标签:sklearn src 不同 完整 col 评估 core 允许 表示
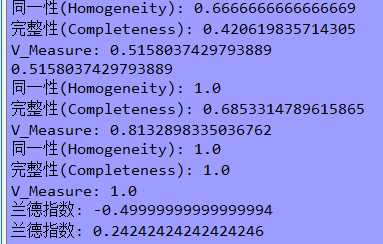
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Thu Sep 27 16:24:29 2018 4 模型及预测准确度评估 5 @author: zhen 6 """ 7 8 from sklearn import metrics 9 10 if __name__ == "__main__": 11 12 # 同一性homogeneity:每个群集只包含单个类的成员。 13 # 完整性completeness:给定类的所有成员都分配给同一个群集。 14 # 调和平均V-measure 15 y = [0, 0, 0, 1, 1, 1] 16 y_hat = [0, 0, 1, 1, 2, 2] 17 h = metrics.homogeneity_score(y, y_hat) 18 c = metrics.completeness_score(y, y_hat) 19 20 v2 = 2 * c * h / (c + h) 21 v = metrics.v_measure_score(y, y_hat) 22 print(u‘同一性(Homogeneity):‘, h) 23 print(u‘完整性(Completeness):‘, c) 24 print(u‘V_Measure:‘, v2, v) 25 26 y = [0, 0, 0, 1, 1, 1] 27 y_hat = [0, 0, 1, 3, 3, 3] 28 h = metrics.homogeneity_score(y, y_hat) 29 c = metrics.completeness_score(y, y_hat) 30 v = metrics.v_measure_score(y, y_hat) 31 32 print(u‘同一性(Homogeneity):‘, h) 33 print(u‘完整性(Completeness):‘, c) 34 print(u‘V_Measure:‘, v) 35 36 # 允许不同值 37 y = [0, 0, 0, 1, 1, 1] 38 y_hat = [1, 1, 1, 0, 0, 0] 39 h = metrics.homogeneity_score(y, y_hat) 40 c = metrics.completeness_score(y, y_hat) 41 v = metrics.v_measure_score(y, y_hat) 42 43 print(u‘同一性(Homogeneity):‘, h) 44 print(u‘完整性(Completeness):‘, c) 45 print(u‘V_Measure:‘, v) 46 47 # 兰德指数 48 # ARI值的范围是[-1,1],负的结果都是较差的,越接近-1表示聚类越差, 49 # 正的结果都是较好的,1是最佳结果,越接近1表示聚类结果越好。 50 y = [0, 0, 1, 1] 51 y_hat = [0, 1, 0, 1] 52 ari = metrics.adjusted_rand_score(y, y_hat) 53 print("兰德指数:", ari) 54 55 y = [0, 0, 0, 1, 1, 1] 56 y_hat = [0, 0, 1, 1, 2, 2] 57 ari = metrics.adjusted_rand_score(y, y_hat) 58 print("兰德指数:", ari) 59
结果:
标签:sklearn src 不同 完整 col 评估 core 允许 表示
原文地址:https://www.cnblogs.com/yszd/p/9719946.html