标签:有一个 was info 持久 leader possibly line 决定 16px
redis-cluster是近年来redis架构不断改进中的相对较好的redis高可用方案。本文涉及到近年来redis多实例架构的演变过程,包括普通主从架构(Master、slave可进行写读分离)、哨兵模式下的主从架构、redis-cluster高可用架构(redis官方默认cluster下不进行读写分离)的简介。同时还介绍使用Java的两大redis客户端:Jedis与Lettuce用于读写redis-cluster的数据的一般方法。再通过官方文档以及互联网的相关技术文档,给出redis-cluster架构下的读写能力的优化方案,包括官方的推荐的扩展redis-cluster下的Master数量以及非官方默认的redis-cluster的读写分离方案,案例中使用Lettuce的特定方法进行redis-cluster架构下的数据读写分离。
redis是基于内存的高性能key-value数据库,若要让redis的数据更稳定安全,需要引入多实例以及相关的高可用架构。而近年来redis的高可用架构亦不断改进,先后出现了本地持久化、主从备份、哨兵模式、redis-cluster群集高可用架构等等方案。
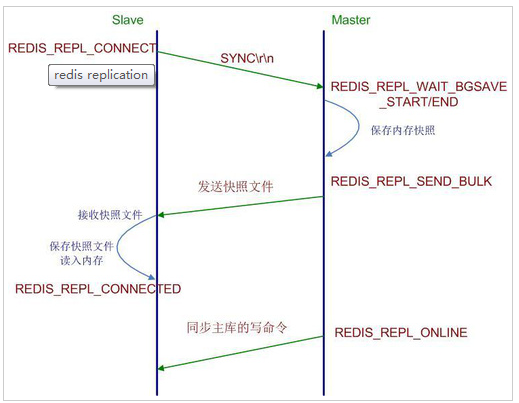
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失)数据,因为持久化会把内存中数据保存到硬盘上,重启会从硬盘上加载数据。 。但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。为此, Redis 提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
在复制的概念中,数据库分为两类,一类是主数据库(master),另一类是从数据库(slave)。主数据库可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库。而从数据库一般是只读的,并接受主数据库同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。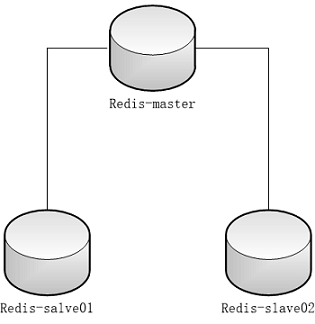
主从模式的配置,一般只需要再作为slave的redis节点的conf文件上加入“slaveof masterip masterport”, 或者作为slave的redis节点启动时使用如下参考命令:
redis-server --port 6380 --slaveof masterIp masterPort
redis的普通主从模式,能较好地避免单独故障问题,以及提出了读写分离,降低了Master节点的压力。互联网上大多数的对redis读写分离的教程,都是基于这一模式或架构下进行的。但实际上这一架构并非是目前最好的redis高可用架构。
主从复制过程见下图
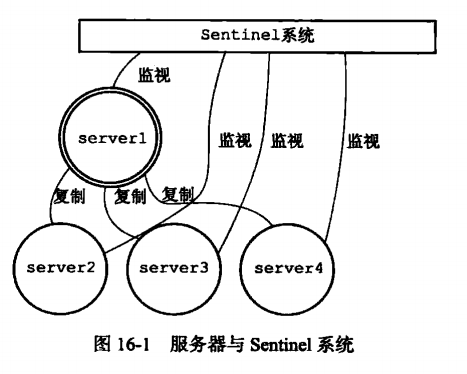
Redis Sentinel 是一个分布式系统, 你可以在一个架构中运行多个 Sentinel 进程(progress), 这些进程使用流言协议(gossip protocols)来接收关于主服务器是否下线的信息, 并使用投票协议(agreement protocols)来决定是否执行自动故障迁移, 以及选择哪个从服务器作为新的主服务器。
可以用info replication查看主从情况 例子: 1主2从 1哨兵,可以用命令起也可以用配置文件里 可以使用双哨兵,更安全,参考命令如下:
redis-server --port 6379
redis-server --port 6380 --slaveof 192.168.0.167 6379
redis-server --port 6381 --slaveof 192.168.0.167 6379
redis-sentinel sentinel.conf
其中,哨兵配置文件sentinel.conf参考如下:
sentinel monitor mymaster 192.168.0.167 6379 1
其中mymaster表示要监控的主数据库的名字。配置哨兵监控一个系统时,只需要配置其监控主数据库即可,哨兵会自动发现所有复制该主数据库的从数据库。
Master与slave的切换过程:
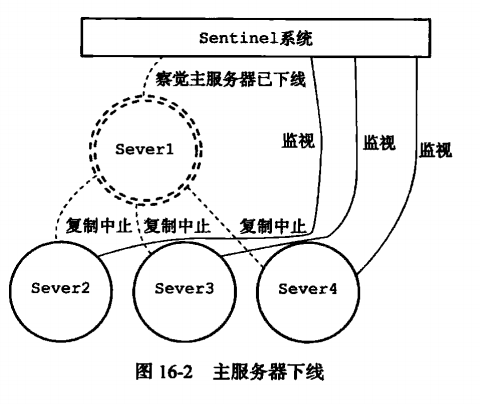
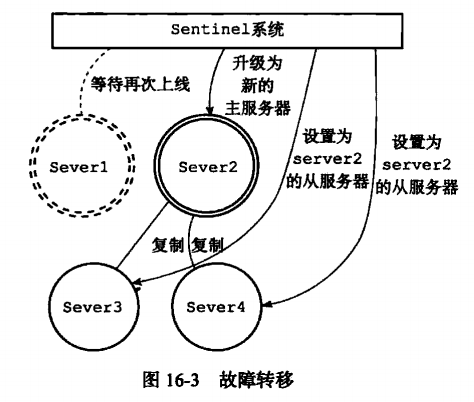
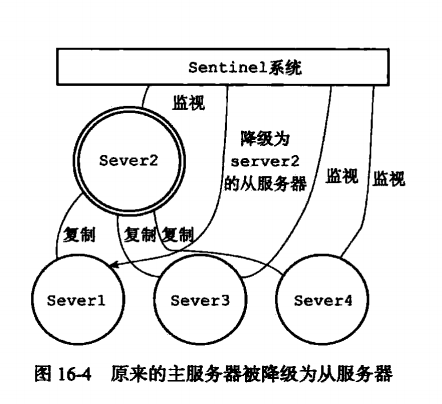
即使使用哨兵,redis每个实例也是全量存储,每个redis存储的内容都是完整的数据,浪费内存且有木桶效应。为了最大化利用内存,可以采用cluster群集,就是分布式存储。即每台redis存储不同的内容。
