标签:sign hadoop info 添加 core 加载 网络 sci 目标
目录
翻译自《Demo Week: Time Series Machine Learning with h2o and timetk》
原文链接:https://www.business-science.io/code-tools/2017/10/28/demo_week_h2o.html
文字和代码略有删改

h2o 的用途h2o 包是 H2O.ai 提供的产品,包含许多先进的机器学习算法,表现指标和辅助函数,使机器学习功能强大而且容易使用。h2o 的主要优点之一是它可以部署在集群上(今天不会讨论),从 R 的角度来看,有四个主要用途:
我们将讨论如何将 h2o 用作时间序列机器学习的一种高级算法。我们将在本地使用 h2o,在先前关于 timetk 和 sweep 的教程中使用的数据集(beer_sales_tbl)上开发一个高精度的时间序列模型。这是一个监督学习的回归问题。
我们需要三个包:
h2o:机器学习算法包tidyquant:用于获取数据和加载 tidyverse 系列工具timetk:R 中的时间序列工具箱h2o推荐在 ubuntu 环境下安装最新稳定版 h2o。
# Load libraries
library(h2o) # Awesome ML Library
library(timetk) # Toolkit for working with time series in R
library(tidyquant) # Loads tidyverse, financial pkgs, used to get data我们使用 tidyquant 的函数 tq_get(),获取 FRED 的数据——啤酒、红酒和蒸馏酒销售。
# Beer, Wine, Distilled Alcoholic Beverages, in Millions USD
beer_sales_tbl <- tq_get(
"S4248SM144NCEN",
get = "economic.data",
from = "2010-01-01",
to = "2017-10-27")
beer_sales_tbl## # A tibble: 92 x 2
## date price
## <date> <int>
## 1 2010-01-01 6558
## 2 2010-02-01 7481
## 3 2010-03-01 9475
## 4 2010-04-01 9424
## 5 2010-05-01 9351
## 6 2010-06-01 10552
## 7 2010-07-01 9077
## 8 2010-08-01 9273
## 9 2010-09-01 9420
## 10 2010-10-01 9413
## # ... with 82 more rows可视化是一个好主意,我们要知道我们正在使用的是什么数据,这对于时间序列分析和预测尤为重要,并且最好将数据分成训练、测试和验证集。
# Plot Beer Sales with train, validation, and test sets shown
beer_sales_tbl %>%
