标签:数组 false lib 分享 还原 orm 女性 poi info
泰坦尼克号获救率数据分析报告,用数据揭露真相。
一,船上乘客生存率分析报告
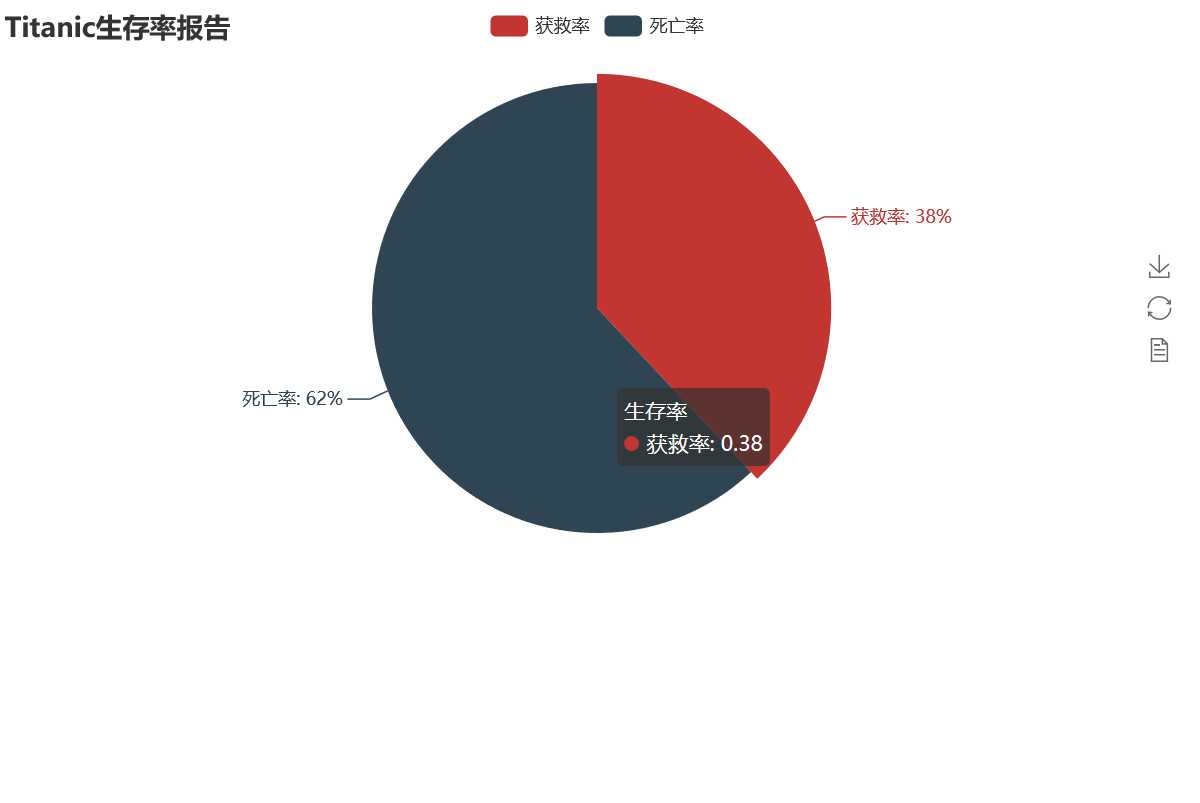
泰坦尼克号生存率仅有38%的,可见此次事件救援不力,救生艇严重不足,且泰坦尼克号号撞得是冰山,海水冷,没有救生艇,在水里冻死的乘客不少。
二,哪个年龄段存活率最高(青年人(18岁以下),中年人(18到50岁),老年人(50岁以上))
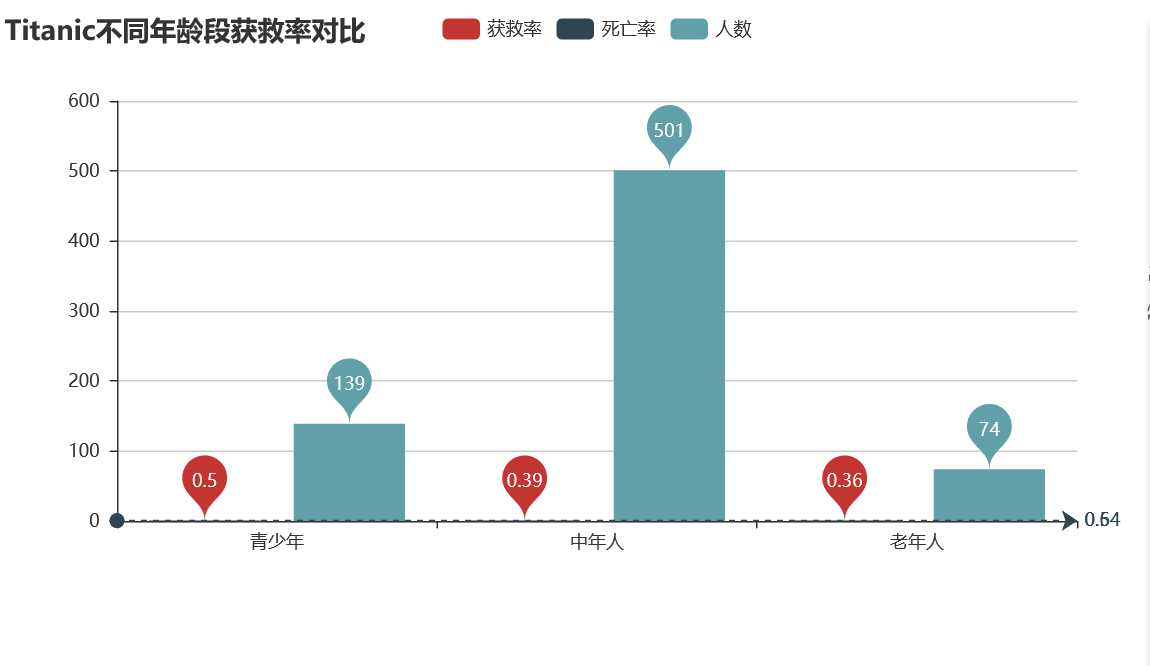
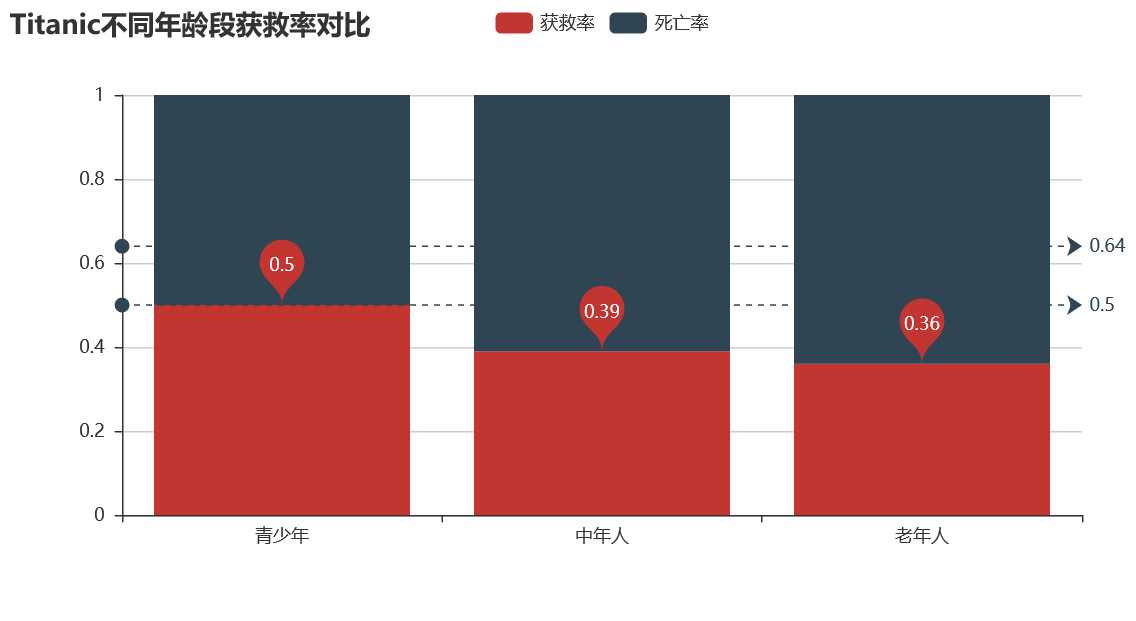
数据分析:看图我们得到,年轻人获救率最高50%,老年人获救率最低0.39,中年人死亡人数最多。发生生命危险时,自救能力最强的中年人还是起到了中流砥柱的作用。不要再叫猥琐油腻中年男了哦,他们才是社会的扛把子。
3,女性乘客和男性乘客获救率分析
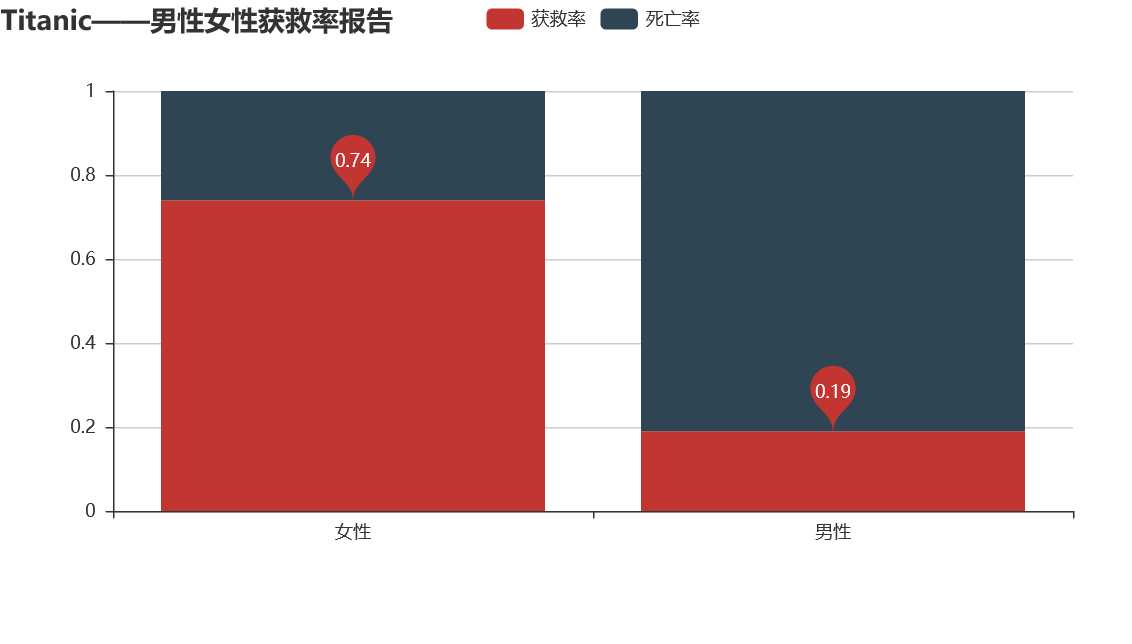
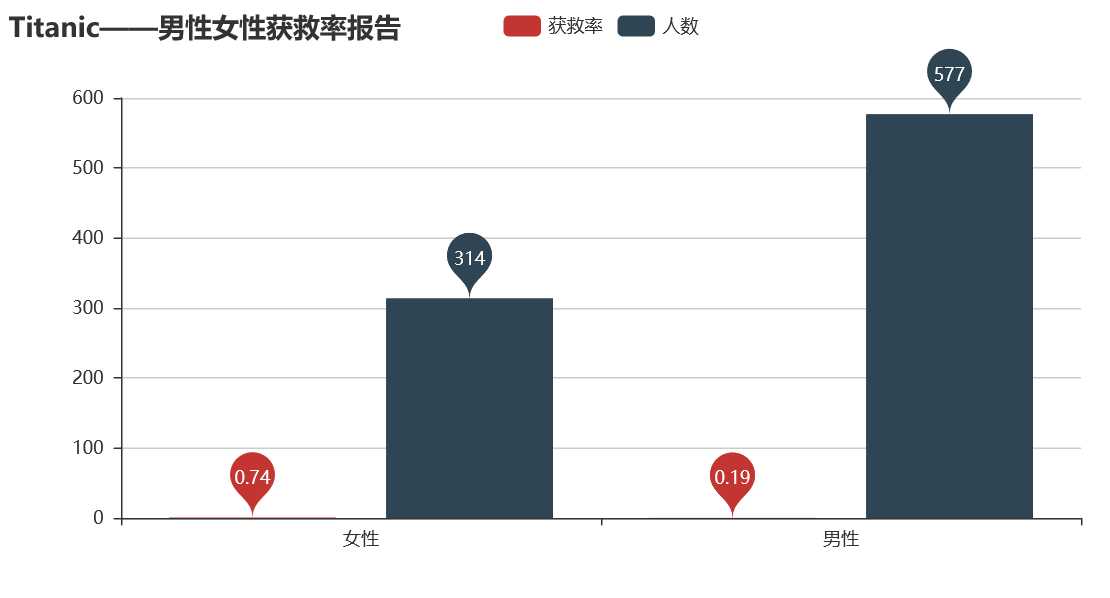
从图中可以看到,女性的获救率远远高于男性,女士优先不是一句空话。
4,船上一等舱二等舱三等舱的乘客贫富差距情况
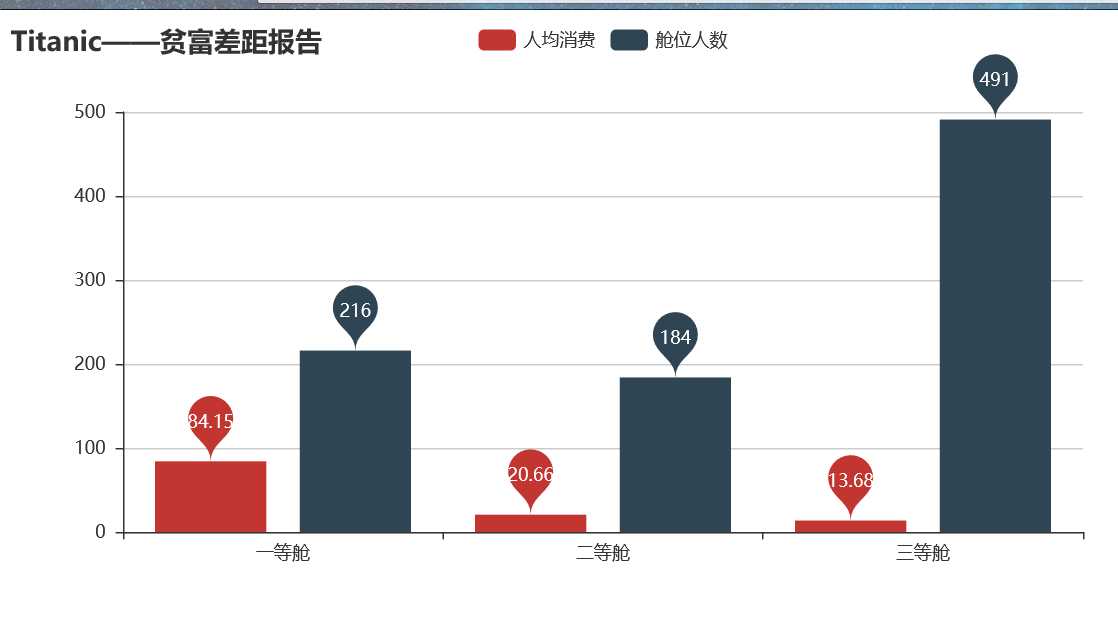
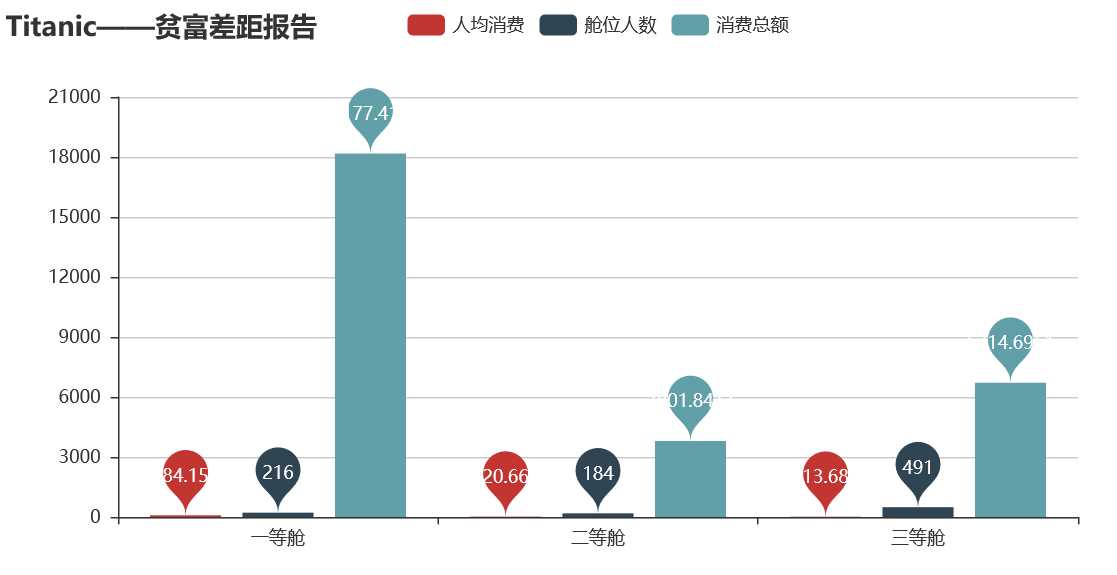
从图中可以看出,一等舱占全船24%的人数,消费额时全船的67%的金额。嗯,符合著名的二八法则,80%的财富掌握在20%的人手里。
5,舱位和获救率关系分析
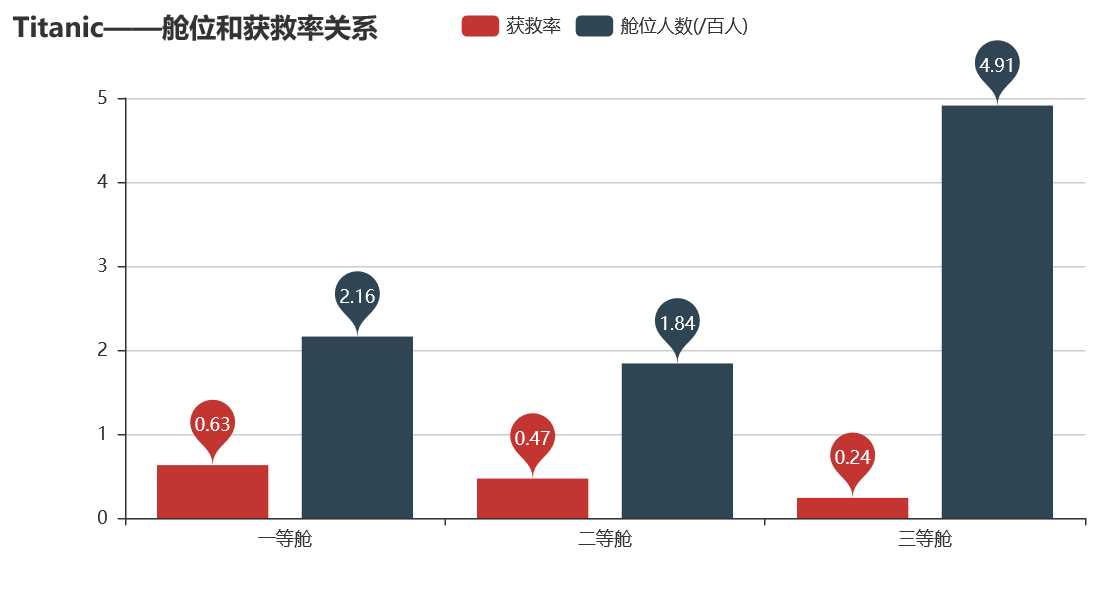
从图中可以看出,一等舱的获救率时三等舱的三倍左右,说明发生沉船事故时,一等舱先上救生艇的,有钱能使鬼推磨,古人诚不欺我也。
附上本人源代码:
import pandas as pd
import matplotlib.pyplot as plt#导入绘制函数
import numpy as np#导入数组库
from pylab import *#转义汉字
mpl.rcParams[‘font.sans-serif‘] = [‘SimHei‘]#
mpl.rcParams[‘axes.unicode_minus‘] = False#
