标签:打开 文件 重启 mat 日志信息 应该 col 效果图 程序
1.对 hadoop 进行格式化
到 /opt/app/hadoop-2.5.0 目录下 执行命令: bin/hdfs namenode -format
执行的效果图如下 ( 下图成功 格式化 不要没事格式化 )
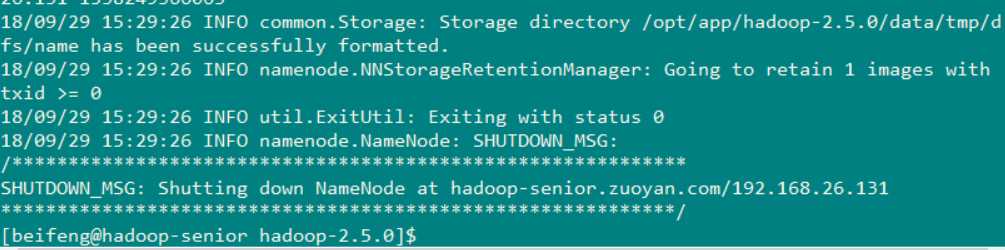
2.启动dfs
执行命令(在 /opt/app/hadoop-2.5.0/目录下): sbin/start-dfs.sh
执行之后的效果就如下图 (可以看到 3个DataNode已经启动起来了,NameNode 和 secondarynamenode 也已经启动起来了)
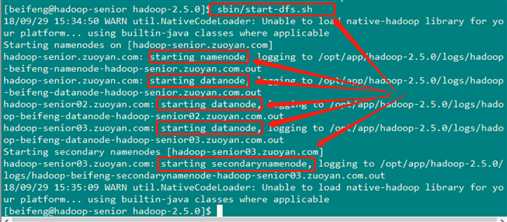
然后在分别上这三台机器上查看一下启动情况
节点一(hadoop-senior.zuoayn.com)
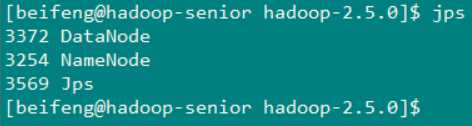
节点二 (hadoop-senior02.zuoyan.com)
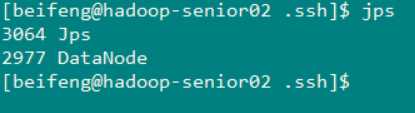