ggplot(aes(date, price)) +
# Train Region
annotate(
"text",
x = ymd("2012-01-01"), y = 7000,
color = palette_light()[[1]],
label = "Train Region") +
# Validation Region
geom_rect(
xmin = as.numeric(ymd("2016-01-01")),
xmax = as.numeric(ymd("2016-12-31")),
ymin = 0, ymax = Inf, alpha = 0.02,
fill = palette_light()[[3]]) +
annotate(
"text",
x = ymd("2016-07-01"), y = 7000,
color = palette_light()[[1]],
label = "Validation\nRegion") +
# Test Region
geom_rect(
xmin = as.numeric(ymd("2017-01-01")),
xmax = as.numeric(ymd("2017-08-31")),
ymin = 0, ymax = Inf, alpha = 0.02,
fill = palette_light()[[4]]) +
annotate(
"text",
x = ymd("2017-05-01"), y = 7000,
color = palette_light()[[1]],
label = "Test\nRegion") +
# Data
geom_line(col = palette_light()[1]) +
geom_point(col = palette_light()[1]) +
geom_ma(ma_fun = SMA, n = 12, size = 1) +
# Aesthetics
theme_tq() +
scale_x_date(
date_breaks = "1 year",
date_labels = "%Y") +
labs(title = "Beer Sales: 2007 through 2017",
subtitle = "Train, Validation, and Test Sets Shown") 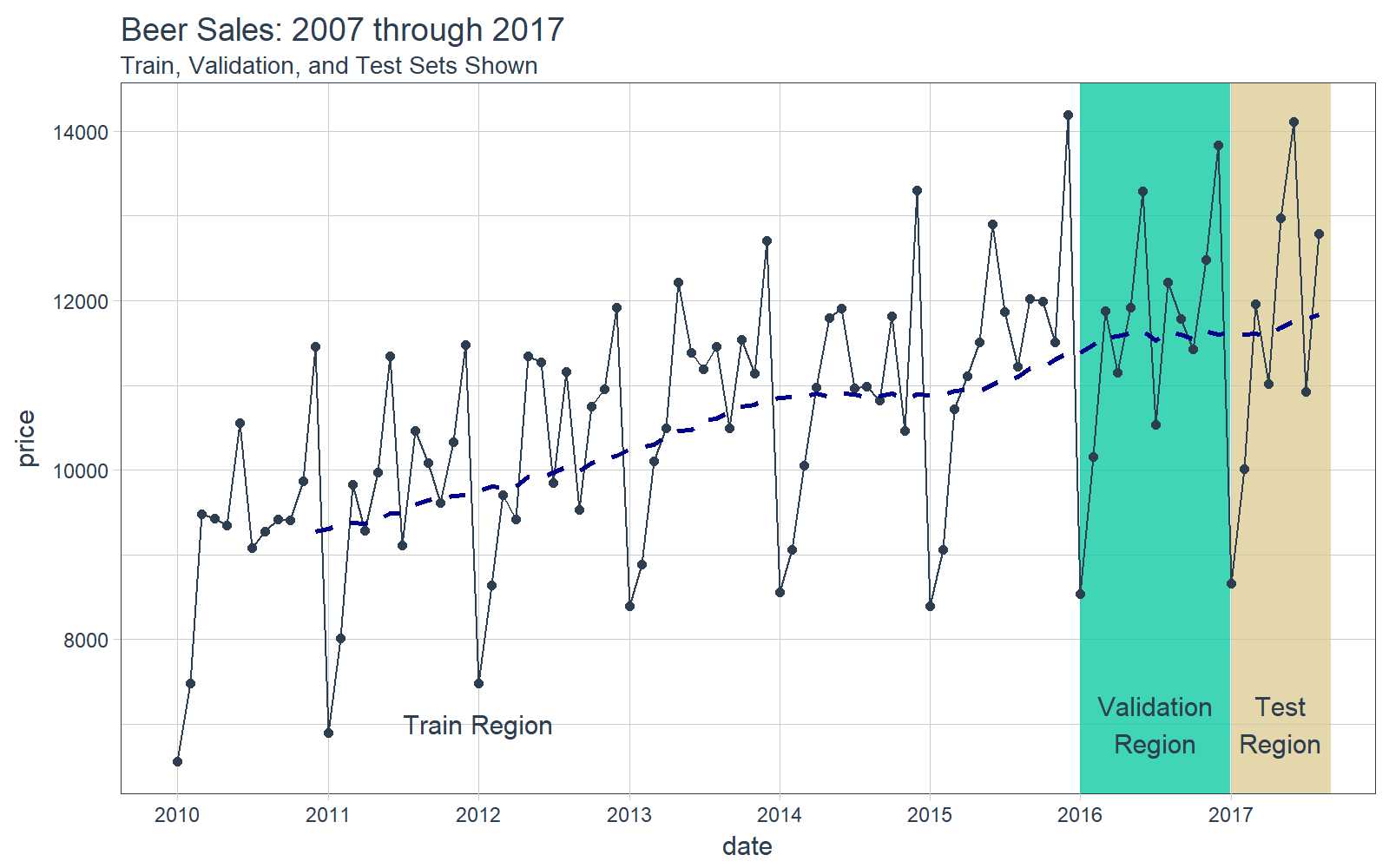
现在我们对数据有了直观的认识,让我们继续吧。
h2o + timetk,时间序列机器学习我们的时间序列机器学习项目遵循的工作流与之前 timetk + 线性回归文章中的类似。但是,这次我们将用 h2o.autoML() 替换 lm() 函数以获得更高的准确性。
时间序列机器学习是预测时间序列数据的好方法,在开始之前,先明确教程的两个关键问题:
