标签:fast resize 自定义 vol end 分段 启用 hashmap 对象
平时大家都会经常使用到 Map,面试的时候又经常会遇到问Map的,其中主要就是 ConcurrentHashMap,在说ConcurrentHashMap.我们还是先看一下,
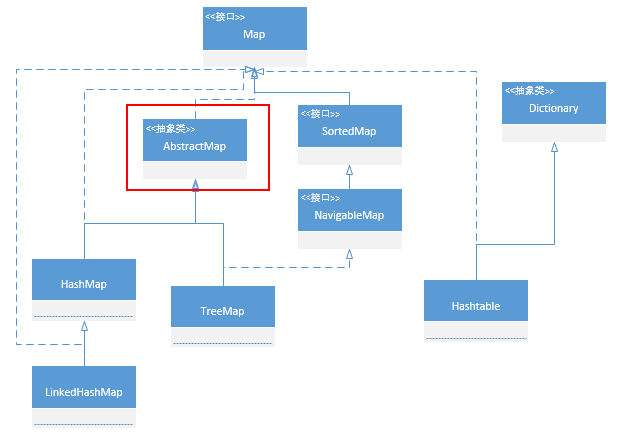
其他两个基础的 Map 类: HashMap 和 TreeMap
HashMap:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable,Serializable { // 这里有个很逗的事情 hashMap 继承了AvstractMap 为什么还要实现Map? 据说,作者说的 这只是个错误的写法 Q_Q
TreeMap:
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable
public interface NavigableMap<K,V> extends SortedMap<K,V>
| 实现 | 存储 | 遍历 | 性能损耗 | 键值对 | 安全 | 效率 | |
| TreeMap | SortMap接口,基于红黑树 | 默认按键的升序排序 | Iterator遍历是排序的 | 插入、删除 | 键、值都不能为null | 非并发安全Map | 适用于在Map中插入、删除和定位元素 |
| HashMap | 基于哈希散列表实现 | 随机存储 | Iterator遍历是随机的 | 基本无 | 只允许键、值均为null | 非并发安全Map | 适用于按自然顺序或自定义顺序遍历键(key) |
HashMap通常比TreeMap快一点(树和哈希表的数据结构使然),建议多使用HashMap,在需要排序的Map时候才用TreeMap。
那么现在就聊一下 HashMap和ConcurrentHashMap
我们都知道ConcurrentHashMap 是线程安全的.那为什么HashMap就线程不安全了呢?
这里有很不错的解释https://my.oschina.net/hosee/blog/673521
还有一个路径太长了.给个短的 还可以的
总结起来就是:
1. resize死循环
我们都知道HashMap初始容量大小为16,一般来说,当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的元素都需要被重算一遍。这叫rehash,这个成本相当的大。
在rehash的时候,在多线程的时候容易造成环形链表
2.fail-fast
如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。
这个异常意在提醒开发者及早意识到线程安全问题,具体原因请查看ConcurrentModificationException的原因以及解决措施 看了这个 我觉得需要去修改一下我原来说的CopyAndWriteArrayList 了
(1)结构 [Java7与Java8不同]
JDK7
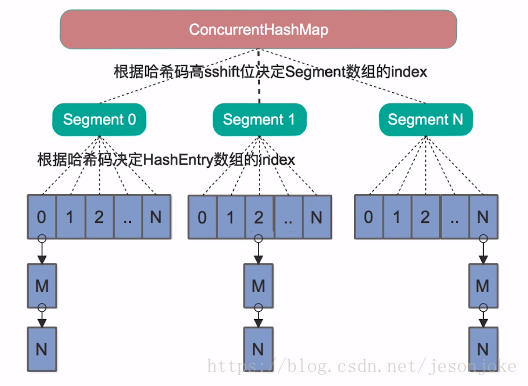
1.ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承了ReentrantLock)
2 . 当我们读取某个Key的时候它先取出key的Hash值,并将Hash值得高sshift位与Segment的个数取模,决定key属于哪个Segment。接着像HashMap一样操作Segment。 为了保证不同的Hash值保存到不同的Segment中,ConcurrentHashMap对Hash值也做了专门的优化。
3. 如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个Segment内的访问会扩散到不同的Segment中,CPU cache命中率会下降,从而引起程序性能下降。(文档的说法是根据你并发的线程数量决定,太多会导性能降低)
ConcurrentHashMap在JDK8中进行了巨大改动,很需要通过源码来再次学习下Doug Lea的实现方法。
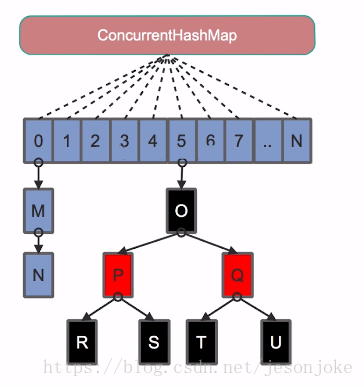
它摒弃了Segment(锁段)的概念,而是启用了一种全新的方式实现,利用CAS算法。它沿用了与它同时期的HashMap版本的思想,底层依然由“数组”+链表+红黑树的方式思想(JDK7与JDK8中HashMap的实现),但是为了做到并发,又增加了很多辅助的类,例如TreeBin,Traverser等对象内部类。
JDK6,7中的ConcurrentHashmap主要使用Segment来实现减小锁粒度,把HashMap分割成若干个Segment,在put的时候需要锁住Segment,get时候不加锁,使用volatile来保证可见性,当要统计全局时(比如size),首先会尝试多次计算modcount来确定,这几次尝试中,是否有其他线程进行了修改操作,如果没有,则直接返回size。如果有,则需要依次锁住所有的Segment来计算。
jdk7中ConcurrentHashmap中,当长度过长碰撞会很频繁,链表的增改删查操作都会消耗很长的时间,影响性能,所以jdk8 中完全重写了concurrentHashmap,代码量从原来的1000多行变成了 6000多 行,实现上也和原来的分段式存储有很大的区别。
主要设计上的变化有以下几点:
至于为什么JDK8中使用synchronized而不是ReentrantLock,我猜是因为JDK8中对synchronized有了足够的优化吧。
总结:
HashMap非线程安全、ConcurrentHashMap线程安全 (可以看下这个,很有ConcurrentHashMap能完全替代HashTable吗?)
HashMap允许Key与Value为空,ConcurrentHashMap不允许
HashMap不允许通过迭代器遍历的同时修改,ConcurrentHashMap允许。并且更新可见
高并发第九弹:逃不掉的Map --> HashMap,TreeMap,ConcurrentHashMap
标签:fast resize 自定义 vol end 分段 启用 hashmap 对象
原文地址:https://www.cnblogs.com/aihuxi/p/9688711.html