节点三(Hadoop-senior03.zuoyan.com)
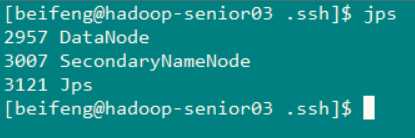
可以看到 每个节点上执行的任务 都是我们当时设计的,我的这种情况是比较幸运的没有出现什么错误,都启动起来了,但是有的时候会出现
:Temporary failure in name resolutionop-senior02.zuoyan.com
:Temporary failure in name resolutionop-senior.zuoyan.com
出现这个原因是因为 拷贝虚拟机出现的问题 出现这种情况的原因 就是域名解析问题 机器重启 ,还有另一种方式解决
就是到每个机器上单独去启动 使用命令 :sbin/hadoop-daemon.sh start datanode
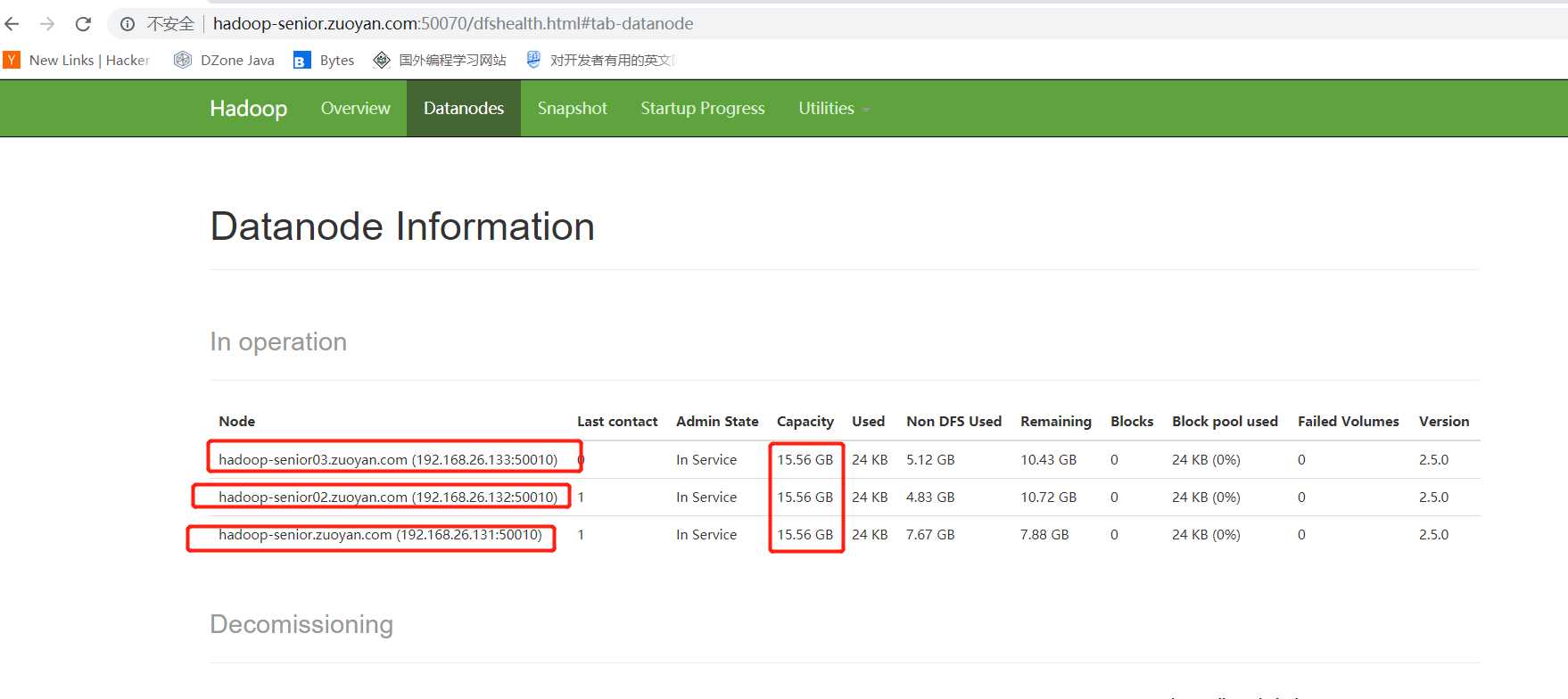
通过浏览器打开查看一下启动情况:
输入网址:http://hadoop-senior.zuoyan.com:50070(这里也就是第一个主机的ip地址,因为我映射到了windows的hosts中,所以也能通过这个主机名访问)
