标签:img 效果 cal 查看 情况下 gil 参数 conf 运行速度
参考
YOLO算法把物体检测问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。YOLO具有如下优点:(1)YOLO的运行速度非常快;(2)YOLO是基于图像的全局信息预测的,因此在误检测的错误率下降挺多;(3)泛化能力强,准确率高。

Yolo算法采用的是均方差损失函数,但是对不同的部分采用了不同的权重值。因为很多grid cell是不包含物体的 (对应的confidence score为0),如果定位误差和分类误差的权重值一样,则不包含物体的单元格将会盖过包含物体的单元格对损失函数的影响,容易导致模型不稳定,训练发散。对于定位误差,即边界框坐标预测误差,采用较大的权重$λ_coord=5$(误差越大,则促使边界框的定位更精确)。然后其区分不包含目标的边界框与含有目标的边界框的置信度,对于前者,采用较小的权重值$λ_noobj=0.5$(不包含目标时,对应的box bounding对结果的影响较小,因此给与小的权重),其它权重值均设为1。
均方误差同等对待大小不同的边界框,但是实际上较小的边界框的坐标误差应该要比较大的边界框要更敏感。因此将网络的边界框的宽与高预测改为对其平方根的预测,即预测值变为(x,y,w??√,h??√)(x,y,w,h)。
另外由于每个单元格预测多个边界框。但是其对应类别只有一个。那么在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU最大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能。如果一个单元格内存在多个目标怎么办,其实这时候Yolo算法就只能选择其中一个来训练,这也是Yolo算法的缺点之一。
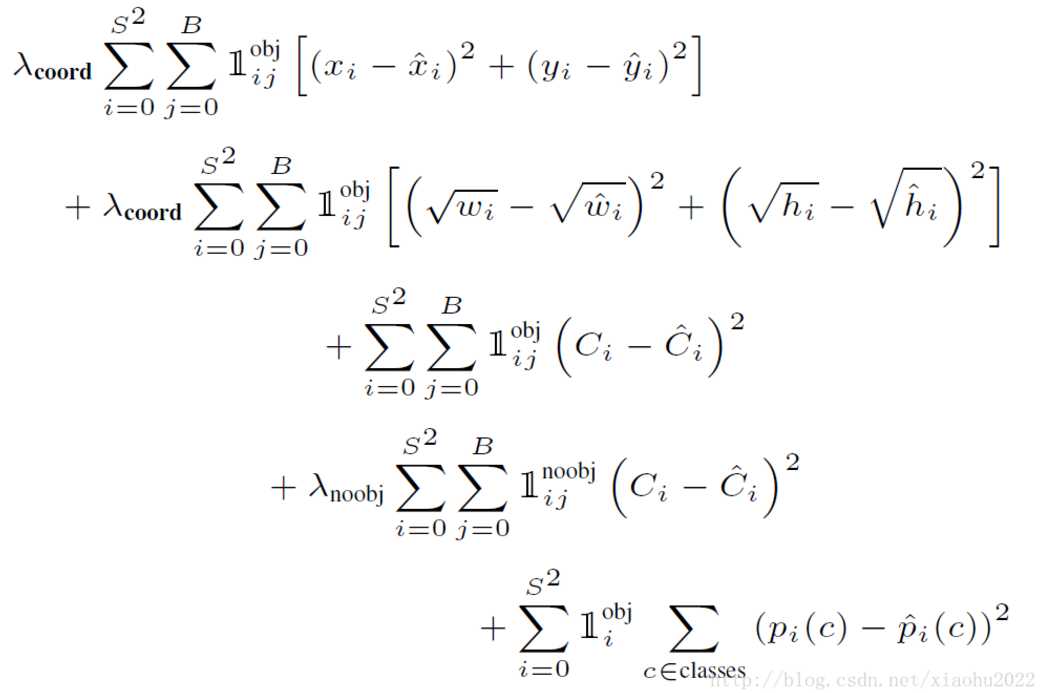
其中第一项是边界框中心坐标的误差项,1objij1ijobj指的是第ii个单元格存在目标,且该单元格中的第jj个边界框负责预测该目标。第二项是边界框的高与宽的误差项。第三项是包含目标的边界框的置信度误差项。第四项是不包含目标的边界框的置信度误差项。而最后一项是包含目标的单元格的分类误差项,1obji1iobj指的是第ii个单元格存在目标。
在目标检测的评价体系中,有一个参数叫做 IoU ,简单来讲就是模型产生的目标窗口和原来标记窗口的交叠率。具体我们可以简单的理解为: 即检测结果(DetectionResult)与 Ground Truth 的交集比上它们的并集,即为检测的准确率 IoU :
$$
IOU = \frac{DetectionResult\cap GroundTruth}{DetectionResult\cup GroundTruth}
$$
NMS算法主要解决的是一个目标被多次检测的问题,如下图中人脸检测,可以看到人脸被多次检测,但是其实我们希望最后仅仅输出其中一个最好的预测框,比如对于美女,只想要红色那个检测结果。那么可以采用NMS算法来实现这样的效果:首先从所有的检测框中找到置信度最大的那个框,然后挨个计算其与剩余框的IOU,如果其值大于一定阈值(重合度过高),那么就将该剩余框剔除;然后对剩余的未处理检测框重复上述过程,直到处理完所有的检测框。

参考
步骤1
在模型对图像进行检测之后,我们可以得到一堆检测框,并利用IoU值是否大于0.5来区分正确或错误的检测。
公式为:给定一张图像,类别C的Precision = 图像的正确预测(True Positives)的数量 / 在图像上这一类的总的目标数量。
步骤2
