标签:legend nump 想法 生成 dataframe minus style numpy params
import pandas as pd #数据分析
import numpy as np #科学计算
from pandas import Series,DataFrame
data_train = pd.read_csv("Train.csv")
data_train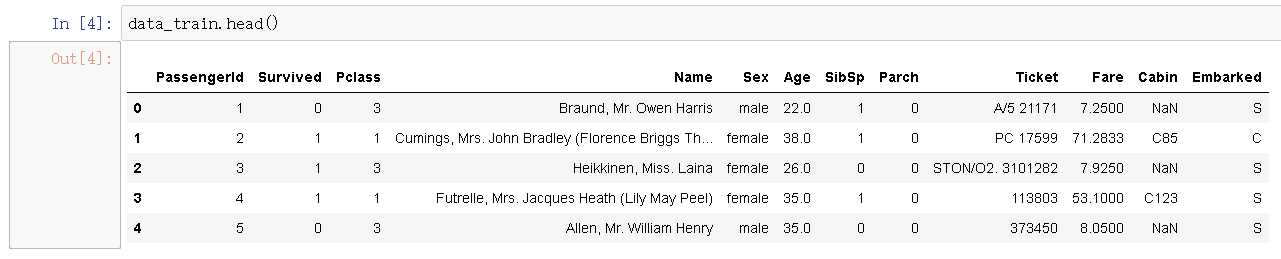
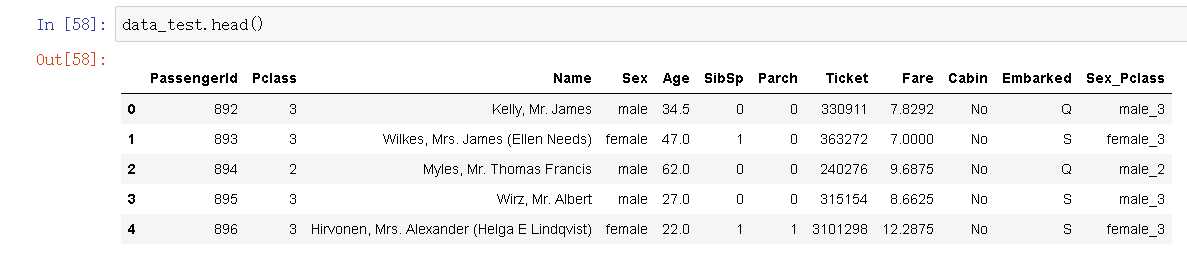
弄清楚数据集的数据条数和各列信息的完整性:
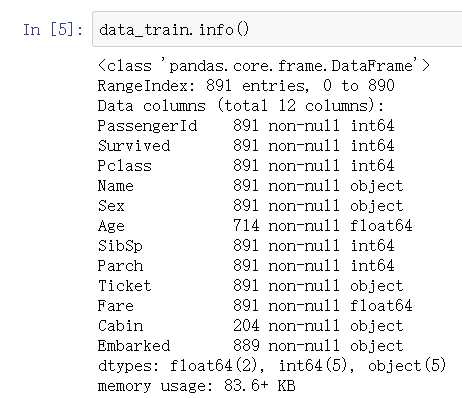
了解数据集各列的统计信息(针对数值型数据):
import matplotlib.pyplot as plt
fig = plt.figure()
from pylab import mpl
mpl.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 雅黑字体
mpl.rcParams[‘axes.unicode_minus‘] = False
fig.set(alpha=0.5) # 设定图表颜色alpha参数
plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图
data_train.Survived.value_counts().plot(kind=‘bar‘)# plots a bar graph of those who surived vs those who did not.
plt.title(u"获救情况 (1为获救)") # puts a title on our graph
plt.ylabel(u"人数")
plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")
plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年龄") # sets the y axis lable
plt.grid(b=True, which=‘major‘, axis=‘y‘) # formats the grid line style of our graphs
plt.title(u"按年龄看获救分布 (1为获救)")
plt.subplot2grid((2,3),(1,0), colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind=‘kde‘) # plots a kernel desnsity estimate of the subset of the 1st class passanges‘s age
data_train.Age[data_train.Pclass == 2].plot(kind=‘kde‘)#(核密度估计)
data_train.Age[data_train.Pclass == 3].plot(kind=‘kde‘)
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"各等级的乘客年龄分布")
plt.legend((u‘头等舱‘, u‘2等舱‘,u‘3等舱‘),loc=‘best‘) # sets our legend for our graph.
