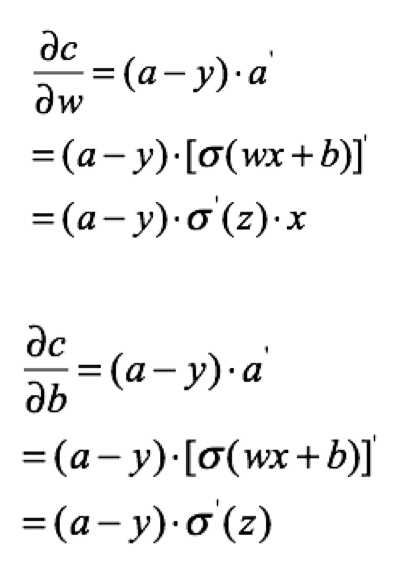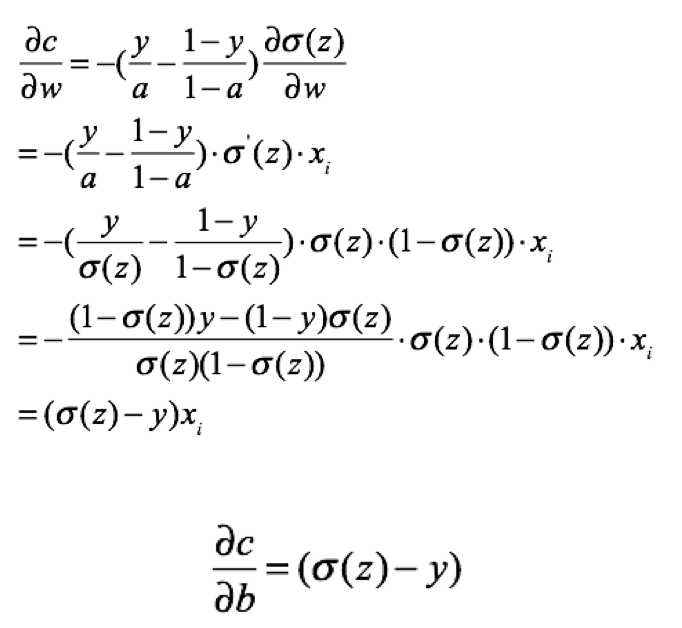标签:训练 -o 技术 最小 https method ase article 16px
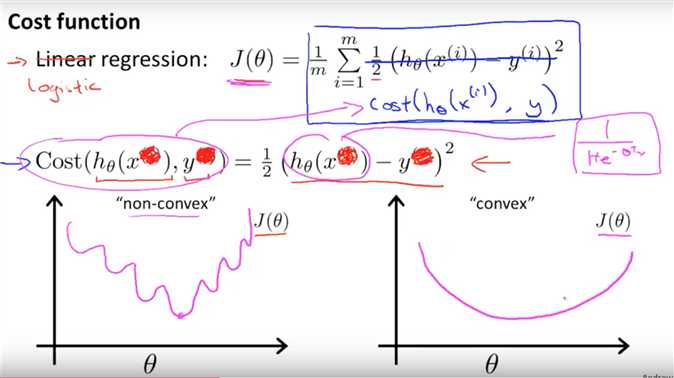
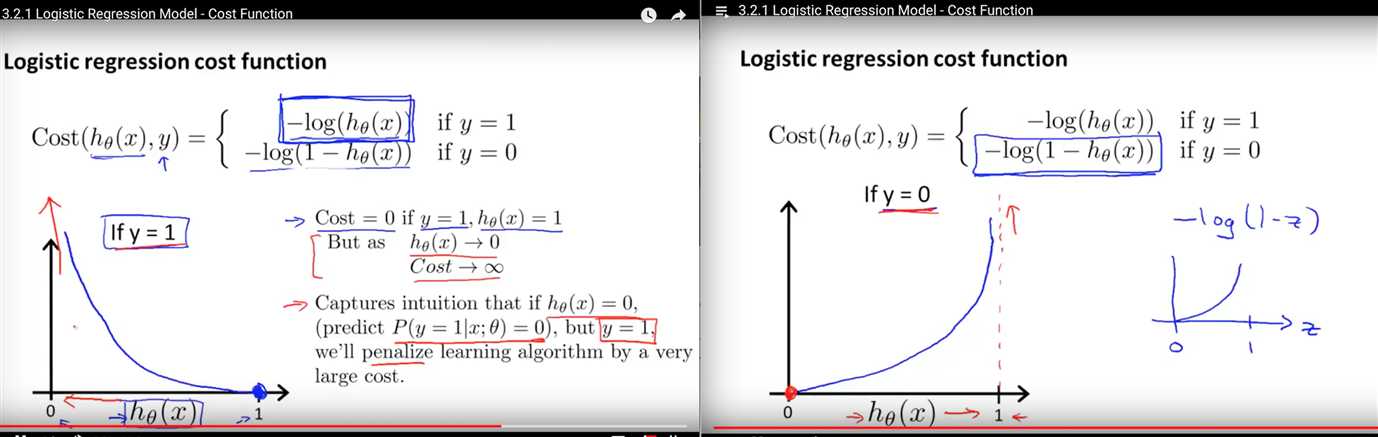
均方误差和交叉熵损失函数比较
原文地址:https://www.cnblogs.com/aijianiula/p/9651879.html