标签:however 通用 hal isp bsp view 模块化 使用 UNC
现在提到“神经网络”和“深度神经网络”,会觉得两者没有什么区别,神经网络还能不是“深度”(deep)的吗?我们常用的 Logistic regression 就可以认为是一个不含隐含层的输出层激活函数用 sigmoid(logistic) 的神经网络,显然 Logistic regression 就不是 deep 的。不过,现在神经网络基本都是 deep 的,即包含多个隐含层。Why?
任何连续的函数 $f: R^N \to R^M$ 都可以用只有一个隐含层的神经网络表示。(隐含层神经元足够多)
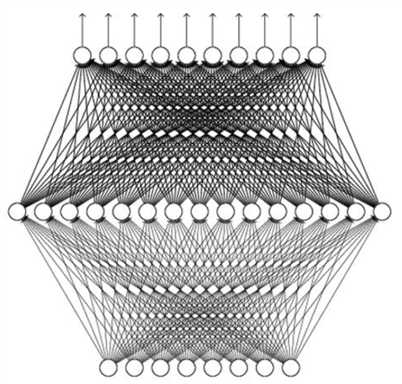
图 1:仅含一个隐含层的神经网络示意图
一个神经网络可以看成是一个从输入到输出的映射,那么既然仅含一个隐含层的神经网络可以表示任何连续的函数,为什么还要多个隐含层的神经网络?
"Yes, shallow network can represent any function.
However, using deep structure is more effective."
我们可以把仅含一个隐含层的神经网络结构叫做 shallow 的,把包含多个隐藏层的神经网络结构叫做 deep 的。
李宏毅教授在他的机器学习视频中,提出一种叫做 Modularization(模块化)的解释。
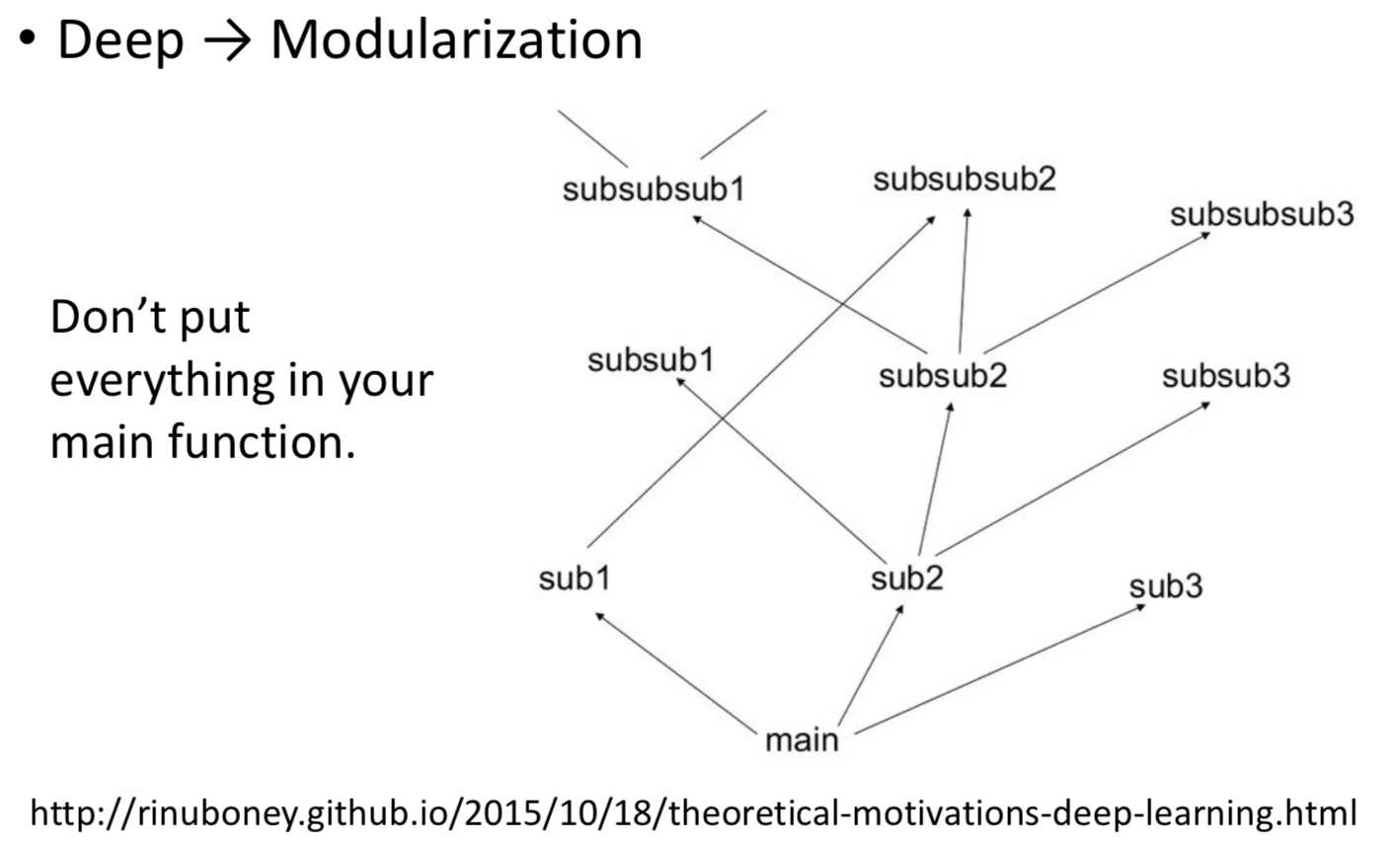
图 2:Modularization
在多层神经网络中,第一个隐含层学习到的特征是最简单的,之后每个隐含层使用前一层得到的特征进行学习,所学到的特征变得越来越复杂。 如图 3 和 4 所示。

图 3:不同level的特征-1
low level 中每一个特征在 high level 或多或少被使用,这样对于每一个 high level 特征,只需要训练一套 low level 特征。是的,low level 特征被共用了,相当于将提取 low level 特征单独成立了一个模块,供高层调用。对于每一个 high level 特征,不需要每次都将 low level 特征训练一遍。这就是 deep 的好处。
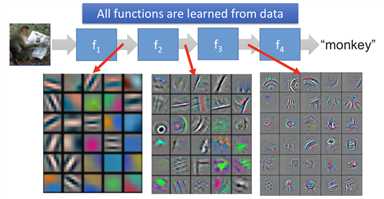
图 4:不同level特征-2
在比较深度神经网络和仅含一个隐含层神经网络的效果时,需要控制两个网络的 trainable 参数数量相同,不然没有可比性。李宏毅教授在他的机器学习视频中举例,相同参数数量下,deep 表现更好;这也就意味着,达到相同的效果,deep 的参数会更少。
不否认,理论上仅含一个隐含层的神经网络完全可以实现深度神经网络的效果,但是训练难度要大于深度神经网络。
实际上,在深度神经网络中,一个隐含层包含的神经元也不少了,比如 AlexNet 和 VGG-16 最后全连接层的 4096 个神经元。在 deep 的同时,fat 也不是说不需要,只是没有像只用一层隐含层那么极端,每个隐含层神经元的个数也是我们需要调节的超参数之一。
Universal approximation theorem - Wikipedia
标签:however 通用 hal isp bsp view 模块化 使用 UNC
原文地址:https://www.cnblogs.com/wuliytTaotao/p/9590633.html