标签:相对 如何 技巧 分享 研究 form 1.2 如图所示 sel
第17章 发现过拟合和欠拟合
我们现在将更深入的研究和讨论在深度学习背景下的过拟合和欠拟合(underfitting and overfitting)。这里将提供一些图表来将它们匹配到你自己的训练损失/精确度曲线上,这个对于第一次以本书来学习深度学习/机器学习且之前还没有面对过拟合和欠拟合时是特别有用的。
我们将创建一个用于keras的(近似)实时训练监视器,你可以用来照看网络的训练过程。之后,在我们能画出损失和精确度曲线之前我们将等待直到网络训练完成。
等待直到训练结束才可视化损失和精确度将是计算浪费的,特别是当训练要花费几小时甚至几天时间时,我们可能在前几次epoch后就应该根据曲线停止训练的。
因此,如果我们能在每一次epoch都能画出训练和损失并且能可视化结果,这将是很有用的。这样我们可以做出更好更有用的决定,是否应该更早的停止训练还是继续训练。
当训练自己的神经网络时,我们需要高度注意过拟合和欠拟合。欠拟合发生在我们的模型在训练集上不能获得足够低的损失的时候。这种情况下,模型在训练数据上不能学习到潜在的模式。相对的,过拟合发生在网络模型对训练数据模拟的太好且在验证集上泛化的不好的时候。
因此,我们在训练机器学习模型的目标是:
(1)尽可能地降低训练损失;
(2)同时确保训练和测试损失之间的差距相当小。
通过调整神经网络的能力可以控制一个模型是否过拟合或欠拟合。我们通过添加更多的层和神经元来增加能力。类似的,我们可以通过移除层和神经元以及应用正则化技术(权重decay、dropout、数据增加、早停等等)来降低能力。图17.1表示了模型能力与过拟合和欠拟合之间的关系。
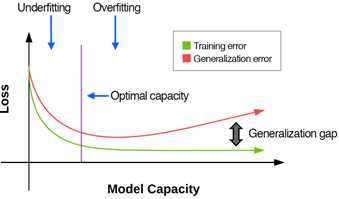
图17.1 模型容量与过拟合欠拟合关系示意图
x轴为模型能力,y轴为损失,其中损失越低越合理。通常一个模型开始训练时处于欠拟合区域(如图形左侧)。理想下,这时随着训练进行训练损失和验证损失都开始下降,这表明我们的网络实际上正在学习。
但是,随着模型能力的提高(更深的网络、更多的神经元、没有正则化等等),我们将达到网络的“最佳能力”。从这点开始,我们的训练和验证损失/精确度开始出现分歧,且一个可看到的差距开始出现。我们的目标是限制这个差距,即保持模型的泛化能力。
如果我们不能限制这个差距,我们将进入“过拟合区域”(如图形右侧),从这点上,我们的训练损失或者保持稳定或者持续下降,但是我们的验证损失将稳定并最终增加。验证损失在一系列连续epoch上增加是过拟合的强烈指示。
那么,我们如何克服过拟合呢?一般来说,有两种方式:(1)降低模型的复杂度,选择一个具有更少层和神经元的更浅层网络;(2)应用正则化方法。
使用更小的神经网络可能对于小数据集有用,但是一般来说,这不是好的选择。而是,我们应该使用正则化技术,如weight decay、dropout、数据增加、早停等等。实际上,使用正则化技术而不是降低网络大小来克服过拟合常常是更有效的,除非你有合理的理由相信你的网络架构对于这个问题仅仅是太大了。
学习率对过拟合的影响如图17.2所示:
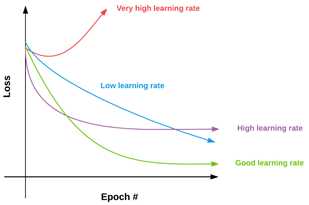
图17.2 学习率对损失的影响
在x轴上为一个神经网络的epoch数目,对应于y轴的损失。理想下,我们的验证损失和训练损失看起来应当向绿色曲线类似,此时损失下降快速,但又不会如此快以至于错误最低损失位置。
理想上,训练损失和验证损失曲线是拟合的,但是现实中需要大量训练来实现。因此,我们仅仅关注训练和验证损失之间的差距即可,即一旦这个差距不再动态增加,那么我们知道此时有了一个可接受的过拟合水平。但是,如果我们不能保持这种差距而且验证和训练损失之间的差距急剧加大,那么我们知道存在过拟合的风险。一旦验证损失开始增加,那么此时存在强过拟合。
当训练你自己的神经网络时,同时关注于训练数据和验证数据上的损失和正确率曲线。在最开始的几轮epoch中,你的神经网络可能曲线很好,可能轻微欠拟合——但是这种模式可能快速改变,你可能发现训练和验证损失开始差异。当这个发生时,看你的模型:
(1)使用任何正则化技术了吗?
(2)学习率太高了吗?
(3)网络太深了吗?
再次强调,训练一个深度学习网络半科学半艺术。学习怎样阅读这些曲线的最佳方式是尽可能多的训练网络然后查看它们的曲线。随着时间推移,你将有种有用还是无用的感觉,但是不要期望一开始就有这种能力。
最后,你也将接受过拟合在某些特定的数据集上是不可避免的现实。例如,在cifar-10数据集上很容易过拟合,如果训练和验证损失开始出现分歧,不要悲伤,尝试尽可能控制这个差距就可以了。
也要意识到随着在最后几轮epoch中学习率很低(如使用了学习率调度器),这也将更容易发生过拟合。这一点将在Practitioner Bundle和ImageNet Bundle中更清晰的讨论。
另一种奇怪的现象是验证损失比训练损失低。这怎么可能?当这个模式从训练数据中尝试学习,一个网络怎么可能在验证集上执行的更好?训练性能不是应该比验证或测试损失常常更好吗?
