标签:append generate 联系 相关 sans size 关联 learn figure
偷懒若干天后回归。。在上一篇中我们得到了NLPCC2013的中文微博数据,将其按照8:1:1的比例分成了训练集,验证集和测试集。下一步就是对数据进行预处理以及embedding。这是第一次尝试一边写博客一边把自己的想法记录下来,希望有所帮助。
分析:按照体量的大小可以将文本分为字级别->词级别->实体级别->句子级别->段落级别->文章级别。由于我们的任务主要是情感识别,通常情况下可以代表情感的往往只是某些字或词,所以对于数据的预处理最多进行到分词,不许要做NER。只要基于当前数据做出正确的分词并且embedding,即可作为文章的输入。分词工具在这里选择开源并且遵守MIT(个人理解为可以商用)的jieba分词。先看一下数据的分词难点:
#回复@王羊羊的微博:是,要的就是安静的生存环境,而且,到北京五环25分#钟车程,938离我住处只有300米,饮食一条街更是北京饮食街的翻版,应有尽有。 #//@王羊羊的微博:廊坊是个好地方,紧邻京津,有点闹中取静的意思。 #[抓狂]我竟然被那个考了车牌几个月但一直没有开过车的老妈笑话我笨! #这家位于槟城George Town,Tunes Hotel斜对面的饼家,家庭式作业,她#的咸蛋酥,年糕椰蓉酥,叉烧酥都很不错。[good] #做人原则:⑴能不骂人,就不骂! #联系方式:13810938511 QQ:122095021
以上几条微博可以反映出这个数据存在的某些问题:存在回复标签,存在表情符号,中英混用,全半角符号混用,数字问题。之前也做过推特的情感分类,发现同为社交媒体,中文社交媒体的数据处理要比英文复杂的多。对于这种情况,我首先观察了一下数据特点,然后直接根据每种不同情况作了相应处理,在这里不再赘述,想看的朋友们可以直接看最后放出的代码,写的还算比较清楚,每个功能都写成了一个小函数。
本来想分词之后直接训练embedding的,但是考虑到一共才4w多个样本,而且很多都不符合一般的语言规范,想了想还是用了别人的embedding。链接在此:https://github.com/facebookresearch/fastText/blob/master/pretrained-vectors.md 但是考虑到用了别人的embedding正常情况下就可以开始搭模型了。在这里多做了一步工作就是对数据进行了一个可视化。代码同样在下面。
可视化分为了两个部分:构建词云和词向量的可视化。前者基本可以理解为找到文本中的若干关键词并可视化,后者即为将embedding降维后得到的结果。
先看一下词云:

可以看到由于数据源是网络文本,即使去掉停词后还是有大量的口语/无意义词汇,但是好在从其中一些小字也可以找到一些微博早期大家关注的热点,如果沿时间横向对比的话,应该是可以得到一些有意思的结论的。最直观的一个结论可以看到词云中出现的两个国家美国和日本,代表了网民门讨论的热点国家,还是比较符合实际的。下面一张图做了一些美化,本质上还是这个东西。

做完了词云,再来看一下词向量降维得到的结果。经过统计数据里面实际上有两万多个可以和词向量对应的词语,全部显示基本是不可能了,差点没把我这破air累死。最终选取了其中500个词,尽管这样还是需要截图才能看到一个大概的趋势。其实这样一个统计就类似于聚类的结果统计,只不过使用cosine距离作为度量,具体实现是用的sklearn的tsne模块。看一看哪些和哪些是比较相似的。也检查一下embedding的情况怎么样,是否能反映语义信息。整个图里面的点大概聚成了即堆,挑有代表性的讨论讨论。

可以看到一些平时相关的词语确实距离非常近
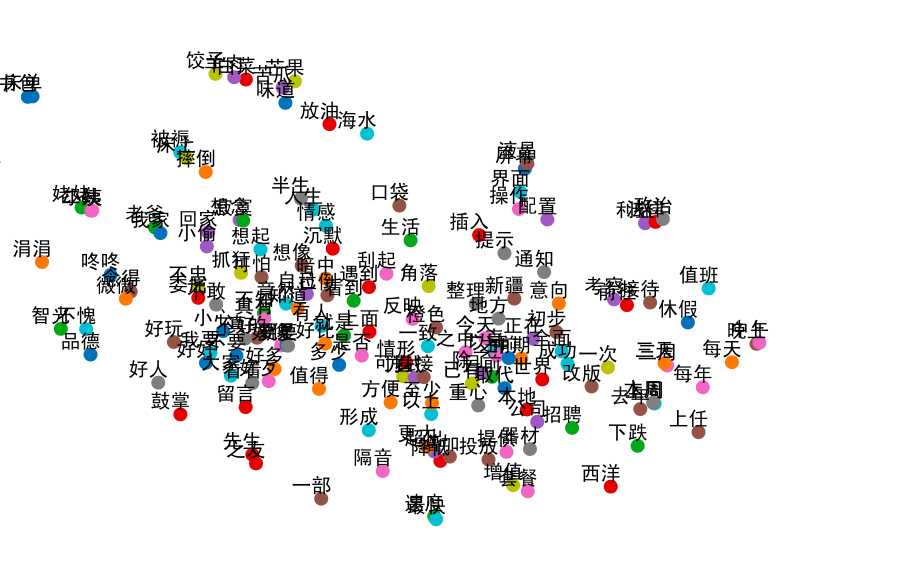
这里是第二堆词,其实和第一堆并不能发现什么太大的差别,导致出现两堆的情况很有可能是因为这两堆都是高维空间投射到2维空间的影子。实际上两堆各自内部的词应该还与另一堆有关联。

