标签:分享 没有 gen 初始化 时间 它的 方便 经验 影响
第16章 学习速率调度器
上一章中我们在训练MiniVGGNet时,在应用SGD优化网络时新引入了一个decay参数。本章我们将讨论学习速率调度器(learning rate schedules)的概念,有时称为学习速率退火或自适应学习速率。通过epoch-to-epoch的方式调整学习速率,我们可以降低损失、提高精确率,甚至在某些特定场景下降低训练网络的总时间。
最简单的学习速率调度器是随着时间推移逐步降低学习速率。为了考虑为什么学习速率调度器是一种可以提高模型精确率的方法,我们考虑标准的权重更新公式:

学习率α乘以梯度来更新权重,即α越大更新的一步越大反之越小,当α为零时将不会更新权重。在我们之前的例子中,我们都是固定α,通常设置α={0.1,0.01},之后以固定的epoch数目训练网络且在训练中不改变α值。这种方式在某些场景下是合适的,但随着时间推移降低学习速率α值是更有优势的做法。
当训练网络时,我们尝试沿着梯度方向找到精确率低的位置,常常不能获得全局最低甚至是局部最低,能够找到具有合理较低损失的位置就足够好了。如果我们设置固定的学习速率,那么可能在这些位置由于步幅太大从而错过该位置,因此我们随着时间推移降低学习速率允许网络能够以较小的步幅移动。
因此,学习速率调度器的过程可看做:
(1)在训练早期用较高学习率获得合理的好的权重值;
(2)在训练过程中使用较小学习率调整权重获得更优的权重。
我们可能遇到两种主要的学习速率调度器类型:
(1)基于epoch数目周期性降低的学习速率调度器(像线性、二次、指数函数)。
(2)基于特定epoch降低的学习速率调度器(例如分段函数)。
Keras库使用基于时间的学习速率调度器,它通过优化器类(如SGD)的decay参数控制。我们看在MiniVGGNet中SGD的初始化代码块:
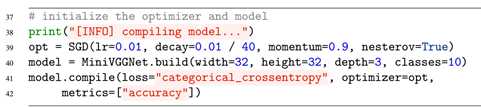
这里我们以学习率α=0.01、动量γ=0.9初始化SGD优化器,且使用Nesterov加速梯度方法。我们之后设置decay为学习率除以epoch总数目(这常是一般法则)。
Keras在每一轮epoch之后,通过下式调整学习率:
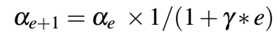
可看到,如果我们设置decay=0(在keras中默认配置为0,除非显示提供该值),那么学习率将不会改变。
我们重新对第15章的MiniVGGNet进行试验,这一次去掉decay参数,重新训练后的曲线与具有decay参数的曲线如图16.1所示:
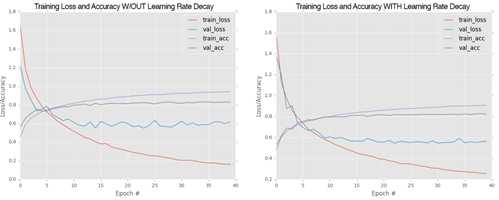
图16.1 学习速率decay参数对比图
我们注意到两个结果都获得了大约83%的验证精确率,但是在不具有学习速率decay的左图中,在25epoch后随着验证损失增加使得训练过拟合了。相对的,设置了decay后,我们获得了更平滑的学习曲线,通过使用学习速率decay参数我们不仅能提高分类精确率而且能够减轻过拟合的影响,即提高了模型泛化的能力。
另一种流行的学习速率调度器是基于步的decay,即在训练过程中经过特定epoch后我们系统的降低学习率。这种方式可看做是分段函数,一定epoch内学习率为固定值,然后降低它,再在一定epoch内固定另一个学习率值,然后在降低它,持续进行。
当应用step decay学习率时,我们有两个做法:
(1)定义一个分段函数,模拟我们想要的分段降低的效果;
(2)使用作者称为的ctrl+c方法训练深度学习网络,即我们在给定学习率下训练一定的epoch数目,最终注意到验证性能停止,之后ctrl+c停止脚本,调整学习率,再次训练。
