标签:解析json 有一个 print linu 字段 create 2.0 get creat
Hive基本操作
01.Hive是什么
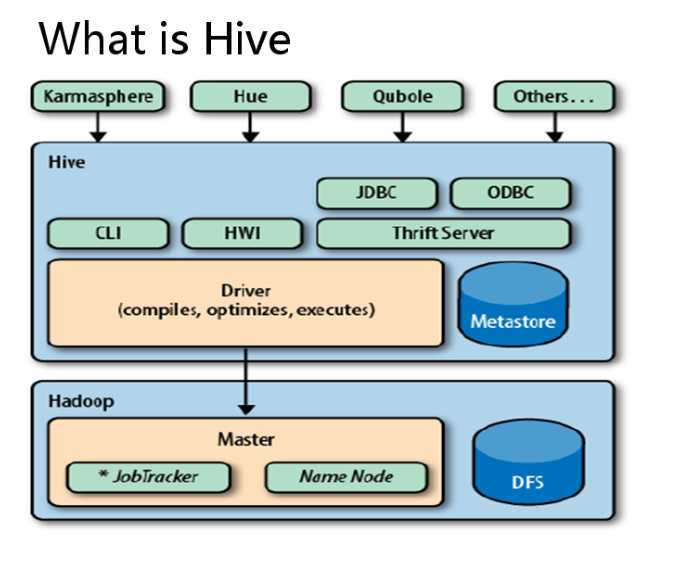
p:用 HDFS 进行存储,利用 MapReduce 进行计算
Ps:hive的元数据并不存放在hdfs上,而是存储在数据库中(metastore),目前只支持 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
元数据就是描述数据的数据,而Hive的数据存储在Hadoop HDFS
数据还是原来的文本数据,但是现在有了个目录规划。
Hive利用HDFS存储数据,利用MapReduce查询数据。
Hive只是一个工具,不需要集群配置。
export HIVE_HOME=/usr/local/hive-2.0.1
export PATH=PATH:PATH:HIVE_HOME/bin
配置MySql,如果不进行配置,默认使用derby数据库,但是不好用,在哪个地方执行./hive命令,哪儿就会创建一个metastore_db
MySQL安装到其中某一个节点上即可。
可以安装在某一个节点,并发布成标准服务,在其他节点使用beeline方法。
启动方式,(假如是在master上):
启动为前台服务:bin/hiveserver2
启动为后台:nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
连接方法:
hive/bin/beeline 回车,进入beeline的命令界面
输入命令连接hiveserver2
beeline> !connect jdbc:hive2://master:10000
beeline> !connect jdbc:hive2://localhost:10000
(master是hiveserver2所启动的那台主机名,端口默认是10000)
02.Hive的基本操作
hive > create database tabletest;
语法:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]示例:
create table t_order(id int,name string,rongliang string,price double)
row format delimited fields terminated by ‘\t‘;创建了一个t_order表,对应在Mysql的元数据中TBLS表会增加表的信息,和列的信息,如下:
同时,会在HDFS的中的tabletest.db文件夹中增加一个t_order文件夹。所有的 Table 数据(不包括 External Table)都保存在这个目录中。
可以直接使用HDFS上传文件到t_order文件夹中,或者使用Hive的load命令。
load data local inpath ‘/home/hadoop/ip.txt‘ [OVERWRITE] into table tab_ext;作用和上传本地linux文件到HDFS系统一样;但需要注意,如果inpath 后面路径是HDFS路径,则将是将其删除后,剪切到目标文件夹,不好!
EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
为了避免源文件丢失的问题,可以建立external表,数据源可以在任意位置。
CREATE EXTERNAL TABLE tab_ip_ext(id int, name string,
ip STRING,
country STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘
STORED AS TEXTFILE
LOCATION ‘/external/hive‘;在创建表的时候,就指定了HDFS文件路径,因此,源文件上传到/external/hive/文件夹即可。
外部表删除时,只删除元数据信息,存储在HDFS中的数据没有被删除。
作用:如果文件很大,用分区表可以快过滤出按分区字段划分的数据。
t_order中有两个分区part1和part2.
