标签:创建 定义 开发环境 总结 一周 次数 哈希函数 hash函数 常量
数据结构
数据结构是计算机存储、组织数据的方式。
算法效率
算法效率是指算法执行的时间,算法执行时间需通过依据该 算法编制的程序在计算机上运行时所消耗的时间来度量。
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
记录的存储位置=f(关键字)
这里的对应关系f称为散列函数,又称为哈希(Hash函数),采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。
数组的特点是:寻址容易,插入和删除困难;
而链表的特点是:寻址困难,插入和删除容易。
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组”,如图:
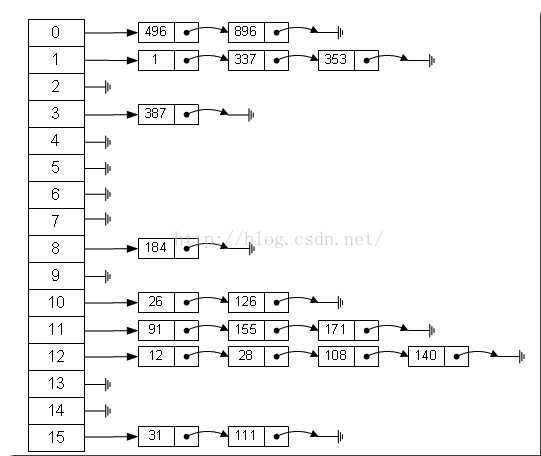
散列表的查找步骤
当存储记录时,通过散列函数计算出记录的散列地址
当查找记录时,我们通过同样的是散列函数计算记录的散列地址,并按此散列地址访问该记录
优缺点
优点:不论哈希表中有多少数据,查找、插入、删除(有时包括删除)只需要接近常量的时间即0(1)的时间级。实际上,这只需要几条机器指令。
哈希表运算得非常快,在计算机程序中,如果需要在一秒种内查找上千条记录通常使用哈希表(例如拼写检查器)哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。哈希表不仅速度快,编程实现也相对容易。
如果不需要有序遍历数据,并且可以提前预测数据量的大小。那么哈希表在速度和易用性方面是无与伦比的。
缺点:它是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,性能下降得非常严重,所以程序员必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程)。
问题解决:软件工程包含程序设计,已经不单单是局限于编写代码,而是应该考虑程序的简洁性,实用性。简单来说,软件工程考虑的要更加全面具体。
问题解决:一个是时间复杂度,一个是渐近时间复杂度。前者是某个算法的时间耗费,它是该算法所求解问题规模n的函数,而后者是指当问题规模趋向无穷大时,该算法时间复杂度的数量级。
当我们评价一个算法的时间性能时,主要标准就是算法的渐近时间复杂度,因此,在算法分析时,往往对两者不予区分,经常是将渐近时间复杂度T(n)=O(f(n))简称为时间复杂度
其中的f(n)一般是算法中频度最大的语句频度。语句频度是一个算法中的语句执行次数。
没有循环的一段程序的复杂度是常数,一层循环的复杂度是O(n),两层循环的复杂度是O(n^2)
问题解决:
语句频度和数据结构中时间复杂度的区别。
1)时间频度一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
(2)时间复杂度在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。在各种不同算法中,若算法中语句执行次数为一个常数,则时间复杂度为O(1),另外,在时间频度不相同时,时间复杂度有可能相同,如T(n)=n^2+3n+4与T(n)=4n^2+2n-1它们的频度不同,但时间复杂度相同,都为O(n2)。
按数量级递增排列,常见的时间复杂度有:常数阶O(1),对数阶O(log2n),线性阶O(n),线性对数阶O(nlog2n),平方阶O(n2),立方阶O(n3),...,k次方阶O(nk),指数阶O(2n)。随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低。
复杂度关系
c < log2N < n < n * Log2N < n^2 < n^3 < 2^n < 3^n < n!
问题解决:答案是0(1),
因为是在表尾插入的,顺序表读取表尾元素是个常量级操作,插入操作无需移动因此也是个常量级操作。
for(int count = 0 ; count < n ; count++)
for(int count2 = 0 ; count2 < n ; count2 = count2 + 2)
{
System.out.println(count,count2);
}
}由题,内层循环是n/2,外层循环是n,所以增长函数f(n) = n^2 /2,所以阶次是O(n^2)。
for(int count = 0 ; count < n ; count++)
for(int count2 = 0 ; count2 < n ; count2 = count2 * 2)
{
System.out.println(count,count2);
}
}由题,内层循环是log2n,外层循环是n,所以增长函数是nlog2n,所以阶次是O(nlog2n)。
标签:创建 定义 开发环境 总结 一周 次数 哈希函数 hash函数 常量
原文地址:https://www.cnblogs.com/gk0625/p/9613957.html