在本章中我们主要应用基于公式的分段函数降低学习率方法。至于ctrl+c方法更高级通常用于使用深度神经网络的更大的数据集上,这个深度神经网络要获得合理的精确度通常epoch数目是不确定的。这种方法将在Practitioner Bundle和ImageNet Bundle中讨论。
当应用step decay时,通常在一定数目的epoch后通过(1)或(2)做法降低前一个学习率,然后更新为下一个学习率。
方便的,keras库提供了一个LearningRateScheduler类允许我们自定义一个学习速率函数之后在训练过程中自动应用它。这个函数以epoch作为参数之后基于我们定义的函数计算我们期望的学习率。
本章中我们自定义一个分段函数来模拟降低学习率:
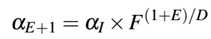
这里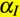 为初始化的学习率,F是控制学习率降低速率的因子,D为降低速率的epoch周期,E为当前epoch数目。F越大我们学习率降低越慢,F越小学习率降低越快。该等式用python实现如下:
为初始化的学习率,F是控制学习率降低速率的因子,D为降低速率的epoch周期,E为当前epoch数目。F越大我们学习率降低越慢,F越小学习率降低越快。该等式用python实现如下:
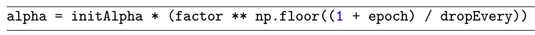
我们使用cifar10_lr_decay.py来实现该功能,具体程序见GitHub的chapter15/。通过from keras.callbacks import LearningRateScheduler,该类使我们自定义我们的学习速率调度器。我们定义完学习速率调度器函数后,通过callbacks = [LearningRateScheduler(step_decay)]让keras调度该函数,基于如何定义的callback,keras在每次epoch、mini-batch更新的开始或结束调用该函数。这个LearningRateScheduler方法将在每一次epoch开始时调用step_decay函数,允许我们在下一次epoch开始时更新学习率。注意,在初始化SGD时,作者喜欢将lr参数在这里显式指出,且与学习率调度函数中的initAlpha匹配。
为了评估drop factor在学习率调度和全局网络分类正确率的影响,我们分别使用drop factor为0.25和0.5时运行结果。降低因子为0.25时将下降的比0.5更快。
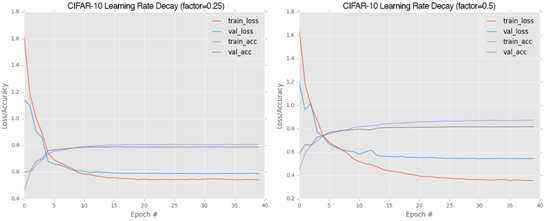
图16.2 不同降低因子下评估性能
由图16.2可看出不同降低因子下性能评估。可看出降低因子在0.25时,分类正确率在79%左右,并且在15epoch后学习率仅为0.00125这意味着网络以非常小的步幅优化,即15epoch后训练损失和验证损失都比较平稳了。
当学习率的降低为0.5时,我们获得了接近82%的准确率。我们看到网络在25-30epoch后仍在继续学习,直到损失稳定。
本章回顾了学习率调度的概念,我们讨论了两种调度类型。整体上说,与花费大量的时间训练网络和评估不同参数相比,即使简单的数据集和项目也需要10到100次试验来获得更高的精确率模型。
从学习深度学习这点上说,你应当理解了训练深度神经网络是半科学半艺术的。本书的目标是为你提供训练网络背后的科学以及作者使用的经验法则,这样你就可以学习它背后的“艺术”,但是要记住没有什么比亲自试验更好的了。
你在训练神经网络、记录有用或没用的结果上的练习越多,你就会变得越好。掌握这门艺术没有捷径可走,你需要花费时间且熟悉SGD优化器(和其它优化器)和它的参数上。
标签:分享 没有 gen 初始化 时间 它的 方便 经验 影响
原文地址:https://www.cnblogs.com/paladinzxl/p/9686023.html