标签:设置 目录 文件名 返回 开发 允许 href sdn tag
本篇介绍使用 Tesseract-OCR 做图片文字识别,识别手写文字的时候,正确率能达到 90%,当训练后正确率是极高的。这里介绍的图片文字识别,可以识别英文,数字和中文等
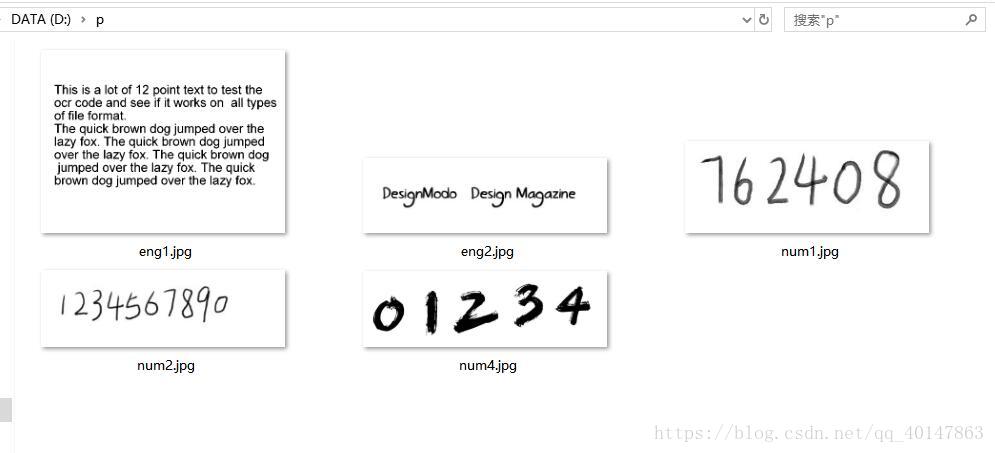
使用 Tesseract 命令:
tesseract 文件名 保存的txt文件名 -l eng 例:
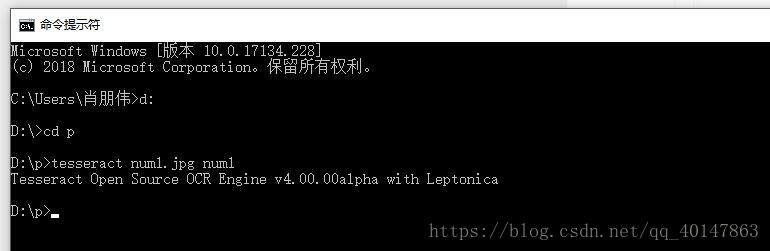
tesseract num1.jpg num1
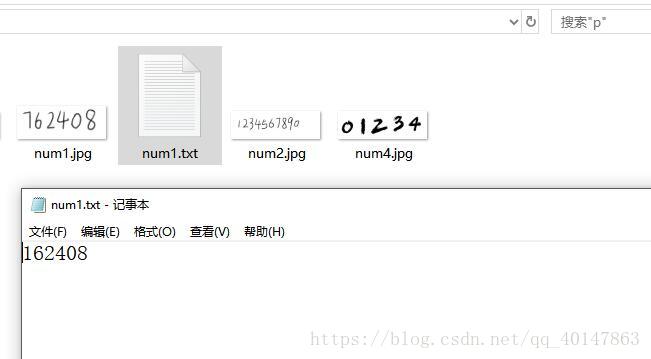


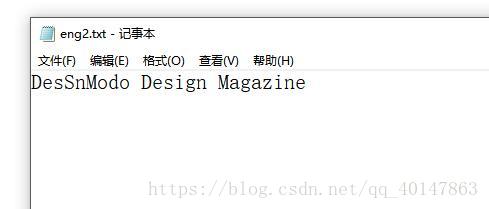
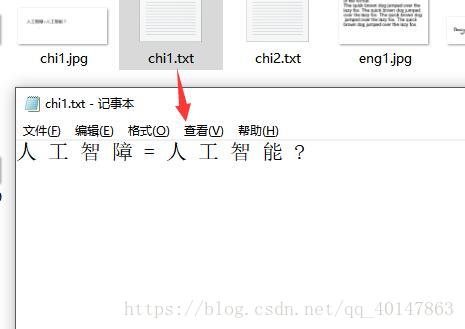
对 有中文文字的图片 chi1.jpg ,进入图片路径,使用一下命令:
tesseract chi1.jpg chi1 -l chi_sim

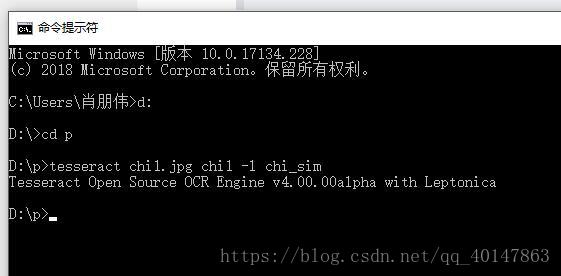
运行结果:
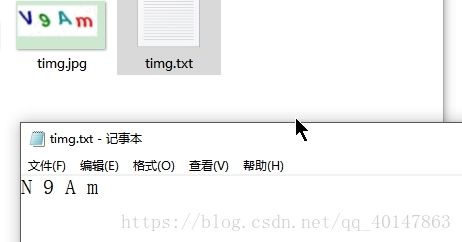
对 图片 timg.jpg ,进入图片路径,使用一下命令:
tesseract timg.jpg timg

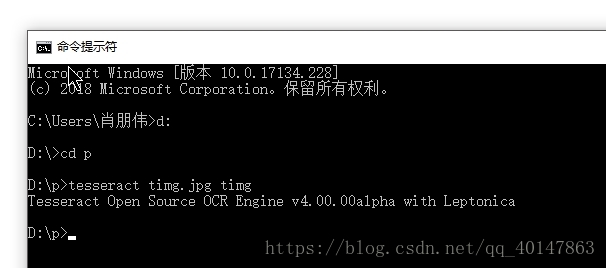
运行结果:
标签:设置 目录 文件名 返回 开发 允许 href sdn tag
原文地址:https://www.cnblogs.com/xpwi/p/9604472.html