from pyecharts import Pie,Bar,Gauge,EffectScatter,WordCloud,Map,Grid,Line,Timeline
import random
df_Titanic = pd.read_csv(‘Titanic.csv‘)
# print(df_Titanic)
#1,一获救率是多少
def Rescued_rate():
t1 = df_Titanic[‘Survived‘].count()
t2 = df_Titanic[df_Titanic[‘Survived‘]==1][‘Survived‘].count()
t3=round(t2/t1,2)
print(‘一,存活率为:{}‘.format(t3))
#Titanic存活率可视化
attr = [‘获救率‘,‘死亡率‘ ]
v1 = [t3,(1-t3)]
pie = Pie(‘Titanic生存率报告‘)
pie.add(‘生存率‘, attr, v1, is_label_show=True)
pie.render(‘TItanic_1.html‘)
Rescued_rate()
#2,哪个年龄段存活率最高
def age_survived():
#18岁以下的人存活率
young_survived = df_Titanic[(df_Titanic[‘Age‘]<=18)&(df_Titanic[‘Survived‘]==1)][‘Survived‘].count()
young_all = df_Titanic[df_Titanic[‘Age‘]<=18][‘Survived‘].count()
#18岁到50岁的存活率
middle_survived = df_Titanic[(df_Titanic[‘Age‘]<50)&(df_Titanic[‘Age‘]>18)&(df_Titanic[‘Survived‘]==1)][‘Survived‘].count()
middle_all = df_Titanic[(df_Titanic[‘Age‘]<50)&(df_Titanic[‘Age‘]>18)][‘Survived‘].count()
#50岁以上乘客的存活率
old_survived = df_Titanic[(df_Titanic[‘Age‘] >= 50) & (df_Titanic[‘Survived‘] == 1)][‘Survived‘].count()
