标签:意图 允许 因子 元素 赋值 dde col extend 表结构
HashMap简介:
HashMap实现了Map接口,同时是基于哈希表的,允许存放null键和null值。HashMap和Hashtable相差无几,唯一的几点区别就是:HashMap是非线程安全的,而Hashtable是线程安全的(方法都用synchronized关键字进行修饰)。Hashtable不允许存放null键和null值。HashMap不能保证元素的存放顺序,是无序的。
当多个线程并发地访问HashMap时,就算只有一个线程修改了其结构(增加或删除键值对才算,改变键对应的值不算),必须对HashMap进行同步处理,否则会引发线程安全问题。
如果没有同步对象,最好在开始之前使用Collections.synchronizedMap方法进行同步处理,防止非线程安全情况发生,示例如下:
Map m = Collections.synchronizedMap(new HashMap(…));
当多个线程同时访问迭代器iterator时,若一个正在修改iterator,一个正在使用iteartor,将抛出ConcurrentModificationException。
HashMap定义:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
HashMap底层结构示意图(数组+链表结构,针对jdk1.7):
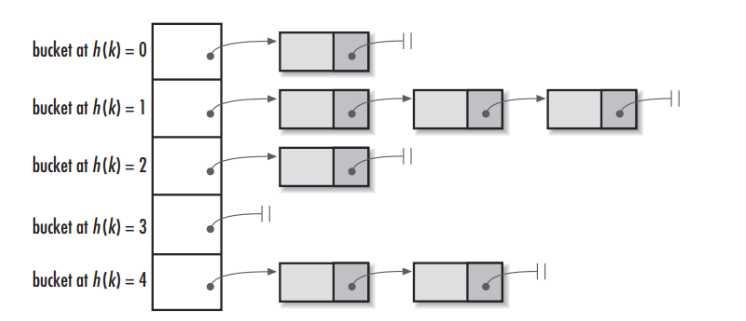
重要属性:
默认加载因子:
static final float DEFAULT_LOAD_FACTOR = 0.75f;
默认初始容量(必须是2的n次方,后面会解释):
static final int DEFAULT_INITIAL_CAPACITY = 16;
最大容量:
static final int MAXIMUM_CAPACITY = 1 << 30;
阈值(计算公式:threshold = capacity * load factor):
int threshold;
重要方法:(针对jdk1.7)
带参的构造函数:
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0)//初始容量若小于0,则抛出非法的初始容量异常 throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY)//若初始容量超过最大容量,默认赋值最大容量 initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor))//加载因子若不大于0或者非浮点数,则抛出非法加载因子异常 throw new IllegalArgumentException("Illegal load factor: " + loadFactor); // Find a power of 2 >= initialCapacity int capacity = 1; while (capacity < initialCapacity) capacity <<= 1; this.loadFactor = loadFactor; threshold = (int)(capacity * loadFactor);//阈值计算 table = new Entry[capacity]; init(); }
计算哈希值所在的数组索引:
该方法是为了计算哈希值对应的数组索引位置,本来是可以用h%length来实现的,但是&的效率要比%稍高一些,所以采用&来实现。
而只有length是2的n次方时,才满足h%length = h&(length-1),所以HahsMap的长度都是2的n次方倍,这个也解决了上面提到的容量为什么必须得2的n次方问题。
static int indexFor(int h, int length) { return h & (length-1); }
get方法(返回key对应的value):
public V get(Object key) { if (key == null)//key为null处理 return getForNullKey();
//先计算key对应的哈希值,然后再对该值进行哈希操作,得到的结果用于查找key对应的table数组位置 int hash = hash(key.hashCode()); for (Entry<K,V> e = table[indexFor(hash, table.length)];//遍历key对应的table数组索引处的Entry链表 e != null; e = e.next) { Object k;
//若key和某个Entry的key相同,则返回该Entry的value值 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null;//无对应值,返回null }
put方法(添加键值对):
public V put(K key, V value) { if (key == null)//key是null处理 return putForNullKey(value); int hash = hash(key.hashCode());//先计算key对应的哈希值,然后再对该值进行哈希操作, int i = indexFor(hash, table.length);//得到的结果用于计算对应键值对存放的位置 for (Entry<K,V> e = table[i]; e != null; e = e.next) {//遍历table数组该索引处的Entry链表 Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {//若存在key相同的,则用新值替换旧值 V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++;//修改计算+1 addEntry(hash, key, value, i);//添加Entry return null; }
addEntry方法(将包含特定key、value、hash值的新Entry添加到特定的桶上):
void addEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); if (size++ >= threshold)//若键值对长度超过阈值,则将HashMap扩容2倍 resize(2 * table.length); }
程序示例:
package com.abc; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Map.Entry; import java.util.Set; /** * @date: 2018/09/19 * @author: alan * */ public class HashMapTest { public static void main(String[] args) { Map<Integer, String> map = new HashMap<>();//实例化HashMap map.put(1, "apple");//添加元素 map.put(2, "banana"); map.put(3, "watermelon"); System.out.println("HashMap‘s size is : " + map.size()); //foreach遍历map Set<Map.Entry<Integer, String>> entrySet = map.entrySet(); for (Map.Entry<Integer, String> entry : entrySet) { int key = entry.getKey(); String value = entry.getValue(); System.out.println("key is " + key + ", value is " + value); } System.out.println("============================"); //使用迭代器Iterator遍历map Iterator iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<Integer, String> entry = (Map.Entry)iterator.next(); int key = entry.getKey(); String value = entry.getValue(); System.out.println("key is " + key + ", value is " + value); } } }
控制台输出:
HashMap‘s size is : 3 key is 1, value is apple key is 2, value is banana key is 3, value is watermelon ============================ key is 1, value is apple key is 2, value is banana key is 3, value is watermelon
注:本文为原创,转载请附带链接:https://www.cnblogs.com/stm32stm32/p/9675722.html
标签:意图 允许 因子 元素 赋值 dde col extend 表结构
原文地址:https://www.cnblogs.com/stm32stm32/p/9675722.html