标签:9.png 参数 str 池化层 google 深度 通过 增加 技术分享
1*1的卷积核在NIN、Googlenet中被广泛使用,但其到底有什么作用也是一直困扰的问题,这里总结和归纳下在网上查到的自认为很合理的一些答案,包括1)跨通道的特征整合2)特征通道的升维和降维 3)减少卷积核参数(简化模型)
在我学习吴恩达老师Deeplearning.ai深度学习课程的时候,老师在第四讲卷积神经网络第二周深度卷积网络:实例探究的2.5节网络中的网络以及1×1卷积对1×1卷积做了较为详细且通俗易懂的解释。现自己做一下记录。
假设当前输入张量维度为6×6×32,卷积核维度为1×1×32,取输入张量的某一个位置(如图黄色区域)与卷积核进行运算。实际上可以看到,如果把1×1×32卷积核看成是32个权重W,输入张量运算的1×1×32部分为输入x,那么每一个卷积操作相当于一个Wx过程,多个卷积核就是多个神经元,相当于一个全连接网络。
综上,可以将1×1卷积过程看成是将输入张量分为一个个输入为1×1×32的x,他们共享卷积核变量(对应全连接网络的权重)W的全连接网络。
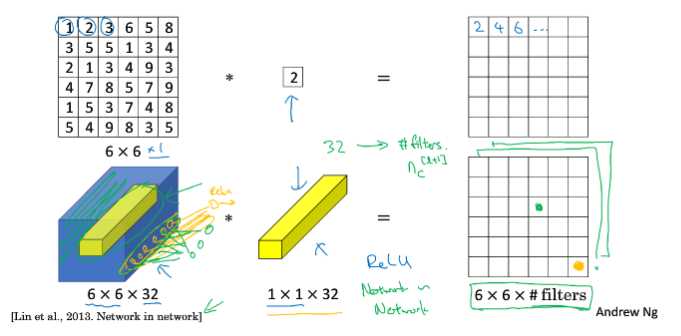
3.1 - 放缩nc的大小
通过控制卷积核的数量达到通道数大小的放缩。而池化层只能改变高度和宽度,无法改变通道数。
如上所述,1×1卷积核的卷积过程相当于全连接层的计算过程,并且还加入了非线性激活函数,从而可以增加网络的非线性,使得网络可以表达更加复杂的特征。
在Inception Network中,由于需要进行较多的卷积运算,计算量很大,可以通过引入1×1确保效果的同时减少计算量。具体可以通过下面例子量化比较
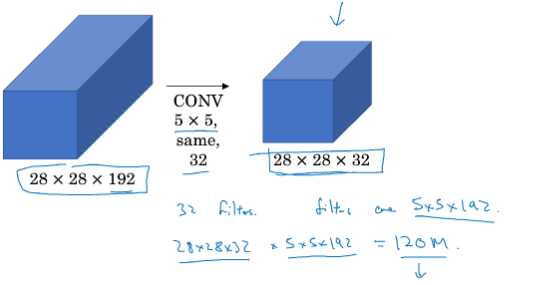
3.3.1 - 不引入1×1卷积的卷积操作
3.3.2 - 引入1×1卷积的卷积操作
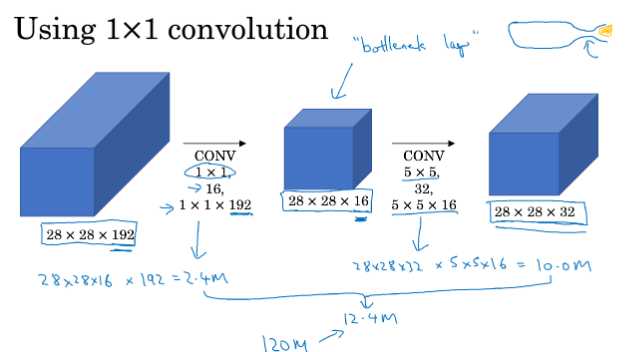
总共需要的计算量为(28×28×16)×(1×1×192)+(28×28×32)×(5×16×16)≈ 12.4 million,明显少于不引入1×1卷积的卷积过程的计算量。其本质我觉得可以理解成,通过1×1卷积操作提取出输入张量的重要特征(相当于降维),然后通过5×5卷积的计算量可以减少很多(减少的比引入1×1卷积所需额外的计算量多多了)。
标签:9.png 参数 str 池化层 google 深度 通过 增加 技术分享
原文地址:https://www.cnblogs.com/tianqizhi/p/9665436.html
{kind=link}