old_all = df_Titanic[df_Titanic[‘Age‘] >= 50][‘Survived‘].count()
#三者的生存率
young_odds = round(young_survived/young_all,2)
middle_odds = round(middle_survived/middle_all,2)
old_odds = round(old_survived/old_all,2)
# list=[young_odds,middle_odds,old_odds]
# max_odds = max(list)
# df_odds = pd.Series([young_odds,middle_odds,old_odds])
# df_odds.plot(kind =‘bar‘)
# plt.show()
print(‘二,年轻人,中年人,老年人生存几率分别为{},{},{}‘.format(young_odds,middle_odds,old_odds))
#获救率可视化对比图
attr = [‘青少年‘, ‘中年人‘, ‘老年人‘]
v1 = [young_odds,middle_odds,old_odds]
v2 = [(1-young_odds), (1-middle_odds), (1-old_odds)]
v3 = [young_all,middle_all,old_all]
bar = Bar(‘Titanic不同年龄段获救率对比‘)
bar.add(‘获救率‘, attr, v1, mark_point=[‘average‘,‘max‘,‘min‘], is_stack=True)
bar.add(‘死亡率‘, attr, v2, mark_line=[‘min‘, ‘max‘], is_stack=True) # stack是否堆叠显示
bar.add(‘人数‘,attr,v3,mark_point=[‘average‘,‘max‘,‘min‘],is_stack=False)
bar.render(‘Titanic_2.html‘)
age_survived()
#3,女性存活率和男性存活率哪个高
def Rescued_rate_man():
s_man =df_Titanic[(df_Titanic[‘Sex‘]==‘male‘)&(df_Titanic[‘Survived‘]==1)][‘Sex‘].count()#获救的男人数
