标签:训练 性能 sem 精确 图片 类别 png image bottom
【Rich feature hierarchies for accurate object detection and semantic segmentation】
Abstract
论文的方法结合了两个关键的观察:1.可以通过hight-capacity CNN来进行bottom-up 区域提名以定位和划分对象;2.如果训练集不足,那监督预训练是个有用的方法,再经过fine-tuning,可以有很好的性能提升。R-CNN: Regions with CNN features。
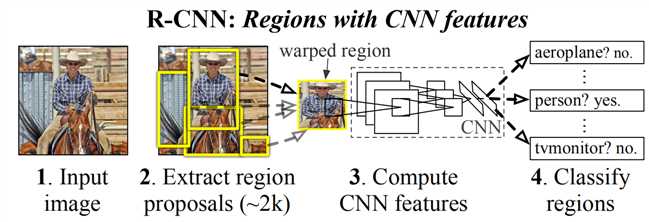
整体结构:1. 输入一张图; 2.提取出2000左右的区域; 3.用一个CNN对每个区域进行特征提取; 4. 通过SVM来对每个区域分类
建立图像分类和识别的桥梁:用一个深网络来记性图像定位,只用少量的检测数据来训练high-capacity模型
检测任务的方法:把定位看成回归问题;建立滑动窗口检测器(一些特定的类别,如人脸、行人,形状是比较固定的)。
本文采用的方法:recognition using regions
检测的第二个问题:数据不足。解决方法:在一个大型的数据集ILSVRC上进行监督的预训练,然后在小数据集上进行domain-specific fine-tuing
R-CNN的三个模块
1. 生成category-independent的区域提名,按类别来做区域提名selective search
2. 大型的CNN网络,用来从每个区域提取出固定长度的特征向量
AlexNet,网络要求输入为227x227,所以对数据进行处理:把图片压缩到227x227的大小
3. 一系列的class-specific 线性SVM
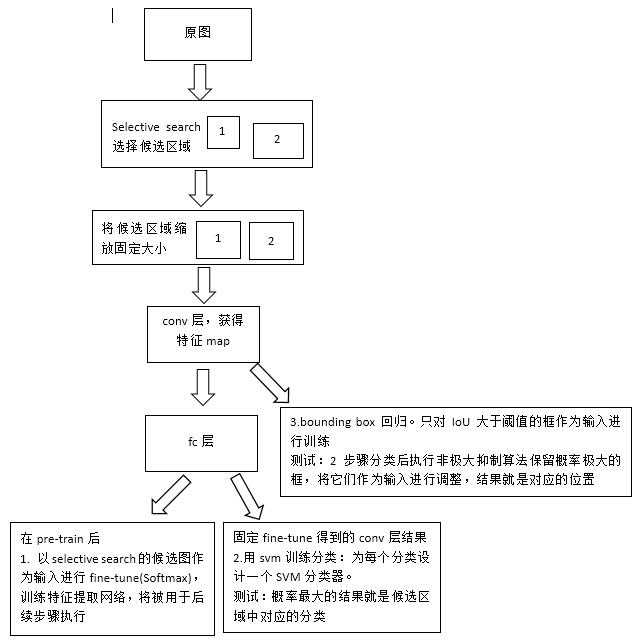
训练过程
测试
SVM分类概率最大的为分类结果,SVM分类后执行非极大抑制保留概率极大的框,把这些做为输入进行bounding box调整,结果就是目标的位置
其它注意点
1. 为什么SVM和fine-tune的参数不同(对positive example的定义) fine-tune:IOU>=0.5,SVM:只有ground-truth为真,IOU<0.3为假,其它 的忽略
原来的时候,是在预训练的feature map上做SVM,使用的参数和现在fine-tune是一样的。后来引入fine-tune后,两者使用相同参数,但是结果并不好 猜测是由于fine-tuning数据的限制导致,因为其中引入了很多overlap在0.5-1(但不是gr)的数据,这些数据是有必要的,可以防止过拟合。但是,他们会 导致结果变差,因为他们没有对精确的位置进行fine-tune 2. 为什么要SVM 如果只是使用fine-tune的softmax结果,mAP会下降
主要因素是因为在fine-tuning时没有强调精确的位置,而且negtive example是随机的,而不是har negtives
3. bounding box回归
正则化很重要
4. bounding box回归训练时对候选框P的选择(P,G)
如果P和G太远的话,那这个计算就没什么意义了。把一个P分配给某个G,如果P和G的IoU最大,且大于一个阈值,其它没有分配的就忽略。
标签:训练 性能 sem 精确 图片 类别 png image bottom
原文地址:https://www.cnblogs.com/coolqiyu/p/9420736.html