点击主页的 LiveNodes 就可以看见如下的界面
这个界面上显示的就是我们的节点
使用一些命令进行测试一下
创建目录命令: bin/hdfs dfs -mkdir -p /user/beifeng/tmp/conf

上传文件命令: bin/hdfs dfs -put /etc/hadoop/*.-site.xml /user/beifeng/tmp/conf

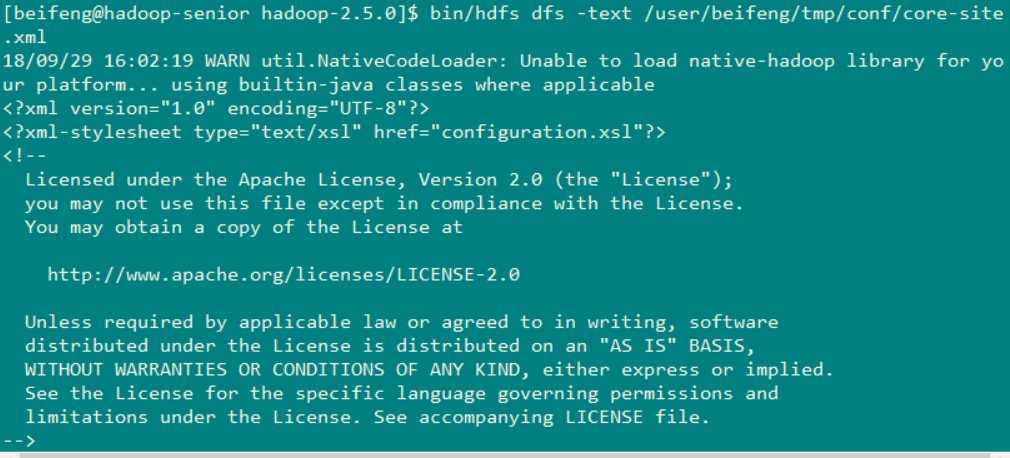
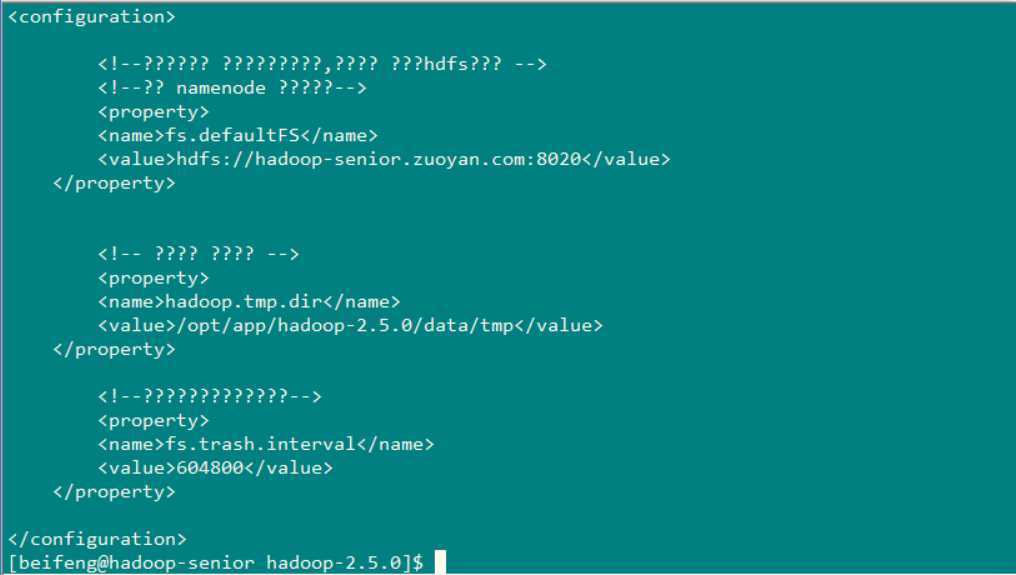
读取文件命令: bin/hdfs dfs -text /user/beifeng/tmp/conf/core-site.xml (下图就是成功的读取出来了)
3.启动yarn
(在/opt/app/hadoop-2.5.0 的目录下 ) 使用命令: sbin/start-yarn.sh
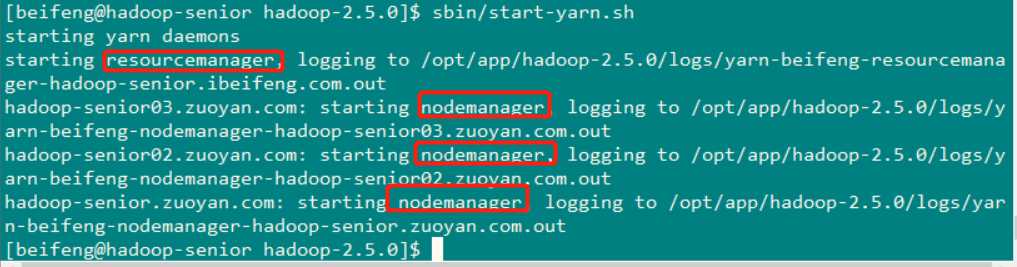
在启动yarn的时候我的出先了一个问题 就是resourcemanager 启动不起来 不论是在 第一个节点上看,还是在第二个节点上看 都没有resourcemanager