c_man = df_Titanic[df_Titanic[‘Sex‘]==‘male‘][‘Sex‘].count()#男人总数
rescued_man = round(s_man/c_man,2)#男人获救率
s_woman = df_Titanic[(df_Titanic[‘Sex‘]==‘female‘)&(df_Titanic[‘Survived‘]==1)][‘Sex‘].count()
c_woman = df_Titanic[df_Titanic[‘Sex‘]==‘female‘][‘Sex‘].count()
rescued_woman = round(s_woman/c_woman,2)
if rescued_woman > rescued_man:
print(‘三,女性获救率高‘)
else:
print(‘三,男性获救率高‘)
#
attr = [‘女性‘, ‘男性‘]
v1 = [rescued_woman,rescued_man]
# v2 = [(1 - rescued_woman), (1 - rescued_man)]
v3 = [c_woman,c_man]
bar = Bar(‘Titanic——男性女性获救率报告‘)
bar.add(‘获救率‘, attr, v1, mark_point=[‘average‘, ‘max‘, ‘min‘], is_stack=True)
# bar.add(‘死亡率‘, attr, v2,mark_point=[‘average‘, ‘max‘, ‘min‘], is_stack=True)
bar.add(‘人数‘, attr, v3,mark_point=[‘average‘, ‘max‘, ‘min‘], is_stack=False)# stack是否堆叠显示
bar.render(‘Titanic_3.html‘)
Rescued_rate_man()
#船上的贫富差距
def wealth_gap():
#一等舱的人均消费
consume_one = round(df_Titanic[df_Titanic[‘Pclass‘]==1][‘Fare‘].mean(),2)
consume_two = round(df_Titanic[df_Titanic[‘Pclass‘]==2][‘Fare‘].mean(),2)