这一堆基本都是单个字或者标点符号,没有吧标点符号全部去掉的原意主要就是因为像!?...这样的符号其实是很大程度上可以反映情绪的,所以除了一些确实不必要的其他都保留了下来。但是可以看到也有一些小瑕疵,比如/这种符号还是没有去干净。
其实以上这些可视化不仅可以用来做情感分析,还可以做一些舆情分析,本质上是一样的。下面Po出所有源代码,写的不太好还请各路大神多指教~我只是个小白哈哈~
import jieba import re import gensim import collections import matplotlib.pyplot as plt from wordcloud import WordCloud from wordcloud import STOPWORDS import numpy as np from PIL import Image from gensim.models import KeyedVectors from sklearn.manifold import TSNE import tqdm import matplotlib from matplotlib import font_manager #matplotlib.use(‘qt4agg‘) input_file = open("data_all.txt") counter = 0 corpora = [] real_vocab = [] """ 第一部分,预处理和分词 """ def chn_tokenize(sentence): # 使用jieba分词实现完整的中文数据集分词 line_list = jieba.lcut(sentence, HMM=True) return line_list #print(line_list) def del_reply_mark(sentence): output = re.sub(‘@.*?:‘, ‘‘, sentence).strip("回复").strip("//") output = re.sub(‘@.*? ‘, ‘‘, output) if output == "": output = "***" #print(output) return output def rep_chn_punc(sentence): table = {ord(f): ord(t) for f, t in zip( u‘,。!?【】()%#@&1234567890①②③④⑤、·:[]():;‘, u‘,.!?....%#@&123456789012345,........‘)} output = sentence.translate(table).replace("...", "…").replace("《", "").replace("》", "").replace("℃", "度") .replace("——", "").replace("..", "…").replace("「", "").replace("」", "").replace("....", "…") .replace(".....", "…").replace(".", "").replace(",", "").replace("-", "").replace("T T", "TT") .replace("T_T", "TT") return output def clean_pun(sentence): strip_special_chars = re.compile("[^A-Za-z0-9]+") output = re.sub(strip_special_chars, "", sentence) return output for i in tqdm.tqdm(input_file.readlines()): sen = rep_chn_punc(i) sen = del_reply_mark(sen).strip("\n").strip("\t").strip(".") counter += 1 #print(sen) word_list = chn_tokenize(sen) try: while word_list.index(" "): del word_list[word_list.index(" ")] except ValueError: #print(word_list) corpora.append(word_list) for j in range(len(word_list)): if word_list[j] not in real_vocab: real_vocab.append(word_list[j]) print(counter) """ 第二部分, """ def word_freq(text): corpora_in_line = [] for line in range(len(text)): corpora_in_line.extend(text[line]) frequency = collections.Counter(corpora_in_line) print(frequency) def word_cloud(text, path): stopwords = set(STOPWORDS) weibo = np.array(Image.open(path)) stopwords.add("一个") corpora_in_str = "" for line in range(len(text)): str_text = " ".join(text[line]) #print(str_text) corpora_in_str += str_text my_wordcloud = WordCloud(font_path=‘SimHei.ttf‘, stopwords=STOPWORDS , width=1500, height=750, background_color="black").generate(corpora_in_str) plt.imshow(my_wordcloud) plt.axis("off") plt.show() def plot_with_labels(low_dim_embs, labels, filename=‘tsne.pdf‘): #from matplotlib import rcParams myfont = font_manager.FontProperties(fname=‘SimHei.ttf‘) #matplotlib.rcParams[‘font.family‘] = ‘sans-serif‘ matplotlib.rcParams[‘font.family‘] = [‘SimHei‘] #matplotlib.rcParams[‘axes.unicode_minus‘] = False assert low_dim_embs.shape[0] >= len(labels), "More labels than embeddings" plt.figure(figsize=(18, 18)) # in inches print("flag2") for i, label in enumerate(labels): x, y = low_dim_embs[i, :] plt.scatter(x, y) plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords=‘offset points‘, ha=‘right‘, va=‘bottom‘) plt.savefig(filename) #wiki.zh.vec def embedding(model_path, vocab): zh_model = KeyedVectors.load_word2vec_format(model_path) embedding = np.array([]) show_vocab = [] for m in range(len(vocab)): if vocab[m] in STOPWORDS: continue if len(show_vocab) > 499: break if vocab[m] in zh_model.vocab: show_vocab.append(vocab[m]) embedding = np.append(embedding, zh_model[vocab[m]]) print(len(show_vocab)) embedding = embedding.reshape(len(show_vocab), 300) tsne = TSNE() print("flag0") low_dim_embedding = tsne.fit_transform(embedding) print("flag1") plot_with_labels(low_dim_embedding, show_vocab) #word_freq(corpora) #word_cloud(corpora, "weibologo.jpg") embedding("wiki.zh.vec", real_vocab)
如果你看到了这里并且喜欢这篇博客,希望你可以给EST凌晨4点还在写博客的博主一点支持~鼓励我写出更多更好的博客~谢谢啦~

标签:append generate 联系 相关 sans size 关联 learn figure
原文地址:https://www.cnblogs.com/yunke-ws/p/9734432.html