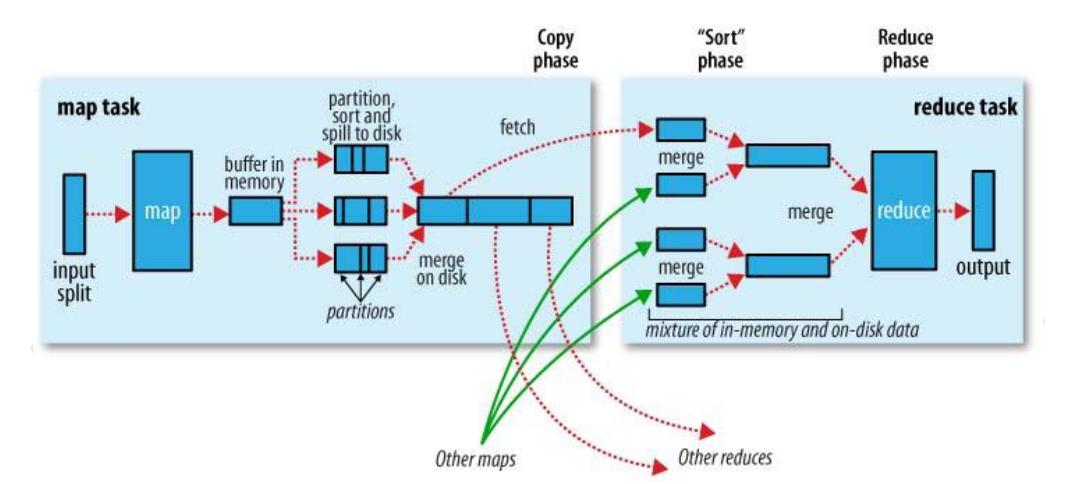
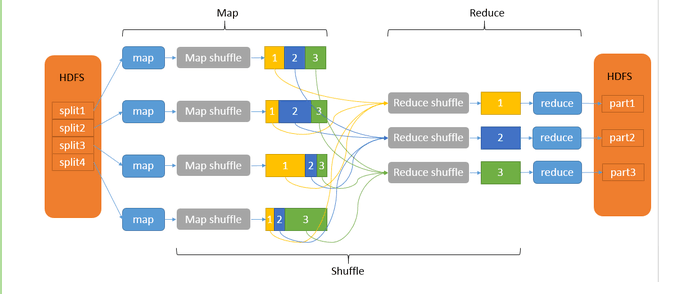
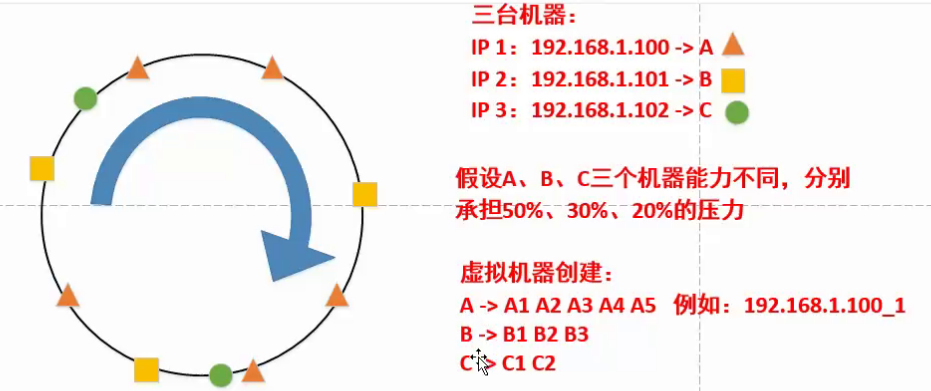
标签:技术分享 情况 方式 利用 备份 分享 写入 同一性 map函数
[Hadoop]浅谈MapReduce原理及执行流程
原文地址:https://www.cnblogs.com/skyell/p/9644072.html