标签:att 提醒 code 数据表 语义 http tick append read
既然是找到了不错的工作,自然不敢怠慢,作为入职前的准备自己找了个任务干,再熟悉一下语义识别&文本分类的整个过程。
数据使用的是NLPCC2013的第二个任务,中文微博细粒度情感识别,现在在官网已经不太好找到合适的数据了,我用的是从CSDN上面下载的,tb花了几块钱解决。打开一看好家伙,还是xml格式的,有的里面自带标签,有的不带,还有的有另一套标签和自带的不一样,真是醉了。于是就开始ML里面最恶心的一步——数据清洗。粗略看了看当时的报告,竟然是先给一个小训练集,然后放到一个大测试集上面跑,这准确率要是能高才怪的。当时基本上全都是用的ML+特征选择的方法,准确率貌似50都算高的了。最后我拿到的包括两个文件,是当时所谓的“训练集”和“测试集”(两个文件的数据分布在下面),数据里面一共包括有1.4w条微博,每个微博里面有若干条句子,句子总数大概是4.5w。反正也不是真正去比赛,我就随机把这4.5w个句子分成了0.8 + 0.1 + 0.1。
(当时的)测试集数据分布:
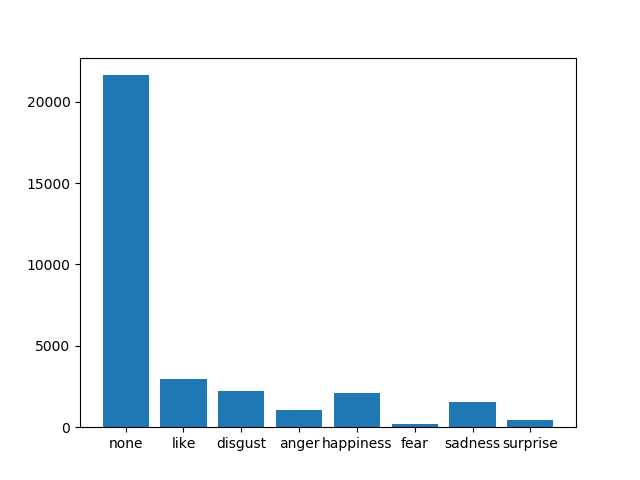
(当时的)训练集数据分布:
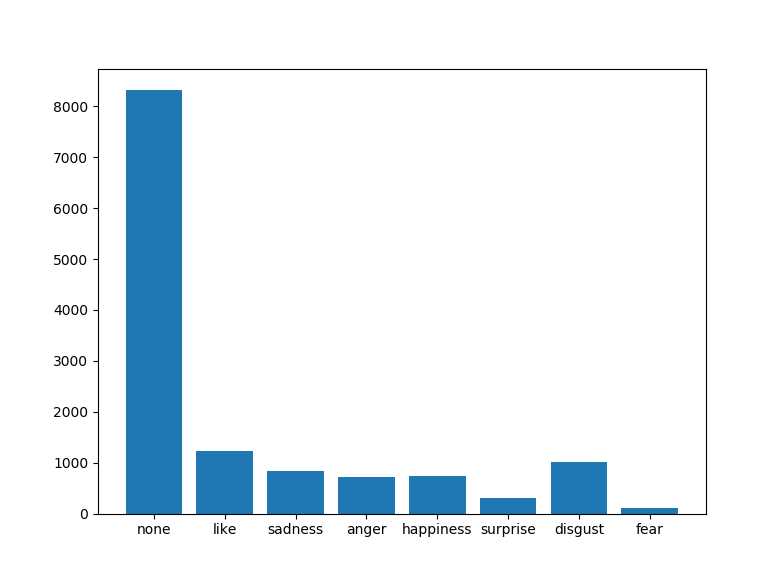
可以看出,两种数据集标签都是一样的,分布也可以说是差不多。主要特点就是没有情绪占了大多数,其他情绪加起来和没有情绪的差不多。在这里就出现了很严重的数据偏斜,如果不进行特征提取的话DL模型对这样的数据表现怎样还很难说。
通过最后乱七八糟一通数据清晰,终于把数据成功分成了训练集,验证集合测试集,还有一个包含所有文本的用来做embedding。如果需要这些数据的话可以给我发邮件,872618562@qq.com打包发给你。
在这里也顺便把python处理xml的程序po一下,主要是提醒自己别忘了哈哈
import xml.dom.minidom import matplotlib.pyplot as plt dom = xml.dom.minidom.parse(‘raw_test.xml‘) output = open("test.txt", "w") label_file = open(‘test_label.txt‘, "w") root = dom.documentElement nodes = dom.getElementsByTagName(‘sentence‘) senti_list = [] tag_number = [] labels = [] counter = 0 ‘‘‘ for i in label_file.readlines(): labels.append(i.split()[3]) print(i.split()[3]) ‘‘‘ for n in nodes: try: print(n.childNodes[0].data, file=output) if n.getAttribute(‘emotion_tag‘) == "N": sentiment = "none" else: if n.getAttribute(‘emotion_tag‘) == "": sentiment = "none" else: sentiment = n.getAttribute(‘emotion-1-type‘) print(sentiment, file=label_file) counter += 1 if sentiment in senti_list: tag_number[senti_list.index(sentiment)] += 1 else: tag_number.append(1) senti_list.append(sentiment) except IndexError: continue print(counter) print(senti_list) print(tag_number) plt.bar(range(len(tag_number)), tag_number,tick_label=senti_list) plt.show()
主要用到的包是xml.dom.minidom 具体他是干啥的暂时就先不深究了,知道使用的步骤大概需要先解析,再根据标签查找就好了,要找数据用childnode[0].data,要找属性用getAttribute("xxx")
这样的话最讨厌的数据清洗就完成了!下一步就是如果制作出像样的可以输入到模型里面的数据,并且构建词典做embedding,由于其实像word2vec这种超大语料库训练的embedding不是很多而且这个微博数据里面说实话五花八门什么词都有,所以打算自己训练一个,也是顺便练练手。下一步的工作主要是对数据做预处理并且合适的方法分好词。希望可以一天弄好。886~
标签:att 提醒 code 数据表 语义 http tick append read
原文地址:https://www.cnblogs.com/yunke-ws/p/9712412.html