timetk + lm() 和 sweep + auto.arima())的预测结果作对比。下面,我们将经历一遍执行时间序列机器学习的工作流。
作为分析的起点,先用 glimpse() 打印出 beer_sales_tbl,获得数据的第一印象。
# Starting point
beer_sales_tbl %>%
glimpse()## Observations: 92
## Variables: 2
## $ date <date> 2010-01-01, 2010-02-01, 2010-03-01, 2010-04-01, 20...
## $ price <int> 6558, 7481, 9475, 9424, 9351, 10552, 9077, 9273, 94...tk_augment_timeseries_signature() 函数将时间戳信息逐列扩展成机器学习所用的特征集,将时间序列信息列添加到原始数据框。再次使用 glimpse() 进行快速检查。现在有了 30 个特征,有些特征很重要,但并非所有特征都重要。
# Augment (adds data frame columns)
beer_sales_tbl_aug <- beer_sales_tbl %>%
tk_augment_timeseries_signature()
beer_sales_tbl_aug %>% glimpse()## Observations: 92
## Variables: 30
## $ date <date> 2010-01-01, 2010-02-01, 2010-03-01, 2010-04-01...
## $ price <int> 6558, 7481, 9475, 9424, 9351, 10552, 9077, 9273...
## $ index.num <int> 1262304000, 1264982400, 1267401600, 1270080000,...
## $ diff <int> NA, 2678400, 2419200, 2678400, 2592000, 2678400...
## $ year <int> 2010, 2010, 2010, 2010, 2010, 2010, 2010, 2010,...
## $ year.iso <int> 2009, 2010, 2010, 2010, 2010, 2010, 2010, 2010,...
## $ half <int> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1,...
## $ quarter <int> 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 1, 1, 1, 2,...
## $ month <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 1, 2, 3,...
## $ month.xts <int> 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 1, 2, ...
## $ month.lbl <ord> January, February, March, April, May, June, Jul...
## $ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ hour <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ minute <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ second <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ hour12 <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ am.pm <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ wday <int> 6, 2, 2, 5, 7, 3, 5, 1, 4, 6, 2, 4, 7, 3, 3, 6,...
## $ wday.xts <int> 5, 1, 1, 4, 6, 2, 4, 0, 3, 5, 1, 3, 6, 2, 2, 5,...
## $ wday.lbl <ord> Friday, Monday, Monday, Thursday, Saturday, Tue...
## $ mday <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ qday <int> 1, 32, 60, 1, 31, 62, 1, 32, 63, 1, 32, 62, 1, ...
## $ yday <int> 1, 32, 60, 91, 121, 152, 182, 213, 244, 274, 30...
## $ mweek <int> 5, 6, 5, 5, 5, 6, 5, 5, 5, 5, 6, 5, 5, 6, 5, 5,...
## $ week <int> 1, 5, 9, 13, 18, 22, 26, 31, 35, 40, 44, 48, 1,...
## $ week.iso <int> 53, 5, 9, 13, 17, 22, 26, 30, 35, 39, 44, 48, 5...
## $ week2 <int> 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1,...
## $ week3 <int> 1, 2, 0, 1, 0, 1, 2, 1, 2, 1, 2, 0, 1, 2, 0, 1,...
## $ week4 <int> 1, 1, 1, 1, 2, 2, 2, 3, 3, 0, 0, 0, 1, 1, 1, 1,...
## $ mday7 <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...h2o 准备数据我们需要以 h2o 的格式准备数据。首先,让我们删除任何不必要的列,如日期列或存在缺失值的列,并将有序类型的数据更改为普通因子。我们推荐用 dplyr 操作这些步骤。
beer_sales_tbl_clean <- beer_sales_tbl_aug %>%
select_if(~ !is.Date(.)) %>%
select_if(~ !any(is.na(.))) %>%
mutate_if(is.ordered, ~ as.character(.) %>% as.factor)
beer_sales_tbl_clean %>% glimpse()## Observations: 92
## Variables: 28
## $ price <int> 6558, 7481, 9475, 9424, 9351, 10552, 9077, 9273...
## $ index.num <int> 1262304000, 1264982400, 1267401600, 1270080000,...
## $ year <int> 2010, 2010, 2010, 2010, 2010, 2010, 2010, 2010,...
## $ year.iso <int> 2009, 2010, 2010, 2010, 2010, 2010, 2010, 2010,...
## $ half <int> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1,...
## $ quarter <int> 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 1, 1, 1, 2,...
## $ month <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 1, 2, 3,...
## $ month.xts <int> 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 1, 2, ...
## $ month.lbl <fctr> January, February, March, April, May, June, Ju...
## $ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ hour <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ minute <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ second <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ hour12 <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ am.pm <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ wday <int> 6, 2, 2, 5, 7, 3, 5, 1, 4, 6, 2, 4, 7, 3, 3, 6,...
## $ wday.xts <int> 5, 1, 1, 4, 6, 2, 4, 0, 3, 5, 1, 3, 6, 2, 2, 5,...
## $ wday.lbl <fctr> Friday, Monday, Monday, Thursday, Saturday, Tu...
## $ mday <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ qday <int> 1, 32, 60, 1, 31, 62, 1, 32, 63, 1, 32, 62, 1, ...
