标签:spark 离线处理 bat val roc 集成 交互式 cond java
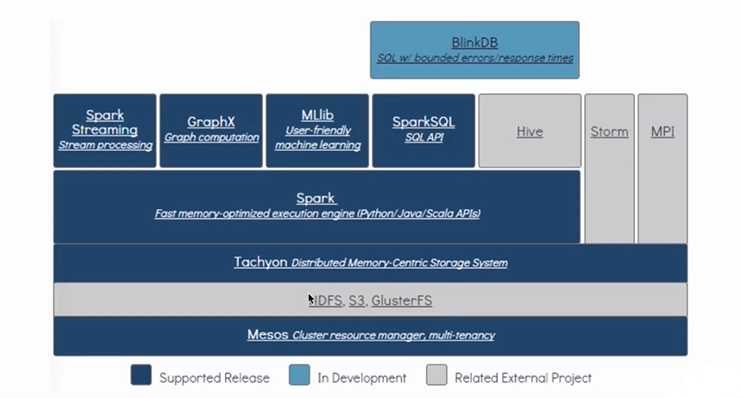

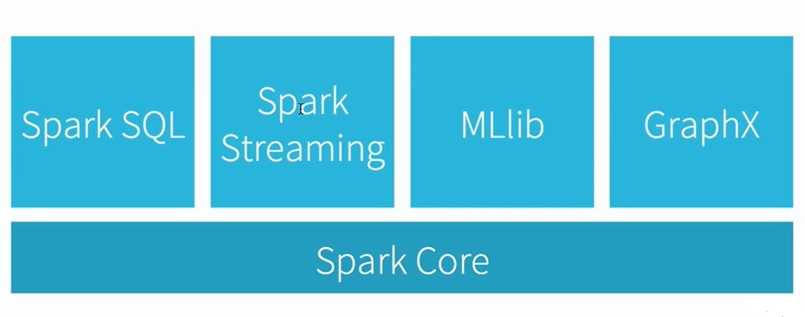
Spark生态的组件,他们都是依托Spark Core进行各自的扩展,那么Spark Streaming如何与各组件间调用呢?
//Create data set from Hadoop file
val dataset = sparkContext.hadoopFile("file")
//Join each batch in stream with the dataset
//kafka数据 => RDD
kafkaStream.transform(batchRDD => {
batchRDD.join(dataset).filter(...)
})
//Learn model offline
val model = KMeans.train(dataset, ...)
//Apply model online on stream
kafkaStream.map(event => {
model.predict(event.featrue)
})//Register each batch in stream as table
kafkaStream.map(batchRDD => {
batchRDD.registerTempTable("latestEvents")
})
//interactively query table
sqlContext.sql("SELECT * FROM latestEvents")./spark-submit --master local[2] --class org.apache.spark.examples.streaming.NetworkWordCount /usr/local/spark/examples/jars/spark-examples.jar [args1] [args2]import org.apache.spark.streaming.{Seconds, StreamingContext}
val ssc = new StreamingContext(sc, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val wordCounts = lines.flatMap(_.split(" ")).map(x => (x, 1)).recudeByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()#向端口发送消息
nc -lk 9999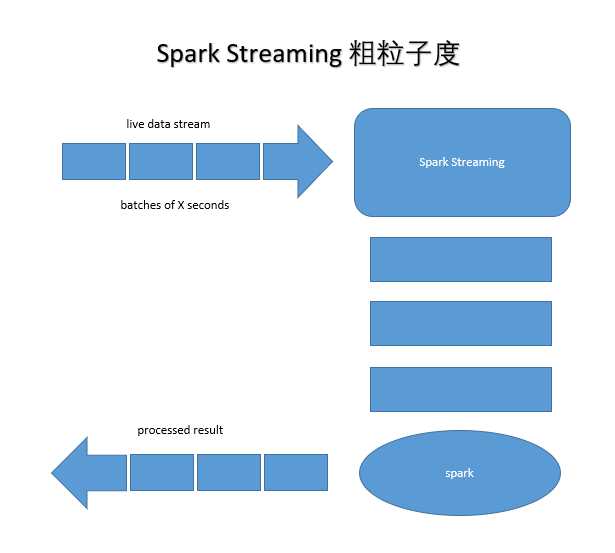
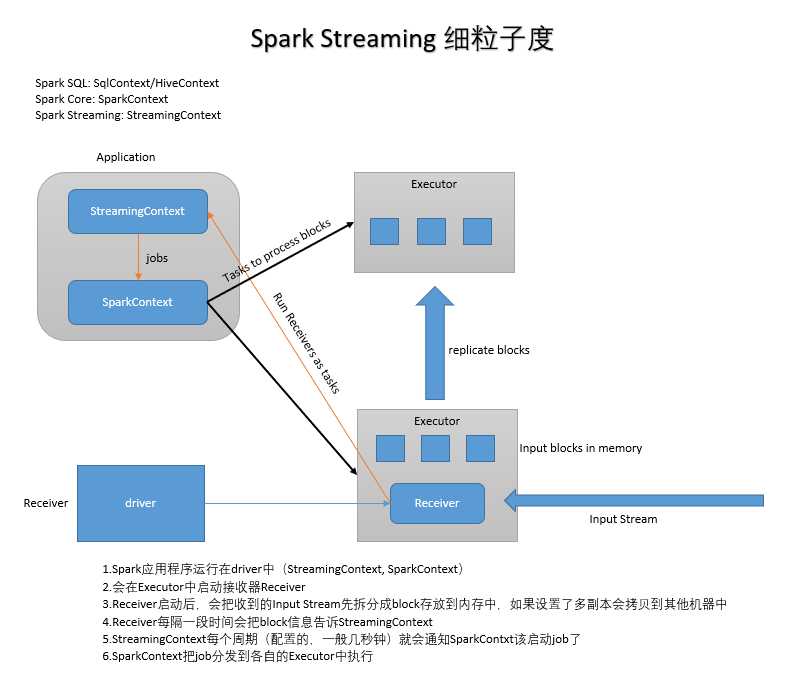
标签:spark 离线处理 bat val roc 集成 交互式 cond java
原文地址:https://www.cnblogs.com/uzies/p/9678230.html