标签:map patch 深度学习 sele ima 很多 cti 图像 http
目标检测(object detection)的基本思路: 检测(detection)+ 定位(localization)
目标检测在很多场景有用,如无人驾驶和安防系统。
特征提取算法(如:haar特征,HOG特征)+分类器(如:svm)
Selective Search to Extract Regions + CNN提取特征 + SVM分类
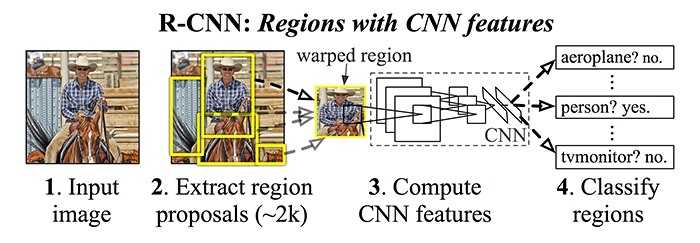
主要步骤:
(1) 输入测试图像
(2) 利用selective search算法在图像中提取2000个左右的region proposal。
(3) 将每个region proposal缩放(warp)成227x227的大小并输入到CNN,将CNN的fc7层的输出作为特征。
(4) 将每个region proposal提取到的CNN特征输入到SVM进行分类。
去掉了单独SVM分类的部分,直接用CNN的网络实现分类
Fast R-CNN在整个图片上使用CNN,然后对特征映射使用“兴趣区域” (Region of Interest, RoI) 池化,最后使用前馈网络进行分类和回归。
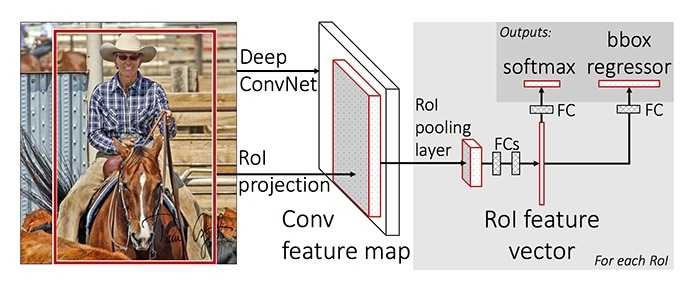
主要步骤:
(1)在图像中确定约1000-2000个候选框 (使用选择性搜索)
(2)对整张图片输进CNN,得到feature map
(3)找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
(4)对候选框中提取出的特征,使用分类器判别是否属于一个特定类
(5)对于属于某一特征的候选框,用回归器进一步调整其位置
Faster-RCNN添加了区域提案网络 (Region Proposal Network, RPN),摆脱了选择性搜索算法,并可以做到端到端的训练。
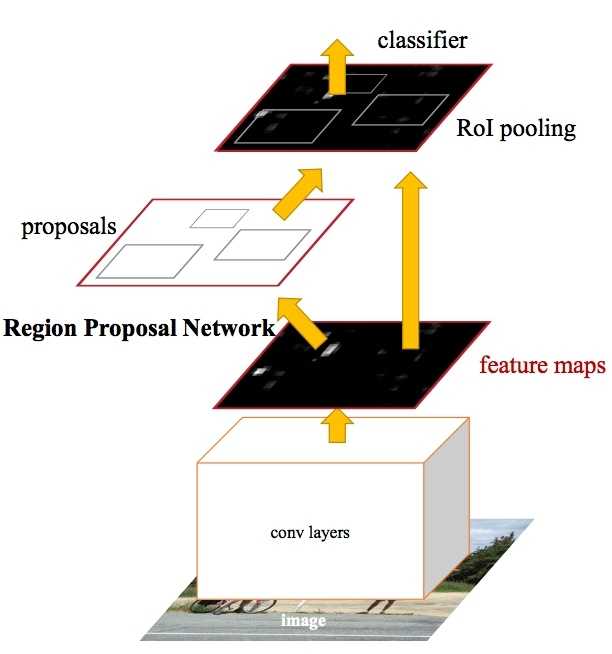
(1)对整张图片输进CNN,得到feature map
(2)卷积特征输入到RPN,得到候选框的特征信息
(3)对候选框中提取出的特征,使用分类器判别是否属于一个特定类
(4)对于属于某一特征的候选框,用回归器进一步调整其位置
SSD算法是一种直接预测目标类别和bounding box的多目标检测算法。与faster rcnn相比,该算法没有生成 proposal 的过程,这就极大提高了检测速度。
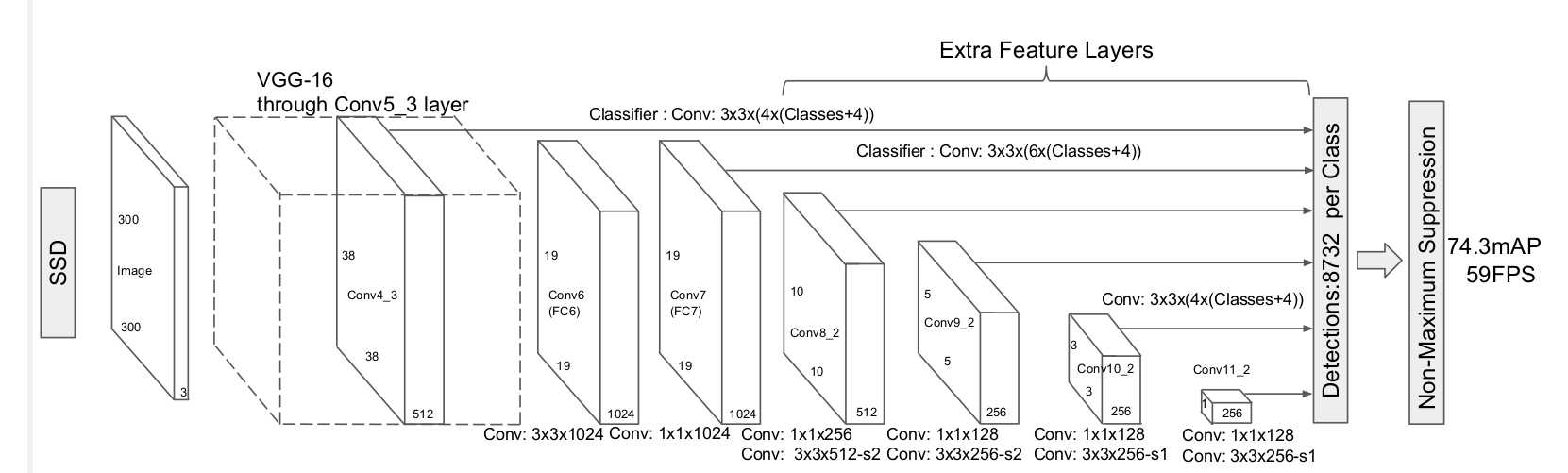
Reference:https://blog.csdn.net/f290131665/article/details/81012556
标签:map patch 深度学习 sele ima 很多 cti 图像 http
原文地址:https://www.cnblogs.com/lightsun/p/9489426.html