consume_three = round(df_Titanic[df_Titanic[‘Pclass‘]==3][‘Fare‘].mean(),2)
consume_std = round(df_Titanic[‘Fare‘].std(),2)
#一等舱二等舱三等舱的人数
person_one = df_Titanic[df_Titanic[‘Pclass‘]==1][‘Survived‘].count()
person_two = df_Titanic[df_Titanic[‘Pclass‘] == 2][‘Survived‘].count()
person_three = df_Titanic[df_Titanic[‘Pclass‘] == 3][‘Survived‘].count()
#一等舱二等舱三等舱的消费总额
consumeall_one =df_Titanic[df_Titanic[‘Pclass‘]==1][‘Fare‘].sum()
consumeall_two = df_Titanic[df_Titanic[‘Pclass‘] == 2][‘Fare‘].sum()
consumeall_three = df_Titanic[df_Titanic[‘Pclass‘] == 3][‘Fare‘].sum()
print(‘四,一等舱人均消费:{},二等舱人均消费:{},三等舱人均消费:{},人均消费标准差:{}‘.format(consume_one,consume_two,consume_three,consume_std))
#可视化
attr = [‘一等舱‘, ‘二等舱‘,‘三等舱‘]
v2 = [consume_one,consume_two,consume_three]
v1 = [person_one,person_two,person_three]
v3 = [consumeall_one,consumeall_two,consumeall_three]
bar = Bar(‘Titanic——贫富差距报告‘)
bar.add(‘人均消费‘, attr, v2, mark_point=[‘average‘, ‘max‘, ‘min‘], is_stack=False)
bar.add(‘舱位人数‘, attr, v1,mark_point=[‘average‘, ‘max‘, ‘min‘], is_stack=False) # stack是否堆叠显示