plt.subplot2grid((2,3),(1,2))
data_train.Embarked.value_counts().plot(kind=‘bar‘)
plt.title(u"各登船口岸上船人数")
plt.ylabel(u"人数")
plt.show()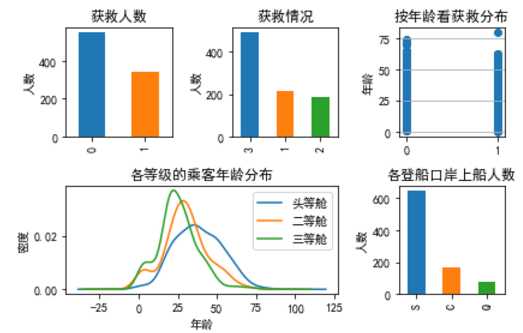
我们在图上可以看出来:被救的人300多点,不到半数;
3等舱乘客灰常多;遇难和获救的人年龄似乎跨度都很广;
3个不同的舱年龄总体趋势似乎也一致,2/3等舱乘客20岁多点的人最多,1等舱40岁左右的最多(→_→似乎符合财富和年龄的分配哈,咳咳,别理我,我瞎扯的);
登船港口人数按照S、C、Q递减,而且S远多于另外俩港口。
这个时候我们可能会有一些想法了:
不同舱位/乘客等级可能和财富/地位有关系,最后获救概率可能会不一样
年龄对获救概率也一定是有影响的,毕竟前面说了,副船长还说『小孩和女士先走』呢
和登船港口是不是有关系呢?也许登船港口不同,人的出身地位不同?
口说无凭,空想无益。老老实实再来统计统计,看看这些属性值的统计分布吧。
#看看各乘客等级的获救情况
fig = plt.figure()
fig.set(alpha=0.2) #设定图表颜色alpha参数
Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u‘获救‘:Survived_1, u‘未获救‘:Survived_0})
df.plot(kind=‘bar‘, stacked=True)#多分类累积柱状图 Stacked Bar
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()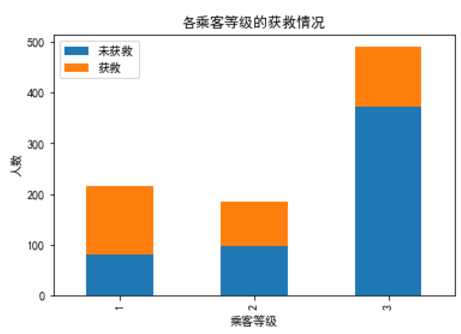
fig = plt.figure()
fig.set(alpha=0.5)
un_survived = data_train.Pclass[data_train.Survived == 0].value_counts()#未获救人的等级分布
# print(type(un_survived))#<class ‘pandas.core.series.Series‘>
survived = data_train.Pclass[data_train.Survived == 1].value_counts()#获救人的等级分布
df = pd.DataFrame({‘未获救‘:un_survived,‘获救‘:survived})
df.plot(kind = ‘bar‘,stacked = True)
plt.show()
明显等级为1的乘客,获救的概率高很多。恩,这个一定是影响最后获救结果的一个特征。
#看看各登录港口的获救情况
fig = plt.figure()
fig.set(alpha=0.2) #设定图表颜色alpha参数
Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u‘获救‘:Survived_1, u‘未获救‘:Survived_0})
df.plot(kind=‘bar‘, stacked=True)
plt.title(u"各登录港口乘客的获救情况")
plt.xlabel(u"登录港口")
plt.ylabel(u"人数")
plt.show()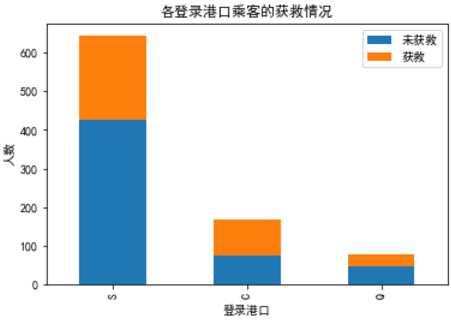
# 看看各性别的获救情况
fig = plt.figure()
fig.set(alpha=0.2) #设定图表颜色alpha参数
