标签:测试工具 分享图片 bubuko ber 制表符 多次 如何 lse and
---恢复内容开始---
何为模块?一个模块就是包含了python定义和声明的文件,文件名就是模块加上.py的后缀.
但其实import加载的模块分为四个通用类别:
1.使用python编码的代码(.py文件)
2.一杯编译为共享库或DLLD的C或C++扩展
3.包好一组模块的包
4.使用c编写并链接到python解释器的内置模块
为何要用模块?
如果要退出python解释器然后重新进入,那么你之前定义的函数或者变量都将会丢失,因此我们通常将程序写到文件中以便保留下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script.
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分为一个个的文件,这样做的程序结构更加清晰,方便管理.这事我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现功能的重复利用.
模块的种类:
1.re模块
从京东的注册页面,打开页面我们就看到这些输入个人信息的提示.假设我们随意的在手机手机号码栏中输入12个1,它会提示我们格式错误.
这些功能是如何实现的呢?
假如现在你在python写一段代码,类似
number = input(‘请输入你的电话号码:‘)
你是怎么判断这个number是合法的呢?
根据手机号码一共是11位,并且是以13,14,15,18开头的数字的这些特点,我们用python写了一段代码
while True :
num = input("请输入你的电话号码:")
if len(num) ==11 and num.isdigit() and num.stratswith("13") and num.stratswith("14") and num.stratswith("15") and num.stratswith("18"):
print("是合法手机号码")
else:
print("不是合法的手机号码")
这个是目前学到的写法,其实还有一种法子
import re
num = input("请输入你的手机号码")
if re.match(‘(^13|14|15|18)[0-9]{9}$‘,num):
print("是合法的手机号码")
else:
print("不是合法的手机号码")
对比以上两种写法,喜欢哪一种?如果说是第一种?为啥?因为第一种不需要学
但是如果现在有一个文件,让你从文件中匹配所有的手机号码,你用python写一个试一下?
如果get今天这个技能,让你分分钟搞定,走向人生巅峰.
几天我们要学习python里面的re模块和正则表达式,学会了这个就可以帮我们解决刚刚的问题,正则不仅仅在python领域,在整个编程届都有举足轻重的地位.
ps:不管你学不学python开发,只要是一个程序员就应该了解正则表达式的基本使用,如果将来要是在爬虫领域发展的话,就应该更好好的学习这个知识.
但是你要知道,re模块本质上和正则表达式没有一毛钱关系,re模块和正则表达式的关系就类似于time模块和时间的关系
你没有学python之前,也不知道有time模块,但是你认识了时间,12:30就表示已经中午的12点半,这个时间刚刚可以下课了~
时间有自己的格式,年月日时分秒.12个月,365天...这个已经成为了一种规则,所以你也就牢记于心,time模块只不过是python提供给我们一个方便我们操作时间的工具罢了.
正则表达式本身也和python没有什么关系,就是匹配字符字符串内容的一种规则.
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符,以及特定字符组合组成一个"规则字符串",这规则字符串用来表达对字符串的一种过滤逻辑.
正则表达式
一说规则是不是很晕,现在就让我们先来看一些实际的应用。在线测试工具 http://tool.chinaz.com/regex/
首先一谈到正则,就和字符串相关了,在提供的工具里面,每输入一个字都是字符串,其次如果在一个位置的一个值,不会出现什么变化 ,那么是不需要规则的.
如果你要用1匹配1,或者用2匹配2,就直接匹配就好了,这个连python都可以轻松做到.那么在这之后我们更多的考虑是在同一个位置上,可以出现的字符范围.
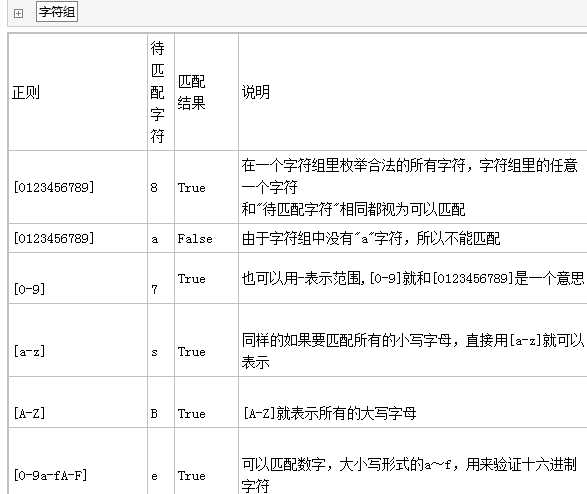
字符:
| 元字符 | 匹配内容 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意空白符 |
| \d | 匹配数字 |
| \n | 匹配换行符 |
| \t | 匹配制表符(tab) |
|
\b |
匹配一个单词的结尾 |
| ^ | 匹配一个字符串的开始 |
| $ | 匹配一个字符串的结尾 |
| \W | 匹配非字母或下划线 |
| \D | 匹配非数字 |
| \S | 匹配非任意空白字符 |
| a|b | a或者b |
| () | 匹配括号里面的表达式,也表示一个组 |
| [...] | 匹配字符组中的字符 |
| [^...] | 匹配除了字符组中的所有字符 |
量词:
| 量词 | 用法说明 |
| * | 重复多0或者多次 |
| + | 重复1或者多次 |
| ? | 重复0或者1次 |
| {n} | 重复n次 |
| {n,} | 重复n或者更多次 |
| {n,m} | 重复n到m次 |
例子:
.^$
| 正则 | 带匹配字符 | 匹配结果 | 说明 |
| 大. | 大哥大姐大人 | 大哥大姐大人 | 匹配所有带‘大‘的字符 |
| ^大. | 大哥大姐大人 | 大哥 | 匹配了开头"大" |
| 大.$ | 大哥大姐大人 | 大人 | 匹配了结尾的‘大‘ |
*+?{}
| 正则 | 带匹配字符 | 匹配结果 | 说明 |
| 张.? | 张大和张柳柳和张二棒子 |
张大 张柳 张二 |
?表示重复零次或者一次,即只匹配张后面一个 |
| 张大和张柳柳和张二棒子 | |||
| 张大和张柳柳和张二棒子 | |||
| 张大和张柳柳和张二棒子 |
---恢复内容结束---
---恢复内容结束---
标签:测试工具 分享图片 bubuko ber 制表符 多次 如何 lse and
原文地址:https://www.cnblogs.com/zhaodingding/p/9542219.html