标签:info 方法 bsp 占用 区别 卡死 nbsp 图片 技术分享
起初在linux上想使用Map/Reduce来完成操作,发现需要导入的jar包过多,大概在6点左右写完程序却跑不起来,一直在找jar包,直接被卡死在这里。
从教室回来之后,发现好多人都是在windows下完成的操作。突然想起来,暑假里按教程做的那个精准推送的实例,也是在windows的eclipse上编写好代码,将文本文件也放入,打成jar包,然后在linux虚拟机上启用hadoop来进行调用完成操作。
所以换了一种方法,改成在windows下编程,通过hadoop的jar包来连接虚拟机完成操作。
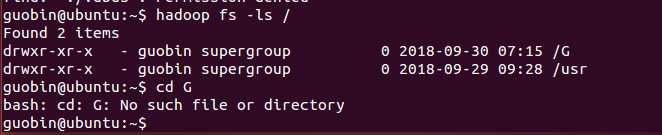
这是实验完成的截图。
中途遇到了一些问题,比如:
1、连接9000端口失败。我原来做伪分布的配置时将core-site.xml中的配置改成了localhost:8080,那时候是习惯这个号。
现在两个问题,第一点要将localhost这个只用于本机的改成虚拟机的ip地址,就从ifconfig可以查出来。
第二点,8080改成大多数人通用的9000,其实我也不知道这俩的区别在哪里,不过8080经常需要使用,这也可以防止端口互相占用。
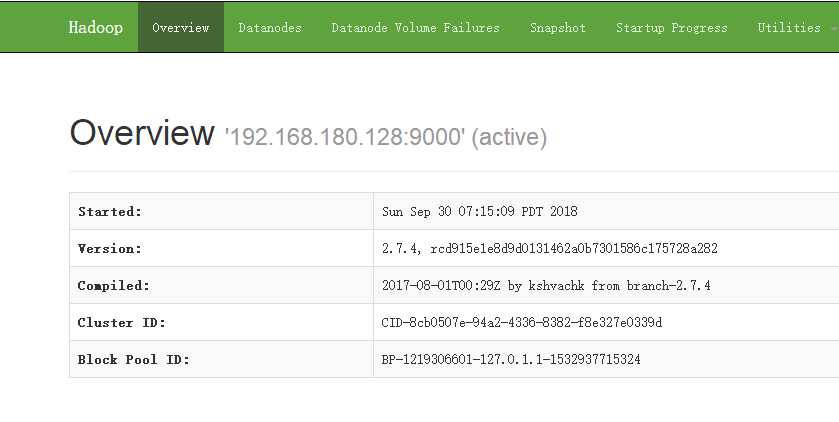
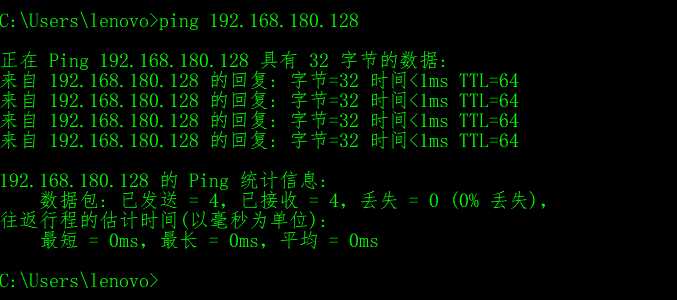
2、主机和虚拟机的连接问题,出现了一些小意外,已解决,截图如下:
在自己主机下能登录(http://192.168.180.128:50070/):
在cmd里能ping通:
剩下的就是一些代码上的小问题,这里要给自己长个记性就是要重点注意路径,因为它一般写在字符串里,即便有错误也不会主动报错,很隐秘。
附上实验要求输出内容的截图:

标签:info 方法 bsp 占用 区别 卡死 nbsp 图片 技术分享
原文地址:https://www.cnblogs.com/guobin-/p/9733645.html