Survived_m = data_train.Survived[data_train.Sex == ‘male‘].value_counts()
Survived_f = data_train.Survived[data_train.Sex == ‘female‘].value_counts()
df=pd.DataFrame({u‘男性‘:Survived_m, u‘女性‘:Survived_f})
df.plot(kind=‘bar‘, stacked=True)
plt.title(u"按性别看获救情况")
plt.xlabel(u"性别")
plt.ylabel(u"人数")
plt.show()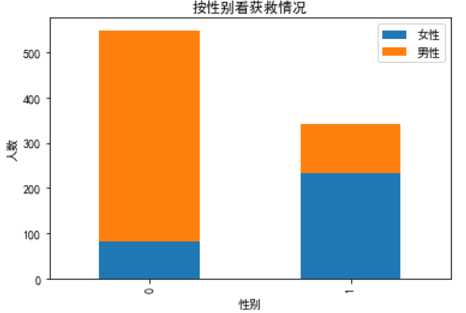
#然后我们再来看看各种舱级别情况下各性别的获救情况
fig=plt.figure()
fig.set(alpha=0.65) # 设置图像透明度,无所谓
plt.title(u"根据舱等级和性别的获救情况")
ax1=fig.add_subplot(141)
data_train.Survived[data_train.Sex == ‘female‘][data_train.Pclass != 3].value_counts().plot(kind=‘bar‘, label="female highclass", color=‘#FA2479‘)
ax1.set_xticklabels([u"获救", u"未获救"], rotation=0)
ax1.legend([u"女性/高级舱"], loc=‘best‘)
ax2=fig.add_subplot(142, sharey=ax1)
data_train.Survived[data_train.Sex == ‘female‘][data_train.Pclass == 3].value_counts().plot(kind=‘bar‘, label=‘female, low class‘, color=‘pink‘)
ax2.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"女性/低级舱"], loc=‘best‘)
ax3=fig.add_subplot(143, sharey=ax1)
data_train.Survived[data_train.Sex == ‘male‘][data_train.Pclass != 3].value_counts().plot(kind=‘bar‘, label=‘male, high class‘,color=‘lightblue‘)
ax3.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/高级舱"], loc=‘best‘)
ax4=fig.add_subplot(144, sharey=ax1)
data_train.Survived[data_train.Sex == ‘male‘][data_train.Pclass == 3].value_counts().plot(kind=‘bar‘, label=‘male low class‘, color=‘steelblue‘)
ax4.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/低级舱"], loc=‘best‘)
plt.show()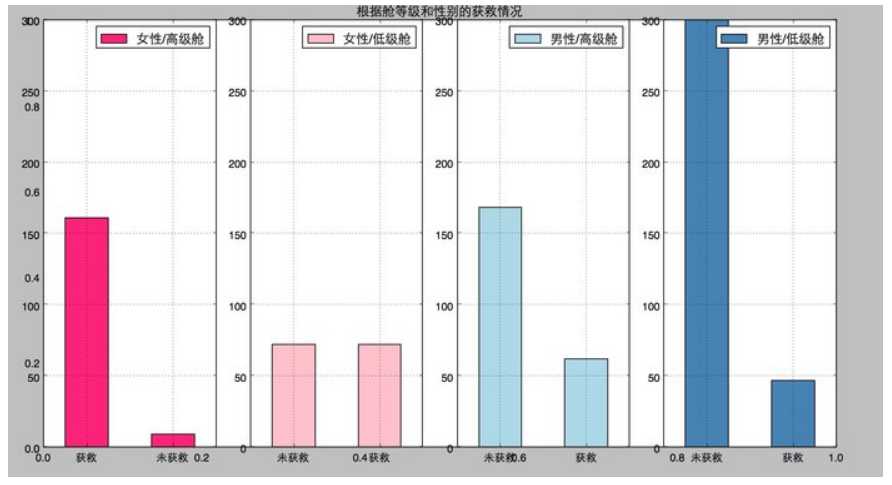
标签:legend nump 想法 生成 dataframe minus style numpy params
原文地址:https://www.cnblogs.com/nxf-rabbit75/p/9680878.html