实际就是在HDFS中的t_order文件夹下面再建立两个文件夹,每个文件名就是part1和part2。
create table t_order(id int,name string,rongliang string,price double)
partitioned by (part_flag string)
row format delimited fields terminated by ‘\t‘;插入数据:
load data local inpath ‘/home/hadoop/ip.txt‘ overwrite into table t_order
partition(part_flag=‘part1‘);就会把ip.txt文件上传到/t_order/part_flag=‘part1‘/文件夹中。
查看分区表中的数据:
select * from t_order where part_flag=‘part1‘;查询时,分区字段也会显示,但是实际表中是没有这个字段的,是伪字段。
hive中的分区 就是再多建一个目录, 优点:便于统计,效率更高,缩小数据集。
相关命令:
Hive里的分桶=MapReduce中的分区,而Hive中的分区只是将数据分到了不同的文件夹。
创建分桶表
create table stu_buck(Sno int,Sname string,Sex string,Sage int,Sdept string)
clustered by(Sno)
sorted by(Sno DESC)
into 4 buckets
row format delimited
fields terminated by ‘,‘;
含义:根据Sno字段分桶,每个桶按照Sno字段局部有序,4个桶。建桶的时候不会的数据做处理,只是要求插入的数据是被分好桶的。
一般不适用load数据进入分桶表,因为load进入的数据不会自动按照分桶规则分为四个小文件。所以,一般使用select查询向分桶表插入文件。
设置变量,设置分桶为true, 设置reduce数量是分桶的数量个数
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
insert overwrite table student_buck
select * from student cluster by(Sno);
insert overwrite table stu_buck
select * from student distribute by(Sno) sort by(Sno asc);其中,可以用distribute by(sno) sort by(sno asc)替代cluster by(Sno),这是等价的。cluster by(Sno) = 分桶+排序
先分发,再局部排序。区别是distribute更加灵活,可以根据一个字段分区,另外字段排序。
第二个子查询的输出了4个文件作为主查询的输入。
原理:
Hive是针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。(原理和MapReduce的getPartition方法相同)
作用:
(1) 最大的作用是用来提高join操作的效率;
前提是两个都是分桶表且分桶数量相同或者倍数关系?
思考这个问题:
select a.id,a.name,b.addr from a join b on a.id = b.id;
如果a表和b表已经是分桶表,而且分桶的字段是id字段
做这个join操作时,还需要全表做笛卡尔积吗?
对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
Hive一条一条的insert太慢。
但是可以批量的insert.实际就是想文件夹中追加文件。
create table tab_ip_like like tab_ip;
insert overwrite table tab_ip_like
select * from tab_ip;向tab_ip_like中追加文件
1、将查询结果保存到一张新的hive表中
create table t_tmp
as
select * from t_p;
2、将查询结果保存到一张已经存在的hive表中
insert into table t_tmp
select * from t_p;
3、将查询结果保存到指定的文件目录(可以是本地,也可以是HDFS)
insert overwrite local directory ‘/home/hadoop/test‘
select * from t_p;
插入HDFS
insert overwrite directory ‘/aaa/test‘
select * from t_p;
语法:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list]
]
[LIMIT number]注:
因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by
select * from inner_table
select count(*) from inner_table删除表时,元数据与数据都会被删除
drop table inner_tableLEFT JOIN,RIGHT JOIN, FULL OUTER JOIN ,inner join, left semi join
准备数据
1,a
2,b
3,c
4,d
7,y
8,u
2,bb
3,cc
7,yy
9,pp
建表:
create table a(id int,name string)
row format delimited fields terminated by ‘,‘;
create table b(id int,name string)
row format delimited fields terminated by ‘,‘;导入数据:
load data local inpath ‘/home/hadoop/a.txt‘ into table a;
load data local inpath ‘/home/hadoop/b.txt‘ into table b;inner join
select * from a inner join b on a.id=b.id;
+-------+---------+-------+---------+--+
| a.id | a.name | b.id | b.name |
+-------+---------+-------+---------+--+
| 2 | b | 2 | bb |
| 3 | c | 3 | cc |
| 7 | y | 7 | yy |
+-------+---------+-------+---------+--+
就是求交集。
inner join
select * from a left join b on a.id=b.id;