bar.add(‘消费总额‘, attr, v3, mark_point=[‘average‘, ‘max‘, ‘min‘],is_stack=False)
bar.render(‘Titanic_4.html‘)
wealth_gap()
#头等舱的生存率是否高于三等舱
def Survival_comparison():
#一等舱的获救率
s1=df_Titanic[(df_Titanic[‘Pclass‘]==1)&(df_Titanic[‘Survived‘]==1)][‘Survived‘].count()
c1 = df_Titanic[df_Titanic[‘Pclass‘]==1][‘Survived‘].count()
svl_1 = round(s1/c1,2)
#二等舱的获救率
s2 = df_Titanic[(df_Titanic[‘Pclass‘] == 2) & (df_Titanic[‘Survived‘] == 1)][‘Survived‘].count()
c2 = df_Titanic[df_Titanic[‘Pclass‘] == 2][‘Survived‘].count()
svl_2 = round(s2 / c2,2)
#三等舱的获救率
s3 = df_Titanic[(df_Titanic[‘Pclass‘] == 3) & (df_Titanic[‘Survived‘] == 1)][‘Survived‘].count()
c3 = df_Titanic[df_Titanic[‘Pclass‘] == 3][‘Survived‘].count()
svl_3 = round(s3 / c3,2)
if svl_1>svl_2>svl_3:
print(‘五,一等舱二等舱三等舱的获救率分别为:{},{},{},一等舱获救率最高‘.format(svl_1,svl_2,svl_3))
else:
print(‘获救率和舱位关系不大‘)
#舱位和获救率的关系
attr = [‘一等舱‘, ‘二等舱‘, ‘三等舱‘]
v2 = [c1/100, c2/100,c3/100]
v1 = [svl_1,svl_2,svl_3]
bar = Bar(‘Titanic——舱位和获救率关系‘)
bar.add(‘获救率‘, attr, v1, mark_point=[‘average‘, ‘max‘, ‘min‘], is_stack=False)
