标签:时间 执行器 特点 引擎 isp 生态 主机 故障切换 操作
作者:李树桓 个推数据研发工程师
前言:近年来,互联网的快速发展积累了海量大数据,而在这些大数据的处理上,不同技术栈所具备的性能也有所不同,如何快速有效地处理这些庞大的数据仓,成为很多运营者为之苦恼的问题!随着Greenplum的异军突起,以往大数据仓库所面临的很多问题都得到了有效解决,Greenplum也成为新一代海量数据处理典型代表。本文结合个推数据研发工程师李树桓在大数据领域的实践,对处理庞大的数据量时,如何选择有效的技术栈做了深入研究,探索出Greenplum是当前处理大数据仓较为高效稳定的利器。
一、Greenplum诞生的背景
时间回到2002年,那时整个互联网数据量正处于快速增长期,一方面传统数据库难以满足当前的计算需求,另一方面传统数据库大多基于SMP架构,这种架构最大的一个特点是共享所有资源,扩展性能差,因此面对日益增长的数据量,难以继续支撑,需要一种具有分布式并行数据计算能力的数据库,Greenplum正是在此背景下诞生了。
和传统数据库的SMP架构不同,Greenplum主要基于MPP架构,这是由多个服务器通过节点互联网络连接而成的系统,每个节点只访问自己的本地资源(包括内存、存储等),是一种完全无共享(Share Nothing)结构,扩展能力较之前有明显提升。
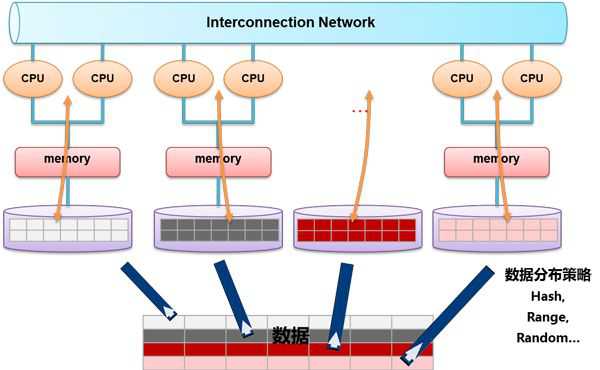
二、解读 Greenplum架构
Greenplum主要由Master主节点和Interconnect网络层以及负责数据存储和计算的多个节点共同组成。
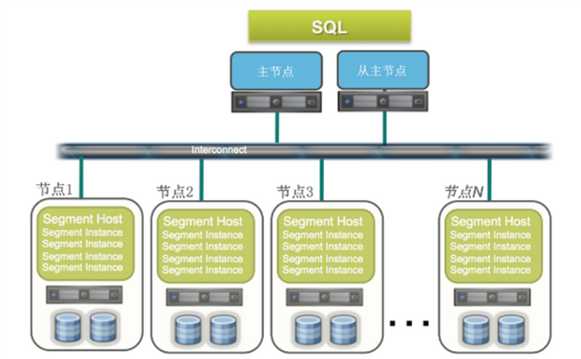
Master上有主节点和从节点两部分,两者主要的功能是生成查询计划并派发,以及协调Segment并行计算,同时在Master上保存着global system catalog,这个全局目录存着一组Greenplum数据库系统本身所具有的元数据的系统表。需要说明的是Master本身不参与数据交互,Greenplum所有的并行任务都是在Segment的数据节点上完成的,因此,Master节点不会成为数据库的性能瓶颈。
中间的网络层Interconnect,主要负责并行查询计划生产和Dispatch分发以及协调节点上QE执行器的并行工作, 正是因为Interconnect的存在,Greenplum才能实现对同一个集群中多个PostgreSQL实例的高效协同和并行计算。
整个结构图下方负责数据存储和计算的每个节点上又有多个实例,每个实例都是一个PostgreSQL数据库,这些实例共享节点的IO和CPU。PostgreSQL在稳定性和性能方面较为先进,同时又有丰富的语法支持,满足了Greenplum的功能需要。
三、了解Greenplum优势
Greenplum之所以能成为处理海量大数据的有效工具,与其所具备的几大优势密不可分。
优势一:计算效率提升
