标签:技术分享 word nbsp 原理 多个 str 假设 输出 分类
一、W2V的两种模型:CBOW和Skip-gram
W2V有两种模型,分别为CBOW和skip-gram,CBOW是根据上下文$context(w)$来预测中间词$w$,而skip-gram是根据中间词$w$来预测上下文$context(w)$;他们都有3层结构——输入层,投影层,输出层。(注:无隐藏层)
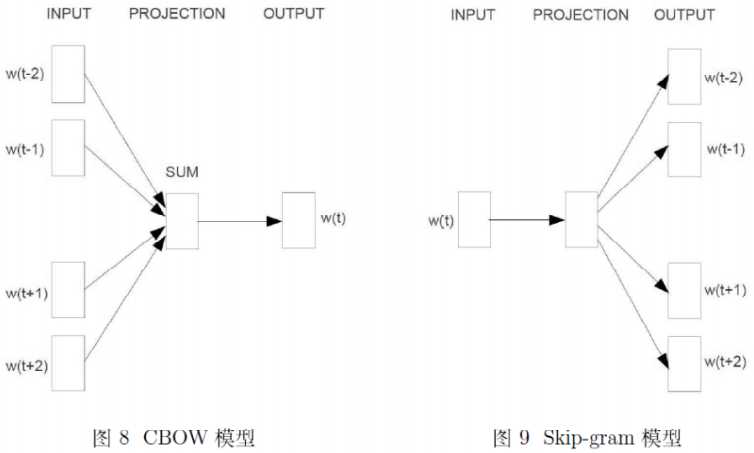
二、基于huffuman的CBOW
1、网络结构
CBOW的网络机构有3层,分别为输入层,投影层,输出层;以样本$(context(w),w)$为例,做简要说明。
输入层:上下文的2c个词的词向量$v(context(x))$(假设上文和下文分别为c各词)
投影层:将这个2c个向量直接求和,$x_{w}=\sum_{i=1}^{2c}v(context(w)_{i}))$
输出层:对应一棵huffuman树,它以词典中的词为叶节点,以词出现的次数为权重;其中叶节点的个数为N,非叶节点的个数为(N-1)
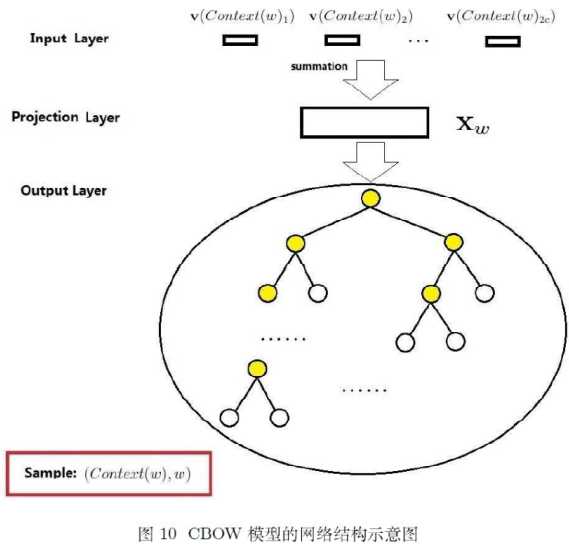
注:在以往的神经网络语言模型中,计算量高的地方在输出层矩阵运算和概率归一化,CBOW对此作出了两点改进:1、无隐藏层,输入层直接向量求和进行投影;2、输出层改为huffuman树,将原来的softmax线性搜索求极大(多分类),转化为求树的正确路径(多个二分类),大大减少计算量。
2、参数计算
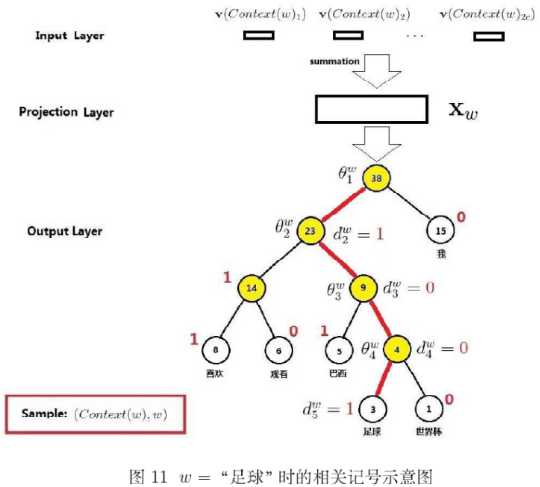
huffuman softmax是提高W2V效率的关键所在,以词典中的某个词w为例,约定一些符号
$p^{w}$:词w对应的路径
$l^{w}$:词w对应路径上的节点个数
$p_{i}^{w},(i\in {1,2,...,l_{w}})$:路径$p^{w}$上的某个节点
$[d_{2}^{w},d_{3}^{w}...d_{l_{w}}^{w}]$:词w的huffuman编码。(注:无根节点)
$\theta_{i}^{w},(i\in {1,2,...,l_{w}-1})$:路径$p^{w}$上,内部节点的权重向量。因为每个内部节点对应一个二分类器,这些权重就是二分类器的参数(注:无叶节点)
三、基于hufuman的skip-gram
word2vec的数学原理(二)——基于huffuman softmax
标签:技术分享 word nbsp 原理 多个 str 假设 输出 分类
原文地址:https://www.cnblogs.com/liguangchuang/p/9738947.html