bar.add(‘舱位人数(/百人)‘, attr, v2, mark_point=[‘average‘, ‘max‘, ‘min‘], is_stack=False) # stack是否堆叠显示
bar.render(‘Titanic_4.html‘)
Survival_comparison()
#6,带家属的乘客占的比率,有家属是否会影响生存率
def family_survived():
family_yes = df_Titanic[(df_Titanic[‘SibSp‘]==1)|(df_Titanic[‘Parch‘]==1)][‘Survived‘].count()#带家属的乘客人数
family_no = df_Titanic[(df_Titanic[‘SibSp‘] == 0) & (df_Titanic[‘Parch‘] == 0)][‘Survived‘].count()#不带家属的乘客人数
family_all = df_Titanic[‘Survived‘].count()
family_odds = round(family_yes/family_all,2)
#带家属获救的人数
family_survive = df_Titanic[(df_Titanic[‘SibSp‘]==1)|(df_Titanic[‘Parch‘]==1)&(df_Titanic[‘Survived‘]==1)][‘Survived‘].count()
#不带家属获救的人数
family_no_survive = df_Titanic[(df_Titanic[‘SibSp‘]==0)&(df_Titanic[‘Parch‘]==0)&(df_Titanic[‘Survived‘]==1)][‘Survived‘].count()
#带家属获救的几率
family_survive_odds = round(family_survive/family_yes,2)
#不带家属获救的几率
familyno_survive_odds = round(family_no_survive / family_no, 2)
if family_survive_odds>familyno_survive_odds:
print(‘六,带家属的生存率为{},不带家属的生存率为{},带家属的生存率高一些‘.format(family_survive_odds,familyno_survive_odds))
