标签:内容 性问题 连接 主从 zook 基本 访问 分布 elastic
今天跟大伙一起聊聊分布式系统的架构的套路。在开始说套路之前,大家先思考一个问题,为什么要进行分布式架构?
大多数的开发者大多数的系统可能从来没接触过分布式系统,也根本没必要进行分布式系统架构,为什么?因为在访问量或者QPS没有达到单台机器的性能瓶颈的时候,根本没必要进行分布式架构。那如果业务量上来了,一般会怎么解决呢?
首先考虑的就是机器升级。机器配置的垂直扩展,首先要找到当前性能的瓶颈点,是CPU,是内存,是硬盘,还是带宽。砸钱加CPU,砸钱换SSD硬盘,砸钱换1T内存,这通常是解决问题最直接也最高效的方法。带宽不够?加带宽,1G不够用100G。CPU 8核不够?搞32核96核。这是绝大多数公司能思考到的第一个方案,也是最高效最快最安全的方法,立竿见影。
其次就是系统拆分,将所提供服务的主流程以及支线流程梳理出来,按照流程进行系统拆分。如同一棵树,核心业务作为主干流程,其他系统按照需要进行拆分,如同树的开枝散叶。所采取的方式有这么一些,按前后端进行拆分,按照领域拆分,按团队拆分,当然通常来说这些拆分基本都要跟着组织架构走。
再不行就进行技术升级,更换更加高效或者场景适合的技术。比如从 Oracle 更换到HBase。从A数据库连接池更换到B数据库连接池。技术的变革对于业务量的支持也是非常巨大的,同一台机器不同的技术,效能发挥的程度可以说有天壤之别。
最后的最后手段才会考虑分布式架构,实在是砸不出这么多钱了,实在是没办法了。因为分布式架构肯定会带来非常多非常多的一致性问题,原本只需要访问一台机器,现在需要访问N台,那么这N台机器的一致性怎么保证,以前撑死搞个主从备份就算完了,定时同步一下数据就好,现在N台设备的数据怎么管理,甚至这个集群本身怎么管理,都会成为一个致命的问题。
所以只有等业务量到达一定程度了,单台机器扛不住了,才会开始堆钱升级机器,系统拆分,换技术,继续堆钱升级机器,系统拆分...周而复始,发现成本太高或者技术已经到达上线了。最后没办法,就选择分布式架构了。
但是分布式架构的优势也是明显的,用一群低廉的设备,来提供一个高性能高吞吐量的稳定的系统,下面开始说说常见的分布式集群的架构。
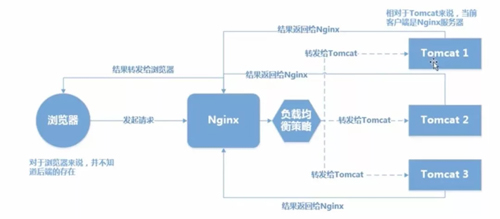
1、纯负载均衡形式。
在集群前面,前置一个流量分发的组件进行流量分发,整个集群的机器提供无差别的服务,这在常见的 web 服务器中是最最常见的。目前比较主流的方式就是整个集群机器上云,根据实时的调用量进行云服务器弹性伸缩。常见的负载均衡有硬件层面的 F5、软件层面的 nginx 等。
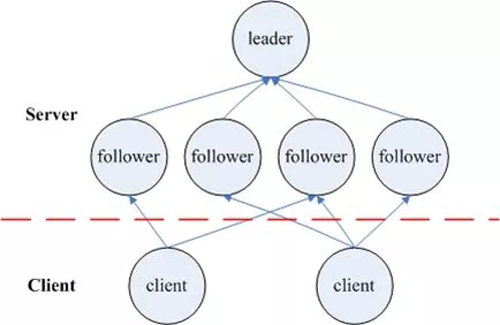
2、领导选举型
整个集群的消息都会转发到集群的领导这里,是一种 master-slavers,区别只是这个 master 是被临时选举出来的,一旦 master 宕机,集群会立刻选举出一个新的领导,继续对外提供服务。使用领导选举型架构的典型的应用有 ElasticSearch,zookeeper。
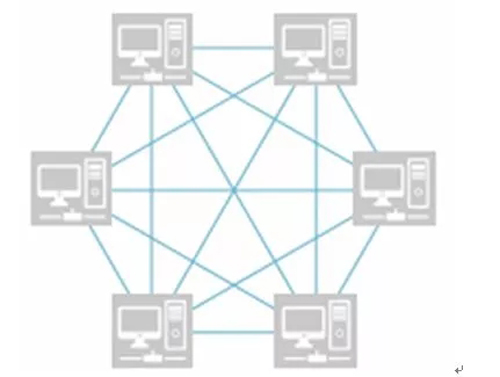
3、区块链型
整个集群的每一个节点都可以进行记录,但是记录的内容要得到整个集群 N 个机器的认可才是合法的。典型的应用有 Bit Coin,以及 Hyperledger。
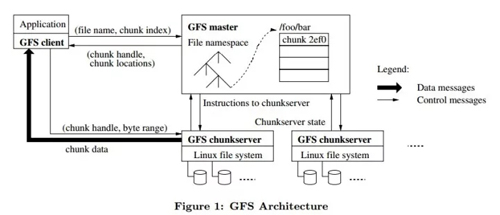
4、master-slaver型
整个集群以某台 master 为中枢,进行集群的调度。交互是这样,一般会把所有的管理类型的数据放到 master 上,而把具体的数据放到 slaver 上,实际进行调用的时候,client 先调用 master 获取数据所存放的 server 的 信息,再自行跟 slave 进行交互。典型的系统有 Hadoop。集群,HBase 集群,Redis 集群等。
5、规则型一致性Hash
这种架构类型一般出现在数据库分库分表的设计中。按照规则进行分库分表,在查询之前使用规则引擎进行库和表的确认,再对具体的应用进行访问。为什么要用一致性 Hash ?其实用什么都可以,只是对于这类应用来说一致性 Hash 比较常见而已。
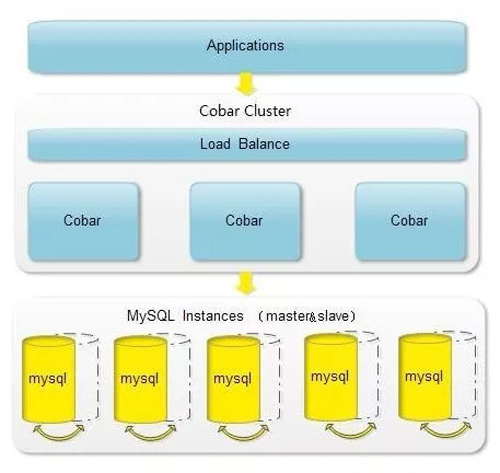
好了,至此,已经把我所知道的大部分分布式集群的套路说完了,总结一下。
1、升级机器配置是最直接的升级方式。不到万不得已不会使用分布式
2、分布式的核心就是业务拆分以及流量分发。
标签:内容 性问题 连接 主从 zook 基本 访问 分布 elastic
原文地址:https://www.cnblogs.com/zourui4271/p/9689427.html