对于给定的类C,我们能够为验证集中的每张图像计算此值。 假设我们在验证集中有100个图像,并且我们知道每个图像都有其中的所有类,则可以得到100个该类C的的精度值,取平均值后,即为该类的平均精度。
公式为:类C的平均精度=?在验证集上所有图像对于类C的精度值的和?/?有类C这个目标的所有图像的数量。
步骤3
假设整个集合拥有20各个类,分别计算这20个类平均精度,最后再对这20个平均精度取平均之后,即得到均值平均精度(mAP)。
要点
Yolo算法将目标检测看成回归问题 ?(待理解)
YOLO之前的物体检测系统使用分类器来完成物体检测任务。为了检测一个物体,这些物体检测系统要在一张测试图的不同位置和不同尺寸的bounding box上使用该物体的分类器去评估是否有该物体。如DPM系统,要使用一个滑窗(sliding window)在整张图像上均匀滑动,用分类器评估是否有物体。
在DPM之后提出的其他方法,如R-CNN方法使用region proposal来生成整张图像中可能包含待检测物体的potential bounding boxes,然后用分类器来评估这些boxes,接着通过post-processing来改善bounding boxes,消除重复的检测目标,并基于整个场景中的其他物体重新对boxes进行打分。整个流程执行下来很慢,而且因为这些环节都是分开训练的,检测性能很难进行优化。
作者设计了YOLO(you only look once),将物体检测任务当做回归问题(regression problem)来处理,直接通过整张图片的所有像素得到bounding box的坐标、box中包含物体的置信度和class probabilities。通过YOLO,每张图像只需要看一眼就能得出图像中都有哪些物体和这些物体的位置。
Anchor box的形状是固定的吗?还是从训练中学习到的?box的边界可以超过cell的边界吗?可以的话,在训练中是如何实现的?(可能有误)
形状不是固定的。在训练数据中,包含了每一个物体所对应的边框信息和类别,训练时模型可以学习到这些边框信息,从而在预测的时候,自动某一物体进行标注。
box的边界可以超过cell的边界。当某一物体的中心点落在某一个cell中时,该cell就专门负责该物体的检测,即使该物体仍有其他部分位于其他cell中,其他cell也不能负责该物体的检测。
【个人理解】cell的边界以及数量与box的边界无关,当cell的粒度变小时,YOLO模型能够更好得对小目标进行检测,但同时也会造成更大的耗时和计算量;反之亦然。
在YOLO中,Anchor box的信息是事先设定的吗?还有是每个位置都拥有系列相同尺度和大小的anchor box?
主要的疑问是,如果YOLO没有实现设定Anchor box信息,那么在训练初始时,网络的输出中,box的4个值会变成奇形怪状的,基本上构不成一个矩形。(这种情况下,训练的收敛程度和快慢是否会受到影响?)
另外,如果YOLO的每个cell有用到事先设定好的Anchor box信息,那么不就和YOLO9000的方法一样吗?那么YOLO9000在这个方面相比于YOLO不就没有了什么改进?
为什么YOLO的localization error和recall变现比较差?
因为YOLO将图像分为k * k的格子,而格子的划分较为粗糙(以及bounding boxes的scale和aspect ratio),导致出现了较多的定位误差。
另外,由于每个cell只负责一个目标的预测,当同一个cell里出现多个物体(小目标)时,这些物体就不能够被检测到。这也就造成了recall率(查全率)的低下。
标签:img 效果 cal 查看 情况下 gil 参数 conf 运行速度
原文地址:https://www.cnblogs.com/CSLaker/p/9723136.html