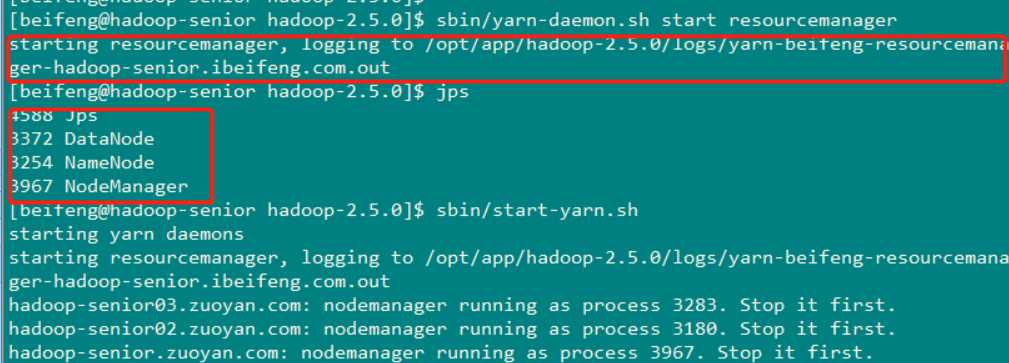
日志信息如下

最终在开源中国上查找到了解决方案
Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。
4.测试Mapreduce程序
首先创建一个目录用来存放输入数据 命令: bin/hdfs dfs -mkdir -p /user/beifeng/mapreduce/wordcount/input

上传文件到文件系统上去 命令:bin/hdfs dfs -put /opt/modules/hadoop-2.5.0/wc.input /user/beifeng/mapreduce/wordcount/input

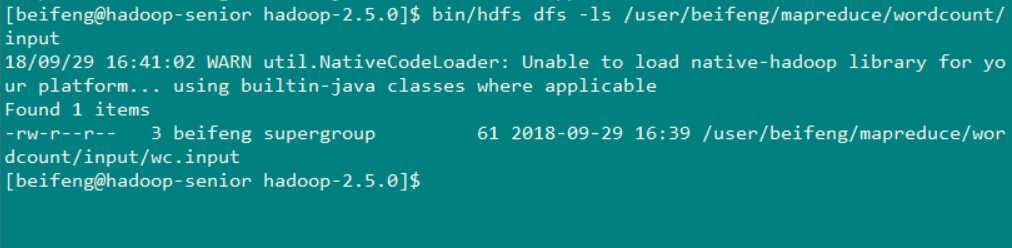
使用命令查看一下文件是否上传成功 命令:bin/hdfs dfs -ls /user/beifeng/mapreduce/wordcount/input (可以看到wc.input 已经在这个目录下)
完成准备工作之后 就开始使用 yarn 来运行wordcount 程序