## $ yday <int> 1, 32, 60, 91, 121, 152, 182, 213, 244, 274, 30...
## $ mweek <int> 5, 6, 5, 5, 5, 6, 5, 5, 5, 5, 6, 5, 5, 6, 5, 5,...
## $ week <int> 1, 5, 9, 13, 18, 22, 26, 31, 35, 40, 44, 48, 1,...
## $ week.iso <int> 53, 5, 9, 13, 17, 22, 26, 30, 35, 39, 44, 48, 5...
## $ week2 <int> 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1,...
## $ week3 <int> 1, 2, 0, 1, 0, 1, 2, 1, 2, 1, 2, 0, 1, 2, 0, 1,...
## $ week4 <int> 1, 1, 1, 1, 2, 2, 2, 3, 3, 0, 0, 0, 1, 1, 1, 1,...
## $ mday7 <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...让我们在可视化之前按照时间范围将数据分成训练、验证和测试集。
# Split into training, validation and test sets
train_tbl <- beer_sales_tbl_clean %>% filter(year < 2016)
valid_tbl <- beer_sales_tbl_clean %>% filter(year == 2016)
test_tbl <- beer_sales_tbl_clean %>% filter(year == 2017)h2o 模型首先,启动 h2o。这将初始化 h2o 使用的 java 虚拟机。
h2o.init() # Fire up h2o## Connection successful!
##
## R is connected to the H2O cluster:
## H2O cluster uptime: 46 minutes 4 seconds
## H2O cluster version: 3.14.0.3
## H2O cluster version age: 1 month and 5 days
## H2O cluster name: H2O_started_from_R_mdancho_pcs046
## H2O cluster total nodes: 1
## H2O cluster total memory: 3.51 GB
## H2O cluster total cores: 4
## H2O cluster allowed cores: 4
## H2O cluster healthy: TRUE
## H2O Connection ip: localhost
## H2O Connection port: 54321
## H2O Connection proxy: NA
## H2O Internal Security: FALSE
## H2O API Extensions: Algos, AutoML, Core V3, Core V4
## R Version: R version 3.4.1 (2017-06-30)h2o.no_progress() # Turn off progress bars将数据转成 H2OFrame 对象,使得 h2o 包可以读取。
# Convert to H2OFrame objects
train_h2o <- as.h2o(train_tbl)
valid_h2o <- as.h2o(valid_tbl)
test_h2o <- as.h2o(test_tbl)为目标和预测变量命名。
# Set names for h2o
y <- "price"
x <- setdiff(names(train_h2o), y)我们将使用 h2o.automl,在数据上尝试任何回归模型。
x = x:特征列的名字y = y:目标列的名字training_frame = train_h2o:训练集,包括 2010 - 2016 年的数据validation_frame = valid_h2o:验证集,包括 2016 年的数据,用于避免模型的过度拟合leaderboard_frame = test_h2o:模型基于测试集上 MAE 的表现排序max_runtime_secs = 60:设置这个参数用于加速 h2o 模型计算。算法背后有大量复杂模型需要计算,所以我们以牺牲精度为代价,保证模型可以正常运转。stopping_metric = "deviance":把偏离度作为停止指标,这可以改善结果的 MAPE。# linear regression model used, but can use any model
automl_models_h2o <- h2o.automl(
x = x,
y = y,
training_frame = train_h2o,
validation_frame = valid_h2o,
leaderboard_frame = test_h2o,
max_runtime_secs = 60,
stopping_metric = "deviance")接着,提取主模型。