Greenplum的数据管道可以高效地将数据从磁盘传输到CPU,而目前市面上常用的计算引擎SPARK在传输数据时,则需要为每个并发查询分配一个内存,这对大型数据集的查询十分不利,而Greenplum所具备的实时查询功能,能够有效对大数据集进行计算。
优势二:扩展性能增强
Greenplum基于的MPP架构,节点之间完全不共享,同时又可以达到并行查询,因此在进行线性扩展时,数据规模可以达到PB级别。目前,Greenplum已经实现了开源,并且社区生态活跃,对于使用者而言,也会觉得更为可靠。
优势三:功能性优化
Greenplum可以支持复杂的SQL查询,大幅简化了数据的操作和交互过程。而目前流行的HAWQ、Spark SQL、Impala等技术基本都基于MapReduce进行的优化,虽然部分也使用了SQL查询,但是对SQL的支持十分有限。
四、Greenplum的容错机制
Greenplum数据库简称GPDB,它拥有丰富的特性,支持多级容错机制和高可用。
1)主节点高可用:为了避免主节点单点故障,特别设置一个主节点的副本(称为 Standby Master),通过流复制技术实现两者同步复制,当主节点发生故障时,从节点可以成为主节点,从而完成用户请求并协调查询执行。
2)数据节点高可用:每个数据节点都可以配备一个镜像,它们之间通过文件操作级别的同步来实现数据的同步复制(称为filerep技术)。故障检测进程(ftsprobe)会定期发送心跳给各个数据节点,当某个节点发生故障时,GPDB会自动进行故障切换。
3)网络高可用:为了避免网络的单点故障,每个主机会配置多个网口,并使用多个交换机,避免网络故障时造成整个服务器不可用。
同时,GPDB具有图形化的性能监控功能,基于此功能,用户可以确定数据库当前的运行情况和历史查询信息,同时跟踪系统使用情况和资源信息。
五、 Greenplum在业务场景中的应用
个推在大数据领域深耕多年,在处理庞大的数据仓的过程中,也在不断进行优化和更新技术栈,在进行技术选型时,针对不同的技术栈做了如下对比:
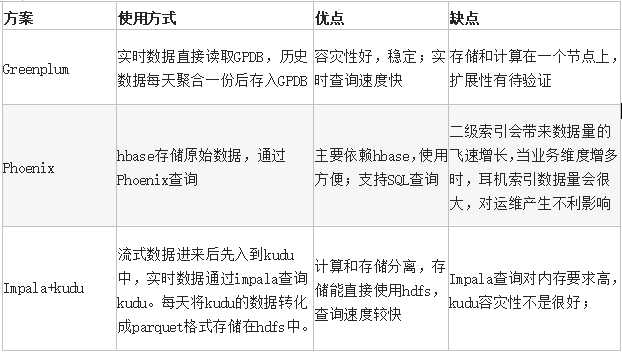
总得来说,Greenplum帮助开发者有效解决了处理数据库时遇到的一些难点,比如跨天去重、用户自定义维度、复杂的SQL查询等问题,同时,也方便开发者直接在原始数据上进行实时查询,减少了数据聚合过程中的遗失,当然,强大的Greenplum仍存在着一些问题需要去完善,例如在节点扩展的过程中元数据的管理问题,分布式数据库在扩展节点时会带来数据一致性,扩展的过程中有时会出现元数据混乱的情况等等,好在Greenplum有很多优秀的运维工具,能够帮我们在发生问题及时进行排查,更好的保障业务的稳定性。但是,尽管Greenplum在处理大数据方面的优势比较明显,对开发者来说,还是要根据自身需求选择相应的技术栈。
数据量越发庞大怎么办?新一代数据处理利器Greenplum来助攻
标签:时间 执行器 特点 引擎 isp 生态 主机 故障切换 操作
原文地址:https://www.cnblogs.com/evakang/p/9676552.html