不一定。会有多种可能造成这种现象。最简单的解释是你的训练数据似乎都是很难分类的实例,而你的验证数据则是由简单数据点构成的。但是除非你有目的的以这种方式对数据抽样,否则一个随机的训练和测试数据划分不可能完全划分成这种数据点。
另一种可能的原因是数据增加(data augmentation)。我们将在Practitioner Bundle中详细讨论数据增加,但要点是在训练过程中,我们随机的改变训练图像,通过对它们应用随机变换如移动、旋转、缩放、剪切等。由于这些变化,该网络不断看到增加了的训练数据的样例,这是正则化的一种方式,使得网络在验证集上有更好的泛化能力但是可能在训练集上执行的比较差。
第三个原因可能是你训练的“不够努力”。你可能考虑增加学习率以及调整正则化强度。
在本节的第一部分,我们创建一个TrainingMonitor回调函数,它在当用keras训练网络时的每一轮epoch结束后调用。这个监视器将训练和验证集的损失和正确率序列化到磁盘上,之后构建数据图表。
在训练中应用这个监视器将使我们照看训练过程而且较早的画出过拟合,允许我们终止实验且继续尝试调整参数。
具体程序见GitHub的chapter17/pyimagesearch/callbacks/下。
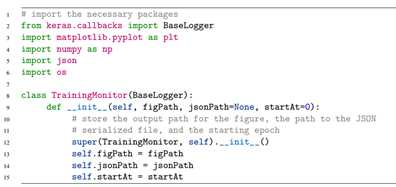
为了记录损失和正确率曲线,我们导入keras自带的BaseLogger类。我们定义的类有三个参数,一是我们要指定的输出图表目录,另两个分别为json文件路径,以及使用ctrl+c训练时的参数(该参数这里默认为0,在Practitioner中使用)。之后创建on_train_begin()函数,用于训练开始时调用。之后创建on_train_end()函数,用于每轮训练结束时调用:
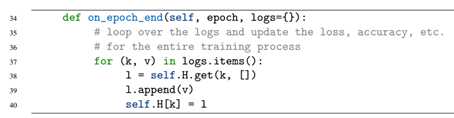
这个方法自动应用来自keras的参数,epoch为表示epoch数目,logs为字典,保存了当前epoch的训练和验证损失+正确率。我们周期性查询logs,然后更新我们的历史记录。代码结束后,我们的历史几率H中包含4个键:

最后,我们更新我们最终的图表。具体代码见GitHub。
我们以cifar10数据集训练为例。代码见GitHub的chapter17/的cifar10_monitor.py。
我们在程序中加入一行:print("[INFO process ID: {}".format(os.getpid())),这是作者的一个小技巧,如果同时训练多个网络,而且某些运行的很差,需要关闭时,可以打开任务管理器,直接kill掉该脚本对应的进程即可。
我们的文件名使用进程ID.png或进程ID.json的格式:


然后调用keras的callback函数配置,在训练网络的model.fit()中加入callbacks参数。此时,整个代码就完成了。运行即可。
Python cifar10_monitor.py --output output
在运行过程中,在output/目录下会看到有对应进程ID的两个文件。在运行2轮之后,就可以打开对应文件查看信息了。使用监视器程序可以在每轮训练结束后都可以照看训练过程并且监视训练。监视图表如图所示:
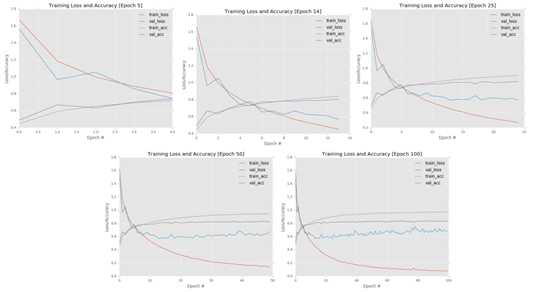
可看到在epoch 5时,扔处于欠拟合状态,网络从训练数据中学习,训练损失和验证损失都持续下降。
在epoch10的时候,我们看到过拟合的迹象,但是还没有过拟合警报,训练损失和验证损失出现分歧,但是这些分歧是正常的,而且指示了我们的网络正在从训练数据中继续学习潜在模式。
但是在epoch 25时,我们到达过拟合区域,训练损失持续下降,但是验证损失保持稳定,这是很清晰的过拟合迹象且表明坏事情正在发生。
在epoch 50时,我们确实处于麻烦中。验证损失开始增加,这确是过拟合了。这时你就应当停止实验,然后开始调整参数继续训练了。
如果我们让训练持续训练到epoch 100时,过拟合将只会变得更糟。训练损失和验证损失之间的差距将是巨大的。基于这些图标,我们可以清晰的看到过拟合是什么时候发生在哪的。当运行自己的实验时,确保使用监视器来辅助查看训练过程。
最后,当你认为出现过拟合迹象的时候,不要高兴的太早而过早kill掉进程,要确保继续训练10-15epoch来确定过拟合确实发生了。
标签:相对 如何 技巧 分享 研究 form 1.2 如图所示 sel
原文地址:https://www.cnblogs.com/paladinzxl/p/9686030.html