命令: bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/beifeng/mapreduce/wordcount/input /user/beifeng/mapreduce/wordcount/output
程序已经开始在机器上运行了
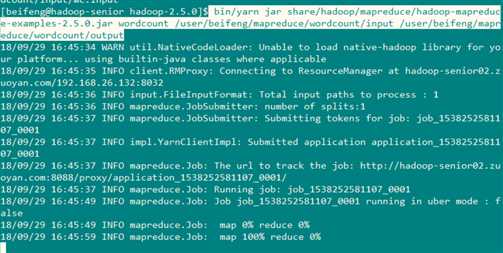
从WEB页面上看到的效果
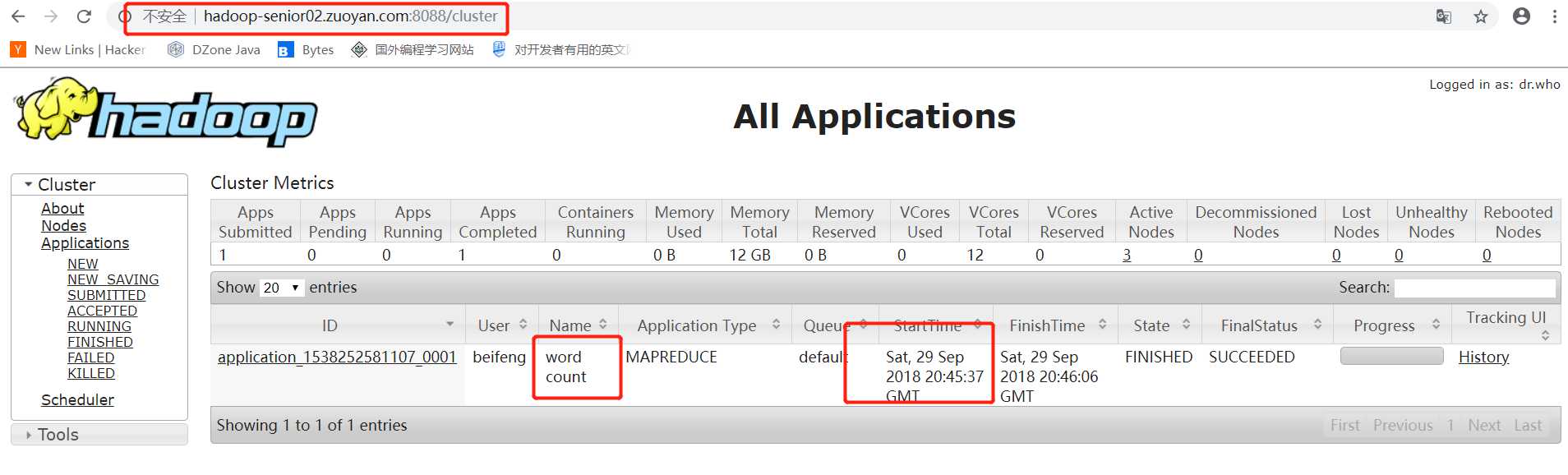
最后在使用hdfs 的命令来查看一下 wordcount 统计的结果 命令 :bin/hdfs -dfs -text /user/beifeng/mapreduce/wordcount/output/part*
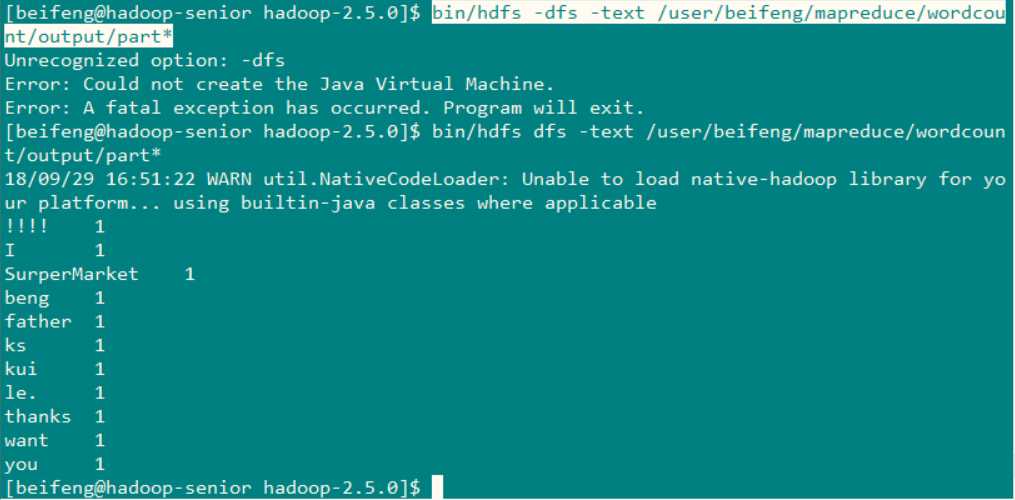
到此 配置结束,但是剩下的还有 环境问题解决 和 集群基础测试
【Hadoop 分布式部署 五:分布式部署之分发、基本测试及监控】
标签:打开 文件 重启 mat 日志信息 应该 col 效果图 程序
原文地址:https://www.cnblogs.com/kangxinxin/p/9726811.html