+-------+---------+-------+---------+--+
| a.id | a.name | b.id | b.name |
+-------+---------+-------+---------+--+
| 1 | a | NULL | NULL |
| 2 | b | 2 | bb |
| 3 | c | 3 | cc |
| 4 | d | NULL | NULL |
| 7 | y | 7 | yy |
| 8 | u | NULL | NULL |
+-------+---------+-------+---------+--+
左边没有找到连接的置空。
right join
select * from a right join b on a.id=b.id;
full outer join
select * from a full outer join b on a.id=b.id;
+-------+---------+-------+---------+--+
| a.id | a.name | b.id | b.name |
+-------+---------+-------+---------+--+
| 1 | a | NULL | NULL |
| 2 | b | 2 | bb |
| 3 | c | 3 | cc |
| 4 | d | NULL | NULL |
| 7 | y | 7 | yy |
| 8 | u | NULL | NULL |
| NULL | NULL | 9 | pp |
+-------+---------+-------+---------+--+
两边数据都显示。
left semi join
select * from a left semi join b on a.id = b.id;
+-------+---------+--+
| a.id | a.name |
+-------+---------+--+
| 2 | b |
| 3 | c |
| 7 | y |
+-------+---------+--+
只返回左边一半,即a的东西,效率高一点。
可以存储中间结果。
CREATE TABLE tab_ip_ctas
AS
SELECT id new_id, name new_name, ip new_ip,country new_country
FROM tab_ip_ext
SORT BY new_id;
当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
UDF 作用于单个数据行,产生一个数据行作为输出。(数学函数,字符串函数)
UDAF(用户定义聚集函数):接收多个输入数据行,并产生一个输出数据行。(count,max)
2.UDF开发实例
1、先开发一个java类,继承UDF,并重载evaluate方法
public class ToLowerCase extends UDF {
// 必须是public
public String evaluate(String field) {
String result = field.toLowerCase();
return result;
}
}2、打成jar包上传到服务器
3、将jar包添加到hive的classpath
hive>add JAR /home/hadoop/udf.jar;4、创建临时函数与开发好的java class关联
Hive>create temporary function tolowercase as ‘cn.itcast.bigdata.udf.ToProvince‘;5、即可在hql中使用自定义的函数strip
select id,tolowercase(name) from t_p;3.Transform实现
Hive的 TRANSFORM 关键字提供了在SQL中调用自写脚本的功能
适合实现Hive中没有的功能又不想写UDF的情况。
1、先加载rating.json文件到hive的一个原始表 rat_json
//{"movie":"1721","rate":"3","timeStamp":"965440048","uid":"5114"}
create table rat_json(line string) row format delimited;
load data local inpath ‘/opt/rating.json‘ into table rat_json2、需要解析json数据成四个字段,插入一张新的表 t_rating(用于存放处理的数据,需要有四个字段)
create table t_rating(movieid string,rate int,timestring string,uid string)
row format delimited fields terminated by ‘\t‘;
insert overwrite table t_rating
select get_json_object(line,‘$.movie‘) as moive,get_json_object(line,‘$.rate‘) as rate from rat_json;
//get_json_object是内置jason函数,也可以自定义UDF函数实现3、使用transform+python的方式去转换unixtime为weekday
(1)先编辑一个python脚本文件
python代码:
vi weekday_mapper.py
#!/bin/python
import sys
import datetime
for line in sys.stdin:
line = line.strip()
movieid, rating, unixtime,userid = line.split(‘\t‘)
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print ‘\t‘.join([movieid, rating, str(weekday),userid])(2)将文件加入hive的classpath:
hive>add FILE /home/hadoop/weekday_mapper.py;
hive>create TABLE u_data_new as
SELECT
TRANSFORM (movieid, rate, timestring,uid)
USING ‘python weekday_mapper.py‘
AS (movieid, rate, weekday,uid)
FROM t_rating;
select distinct(weekday) from u_data_new limit 10;将查询处理过的新数据插入u_data_new文件中。
标签:解析json 有一个 print linu 字段 create 2.0 get creat
原文地址:https://www.cnblogs.com/suway/p/9606976.html