标签:关系 bsp 功能 str apr map 对比 实现 color
回顾MapReduce的计算过程
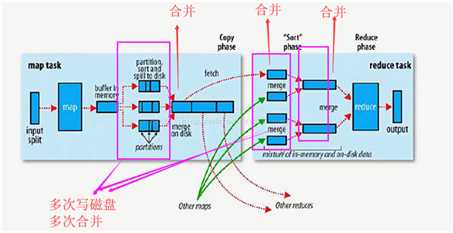
Spark对比MapReduce
Spark是借鉴了MapReduce的思想并在其基础上发展起来的,继承了其分布式计算的优点并改进其缺陷,但两者也有不少的差异如下:
1.spark更快,spark把运行的之间数据存放在内存,迭代计算效率高;mapreduce的之间结果需要落地,保存到磁盘,会产生大量IO操作,影响性能。
2.spark容错性高,通过弹性分布式数据集RDD来实现高效容错,某一部分丢失或出错,可通过计算流程的血缘关系来重建;而mapreduce只能重新计算,成本较高。
3.spark更加通用,提高了丰富的算子(如Transformation和Action),还有流计算Streaming和图计算GraphX等;而mapreduce只有map和reduce两种操作,并不是所有的问题都可以简单地分成map和reduce两步模型来处理。
4.spark采用的是多线程,任务都在一个进程中有利于内存共享,但容易产生资源竞争,难以细粒度地控制资源占用;mapreduce是多进程,进程启动时间要比线程慢,时效不高,但比spark更稳定,值适合批处理操作。
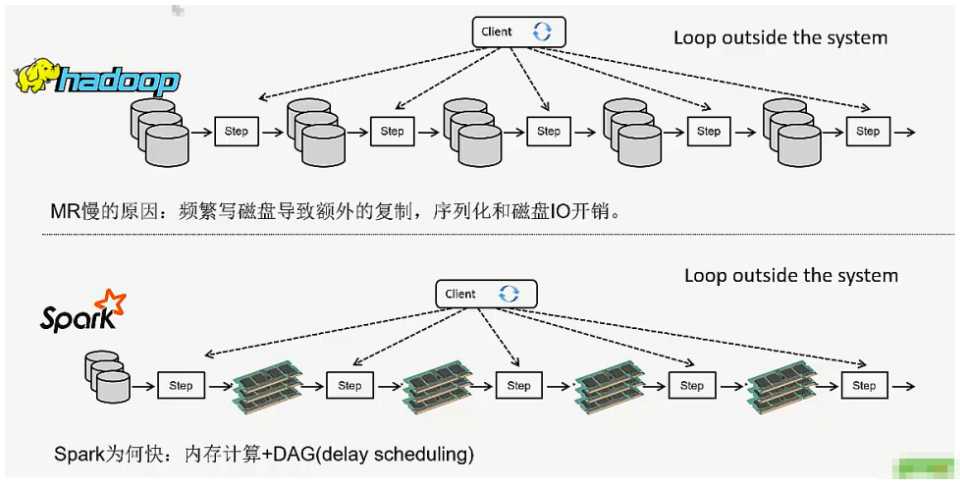
最终总结:
spark生态更为丰富,功能更强大,性能更佳,使用范围广;mapreduce更简单,稳定性好,适合长期后台运行,适合离线海量数据(挖掘)处理。
标签:关系 bsp 功能 str apr map 对比 实现 color
原文地址:https://www.cnblogs.com/liujian-8492/p/9655155.html