标签:迭代 none red count 优化 技术 glob ntop point
1、生成高斯分布的随机数
导入numpy模块,通过numpy模块内的方法生成一组在方程
y = 2 * x + 3
周围小幅波动的随机坐标。代码如下:
1 import numpy as np 2 import matplotlib.pyplot as plot 3 4 5 def getRandomPoints(count): 6 xList = [] 7 yList = [] 8 for i in range(count): 9 x = np.random.normal(0, 0.5) 10 y = 2 * x + 3 + np.random.normal(0, 0.3) 11 xList.append(x) 12 yList.append(y) 13 return xList, yList 14 15 16 if __name__ == ‘__main__‘: 17 X, Y = getRandomPoints(1000) 18 plot.scatter(X, Y) 19 plot.show()
运行上述代码,输出图形如下:
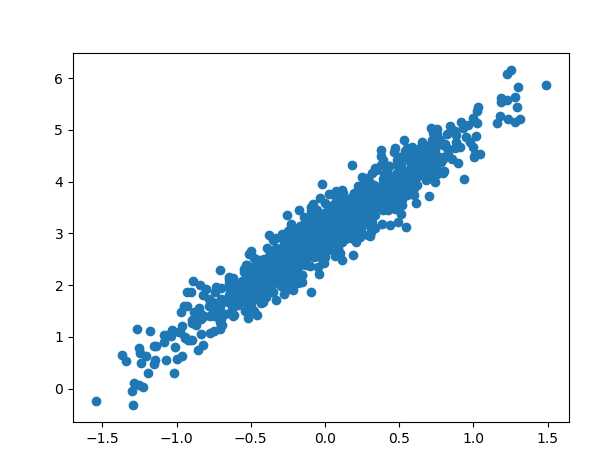
2、采用TensorFlow来获取上述方程的系数
首先搭建基本的预估模型y = w * x + b,然后再采用梯度下降法进行训练,通过最小化损失函数的方法进行优化,最终训练得出方程的系数。
在下面的例子中,梯度下降法的学习率为0.2,训练迭代次数为100次。
1 def train(x, y): 2 # 生成随机系数 3 w = tf.Variable(tf.random_uniform([1], -1, 1)) 4 # 生成随机截距 5 b = tf.Variable(tf.random_uniform([1], -1, 1)) 6 # 预估值 7 preY = w * x + b 8 9 # 损失值:预估值与实际值之间的均方差 10 loss = tf.reduce_mean(tf.square(preY - y)) 11 # 优化器:梯度下降法,学习率为0.2 12 optimizer = tf.train.GradientDescentOptimizer(0.2) 13 # 训练:最小化损失函数 14 trainer = optimizer.minimize(loss) 15 16 with tf.Session() as sess: 17 sess.run(tf.global_variables_initializer()) 18 # 打印初始随机系数 19 print(‘init w:‘, sess.run(w), ‘b:‘, sess.run(b)) 20 # 先训练个100次: 21 for i in range(100): 22 sess.run(trainer) 23 # 每10次打印下系数 24 if i % 10 == 9: 25 print(‘w:‘, sess.run(w), ‘b:‘, sess.run(b)) 26 27 28 if __name__ == ‘__main__‘: 29 X, Y = getRandomPoints(1000) 30 train(X, Y)
运行上面的代码,某次的最终结果为:
w = 1.9738449
b = 3.0027733
仅100次的训练迭代,得出的结果已十分接近方程的实际系数。
某次模拟训练中的输出结果如下:
init w: [-0.6468966] b: [0.52244043] w: [1.0336646] b: [2.9878206] w: [1.636582] b: [3.0026987] w: [1.8528996] b: [3.0027785] w: [1.930511] b: [3.0027752] w: [1.9583567] b: [3.0027738] w: [1.9683474] b: [3.0027735] w: [1.9719319] b: [3.0027733] w: [1.9732181] b: [3.0027733] w: [1.9736794] b: [3.0027733] w: [1.9738449] b: [3.0027733]
3、完整代码和结果
完整测试代码:

1 import numpy as np 2 import matplotlib.pyplot as plot 3 import tensorflow as tf 4 5 6 def getRandomPoints(count, xscale=0.5, yscale=0.3): 7 xList = [] 8 yList = [] 9 for i in range(count): 10 x = np.random.normal(0, xscale) 11 y = 2 * x + 3 + np.random.normal(0, yscale) 12 xList.append(x) 13 yList.append(y) 14 return xList, yList 15 16 17 def train(x, y, learnrate=0.2, cycle=100): 18 # 生成随机系数 19 w = tf.Variable(tf.random_uniform([1], -1, 1)) 20 # 生成随机截距 21 b = tf.Variable(tf.random_uniform([1], -1, 1)) 22 # 预估值 23 preY = w * x + b 24 25 # 损失值:预估值与实际值之间的均方差 26 loss = tf.reduce_mean(tf.square(preY - y)) 27 # 优化器:梯度下降法 28 optimizer = tf.train.GradientDescentOptimizer(learnrate) 29 # 训练:最小化损失函数 30 trainer = optimizer.minimize(loss) 31 32 with tf.Session() as sess: 33 sess.run(tf.global_variables_initializer()) 34 # 打印初始随机系数 35 print(‘init w:‘, sess.run(w), ‘b:‘, sess.run(b)) 36 for i in range(cycle): 37 sess.run(trainer) 38 # 每10次打印下系数 39 if i % 10 == 9: 40 print(‘w:‘, sess.run(w), ‘b:‘, sess.run(b)) 41 return sess.run(w), sess.run(b) 42 43 44 if __name__ == ‘__main__‘: 45 X, Y = getRandomPoints(1000) 46 w, b = train(X, Y) 47 plot.scatter(X, Y) 48 plot.plot(X, w * X + b, c=‘r‘) 49 plot.show()
最终效果图如下,蓝色为高斯随机分布数据,红色为最终得出的直线:
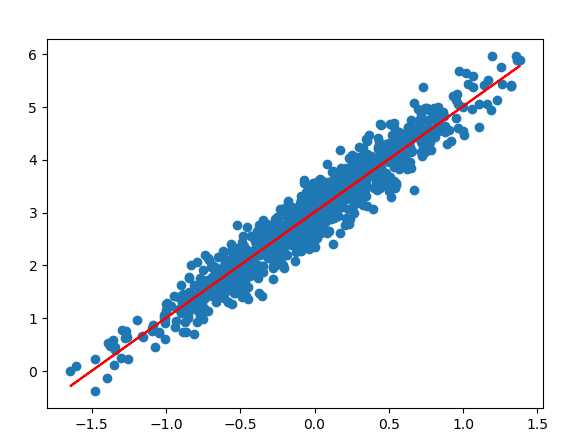
本文地址:https://www.cnblogs.com/laishenghao/p/9571343.html
标签:迭代 none red count 优化 技术 glob ntop point
原文地址:https://www.cnblogs.com/laishenghao/p/9571343.html