else:
print(‘带家属的乘客获救几率和其他乘客一样‘)
family_survived()
#七,从哪个港口登陆是否影响生存率
def port_survived():
#S口进入获救的人数
S_survived = df_Titanic[(df_Titanic[‘Survived‘]==1)&(df_Titanic[‘Embarked‘]==‘S‘)][‘Survived‘].count()
#S口进入的总人数
S_all = df_Titanic[df_Titanic[‘Embarked‘]==‘S‘][‘Survived‘].count()
#C口进入获救的人数
C_survived = df_Titanic[(df_Titanic[‘Survived‘]==1)&(df_Titanic[‘Embarked‘]==‘C‘)][‘Survived‘].count()
#C口进入的总人数
C_all = df_Titanic[df_Titanic[‘Embarked‘] == ‘C‘][‘Survived‘].count()
#Q口进入获救的人数
Q_survived = df_Titanic[(df_Titanic[‘Survived‘]==1)&(df_Titanic[‘Embarked‘]==‘Q‘)][‘Survived‘].count()
#Q口进入的总人数
Q_all = df_Titanic[df_Titanic[‘Embarked‘] == ‘Q‘][‘Survived‘].count()
#从S,C,Q,进入生存的几率
s_odds = round(S_survived/S_all,2)
c_odds = round(C_survived/C_all,2)
q_odds = round(Q_survived/Q_all,2)
print(‘七,s,c,q港口进入的乘客的生存率分别为{},{},{}‘.format(s_odds,c_odds,q_odds))
port_survived()
泰坦尼克号事实,用数据还原真相——Titanic获救率分析(用pyecharts)
标签:数组 false lib 分享 还原 orm 女性 poi info
原文地址:https://www.cnblogs.com/chaojiyingxiong/p/9689795.html