hadoop-env.sh
JAVA_HOME java放在哪个位置
# The java implementation to use.
export JAVA_HOME=/home/hadoop/apps/jdk_1.8.65
vi core-site.xml
fs.defaultFS 主机名:端口号
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hdp-node-01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/HADOOP/apps/hadoop-2.6.1/tmp</value> </property> </configuration>
vi hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/data/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/data/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.secondary.http.address</name> <value>hdp-node-01:50090</value> </property> </configuration>
vi mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
vi yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
vi salves
hdp-node-02 hdp-node-03
初始化HDFS
bin/hadoop namenode -format
启动HDFS
sbin/start-dfs.sh
启动YARN
sbin/start-yarn.sh
标签:变量 flume 用户画像 地址映射 应用程序 app 存储类型 分布式协调 模块
原文地址:https://www.cnblogs.com/lq0310/p/9591088.html