# Extract leader model
automl_leader <- automl_models_h2o@leader使用 h2o.predict() 在测试数据上产生预测。
pred_h2o <- h2o.predict(
automl_leader, newdata = test_h2o)有几种方法可以评估模型表现,这里,将通过简单的方法,即 h2o.performance()。这产生了预设值,这些预设值通常用于比较回归模型,包括均方根误差(RMSE)和平均绝对误差(MAE)。
h2o.performance(
automl_leader, newdata = test_h2o)## H2ORegressionMetrics: gbm
##
## MSE: 340918.3
## RMSE: 583.8821
## MAE: 467.8388
## RMSLE: 0.04844583
## Mean Residual Deviance : 340918.3我们偏好的评估指标是平均绝对百分比误差(MAPE),未包括在上面。但是,我们可以轻易计算出来。我们可以查看测试集上的误差(实际值 vs 预测值)。
# Investigate test error
error_tbl <- beer_sales_tbl %>%
filter(lubridate::year(date) == 2017) %>%
add_column(
pred = pred_h2o %>% as.tibble() %>% pull(predict)) %>%
rename(actual = price) %>%
mutate(
error = actual - pred,
error_pct = error / actual)
error_tbl## # A tibble: 8 x 5
## date actual pred error error_pct
## <date> <int> <dbl> <dbl> <dbl>
## 1 2017-01-01 8664 8241.261 422.7386 0.048792541
## 2 2017-02-01 10017 9495.047 521.9534 0.052106763
## 3 2017-03-01 11960 11631.327 328.6726 0.027480989
## 4 2017-04-01 11019 10716.038 302.9619 0.027494498
## 5 2017-05-01 12971 13081.857 -110.8568 -0.008546509
## 6 2017-06-01 14113 12796.170 1316.8296 0.093306142
## 7 2017-07-01 10928 10727.804 200.1962 0.018319563
## 8 2017-08-01 12788 12249.498 538.5016 0.042109915为了比较,我们计算了一些残差度量指标。
error_tbl %>%
summarise(
me = mean(error),
rmse = mean(error^2)^0.5,
mae = mean(abs(error)),
mape = mean(abs(error_pct)),
mpe = mean(error_pct)) %>%
glimpse()## Observations: 1
## Variables: 5
## $ me <dbl> 440.1246
## $ rmse <dbl> 583.8821
## $ mae <dbl> 467.8388
## $ mape <dbl> 0.03976961
## $ mpe <dbl> 0.03763299最后,可视化我们得到的预测结果。
beer_sales_tbl %>%
ggplot(aes(x = date, y = price)) +
# Data - Spooky Orange
geom_point(col = palette_light()[1]) +
geom_line(col = palette_light()[1]) +
geom_ma(
n = 12) +
# Predictions - Spooky Purple
geom_point(
aes(y = pred),
col = palette_light()[2],
data = error_tbl) +
geom_line(
aes(y = pred),
col = palette_light()[2],
data = error_tbl) +
# Aesthetics
theme_tq() +
labs(
title = "Beer Sales Forecast: h2o + timetk",
subtitle = "H2O had highest accuracy, MAPE = 3.9%")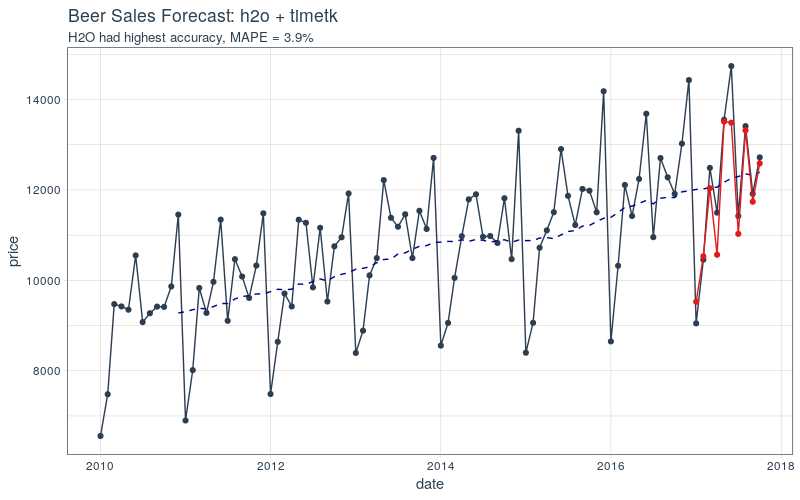
h2o + timetk 的 MAPE 优于先前两个教程中的方法:
感兴趣的读者要问一个问题:对所有三种不同方法的预测进行平均时,准确度会发生什么变化?
请注意,时间序列机器学习的准确性可能并不总是优于 ARIMA 和其他预测技术,包括那些由 prophet(Facebook 开发的预测工具)和 GARCH 方法实现的技术。数据科学家有责任测试不同的方法并为工作选择合适的工具。
标签:sign hadoop info 添加 core 加载 网络 sci 目标
原文地址:https://www.cnblogs.com/xuruilong100/p/9672214.html