采用redis-cluster架构正是满足这种分布式存储要求的集群的一种体现。redis-cluster架构中,被设计成共有16384个hash slot。每个master分得一部分slot,其算法为:hash_slot = crc16(key) mod 16384 ,这就找到对应slot。采用hash slot的算法,实际上是解决了redis-cluster架构下,有多个master节点的时候,数据如何分布到这些节点上去。key是可用key,如果有{}则取{}内的作为可用key,否则整个可以是可用key。群集至少需要3主3从,且每个实例使用不同的配置文件。

在redis-cluster架构中,redis-master节点一般用于接收读写,而redis-slave节点则一般只用于备份,其与对应的master拥有相同的slot集合,若某个redis-master意外失效,则再将其对应的slave进行升级为临时redis-master。
在redis的官方文档中,对redis-cluster架构上,有这样的说明:在cluster架构下,默认的,一般redis-master用于接收读写,而redis-slave则用于备份,当有请求是在向slave发起时,会直接重定向到对应key所在的master来处理。但如果不介意读取的是redis-cluster中有可能过期的数据并且对写请求不感兴趣时,则亦可通过readonly命令,将slave设置成可读,然后通过slave获取相关的key,达到读写分离。
具体可以参阅redis官方文档(https://redis.io/commands/readonly)等相关内容:
Enables read queries for a connection to a Redis Cluster slave node. Normally slave nodes will redirect clients to the authoritative master for the hash slot involved in a given command, however clients can use slaves in order to scale reads using the READONLY command. READONLY tells a Redis Cluster slave node that the client is willing to read possibly stale data and is not interested in running write queries. When the connection is in readonly mode, the cluster will send a redirection to the client only if the operation involves keys not served by the slave‘s master node. This may happen because: The client sent a command about hash slots never served by the master of this slave. The cluster was reconfigured (for example resharded) and the slave is no longer able to serve commands for a given hash slot.
例如,我们假设已经建立了一个三主三从的redis-cluster架构,其中A、B、C节点都是redis-master节点,A1、B1、C1节点都是对应的redis-slave节点。在我们只有master节点A,B,C的情况下,对应redis-cluster如果节点B失败,则群集无法继续,因为我们没有办法再在节点B的所具有的约三分之一的hash slot集合范围内提供相对应的slot。然而,如果我们为每个主服务器节点添加一个从服务器节点,以便最终集群由作为主服务器节点的A,B,C以及作为从服务器节点的A1,B1,C1组成,那么如果节点B发生故障,系统能够继续运行。节点B1复制B,并且B失效时,则redis-cluster将促使B的从节点B1作为新的主服务器节点并且将继续正确地操作。但请注意,如果节点B和B1在同一时间发生故障,则Redis群集无法继续运行。
Redis群集配置参数:在继续之前,让我们介绍一下Redis Cluster在redis.conf文件中引入的配置参数。有些命令的意思是显而易见的,有些命令在你阅读下面的解释后才会更加清晰。
以下是最小的Redis集群配置文件:
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
注意:
标签:有一个 was info 持久 leader possibly line 决定 16px
原文地址:https://www.cnblogs.com/kaleidoscope/p/9636264.html