标签:sep base 取出 利用 输入 htm CNN网络 线性 ssim
目录
Home page
http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html2014 ECCV ,2015 TPAMI .
This problem (SR) is inherently ill-posed since a multiplicity of solutions exist for any given low-resolution pixel.
Such a problem is typically mitigated by constraining the solution space by strong prior information.
注:训练 CNN 就是在学习先验知识。
传统方法着重于学习和优化 dictionaries ,但对其他部分鲜有优化。
但对于CNN,其卷积层负责 patch extraction and aggregation ,隐藏层充当 dictionaries ,因此都会被统一优化。
换句话说,我们只需要极少的 pre/post-processing 。
过去,我们用 a set of pre-trained bases such as PCA, DCT, Haar 来表示 patches 。
现在,我们用不同的卷积核,就实现了多样化的表示。
由于 overlapping ,因此卷积使用的像素信息比简单的字典映射更多。
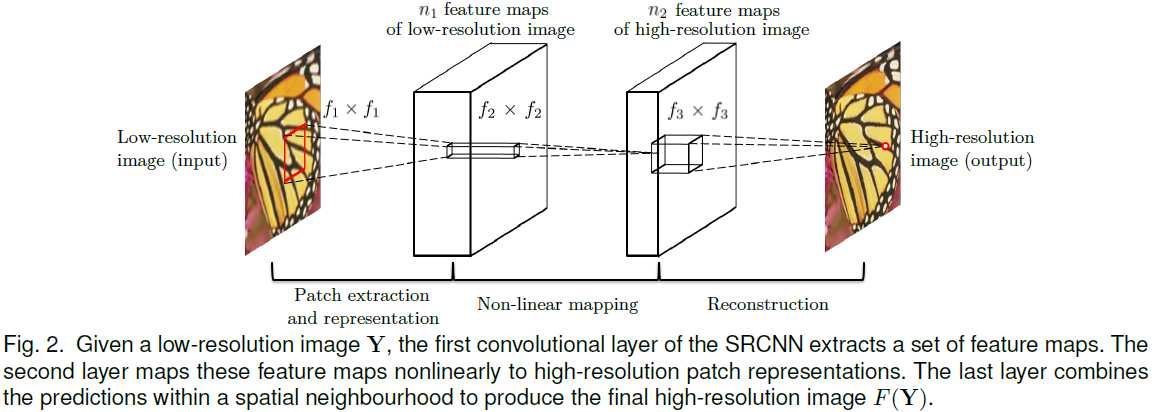
将低分辨率的图片,通过 Bicubic interpolation 得到 \(\mathbf Y\) 。注意我们仍然称之为 low-resolution image 。
从 \(\mathbf Y\) 提取出 overlapping patches ,每一个 patch 都代表一个 high-dimensional vector 。
这些向量共同组成一个 set of feature maps 。
每一个 vector 的维数,既是总特征数,也是 feature map 的总数。
\[ F_1(\mathbf Y) = max(0, W_1 * \mathbf Y + B_1) \]
通过一个非线性变换,由原 high-dimensional vector 变换到另一个 high-dimensional vector 。
该 high-dimensional vector 又组成了一个 set of feature maps ,在概念上代表着 high-resolution patch 。
\[ F_2(\mathbf Y) = max(0, W_2 * F_1(\mathbf Y) + B_2) \]
生成接近 ground truth: \(\mathbf X\) 的 output 。
过去常用取平均的方法。实际上,平均也是一个特殊的卷积。
因此我们不妨直接用一个卷积。
此时,输出patch不再是简单的平均,还可以是频域上的平均等(取决于 high-dimensional vector 的性质)。
\[ F_3(\mathbf Y) = W_2 * F_2(\mathbf Y) + B_3 \]
注意不要再非线性处理。
Traditional sparse-coding-based SR methods
从低分辨率图像到 \(\mathbf Y\) 采用的是 Bicubic interpolation ,实际上也是卷积。但为什么不当作卷积层呢?
文中解释,因为输出比输入还大,为了有效利用 well-optimized implementations sucha as cuda-convnet ,就暂且不当作一个“层”。
Overview:end-to-end深度学习网络在超分辨领域的应用(待续)
标签:sep base 取出 利用 输入 htm CNN网络 线性 ssim
原文地址:https://www.cnblogs.com/RyanXing/p/9736106.html