标签:auth esc ons line info www. mos https 规则
一:Crawlspider简介
CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能。其中最显著的功能就是”LinkExtractors链接提取器“。Spider是所有爬虫的基类,其设计原则只是为了爬取start_url列表中网页,而从爬取到的网页中提取出的url进行继续的爬取工作使用CrawlSpider更合适。
二:Crawlspider使用
实例:爬取https://www.qiushibaike.com/主页帖子作者以及内容
1.创建scrapy工程
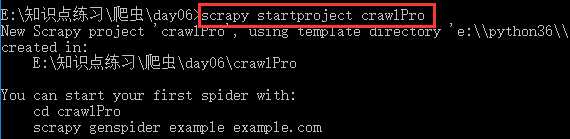
2.创建爬虫文件

注意:对比以前的指令多了 "-t crawl",表示创建的爬虫文件是基于CrawlSpider这个类的,而不再是Spider这个基类。
3.生成的目录结构如下:
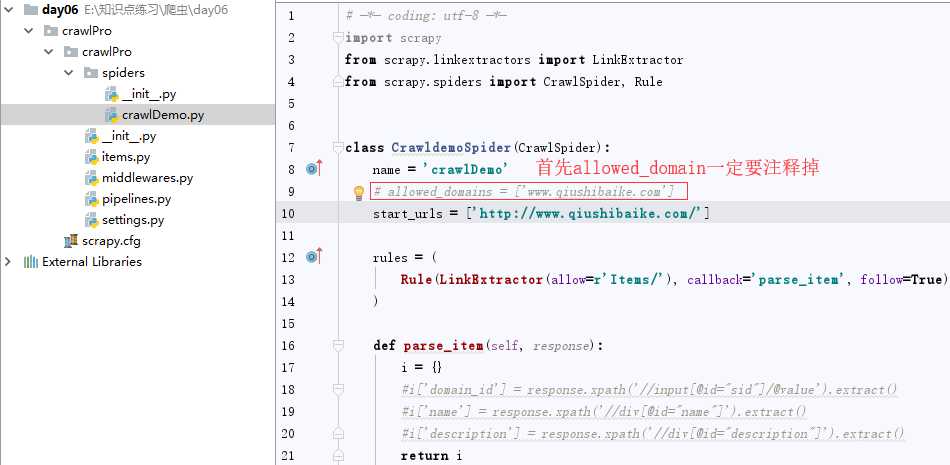
CrawlDemo.py爬虫文件设置:
LinkExtractor:顾名思义,链接提取器。
Rule : 规则解析器。根据链接提取器中提取到的链接,根据指定规则提取解析器链接网页中的内容。
Rule参数介绍:
参数1:指定链接提取器
参数2:指定规则解析器解析数据的规则(回调函数)
参数3:是否将链接提取器继续作用到链接提取器提取出的链接网页中,当callback为None,参数3的默认值为true。
rules=( ):指定不同规则解析器。一个Rule对象表示一种提取规则。
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from crawlPro.items import CrawlproItem class CrawldemoSpider(CrawlSpider): name = ‘crawlDemo‘ # allowed_domains = [‘www.qiushibaike.com‘] start_urls = [‘http://www.qiushibaike.com/‘] #rules元祖中存放的是不同规则解析器(封装好了某种解析规则) rules = ( # Rule: 规则解析器,可以将连接提取器提取到的所有连接表示的页面进行指定规则(有中间的回调函数决定)的解析 #LinkBxtractor:连接提取器,会去上面起始url响应回来的页面中,提取指定的url Rule(LinkExtractor(allow=r‘/8hr/page/\d+‘), callback=‘parse_item‘, follow=True), #follow=True可以跟进保证将所有页面都提取出来(实际就是去重功能) ) def parse_item(self, response): # i = {} # #i[‘domain_id‘] = response.xpath(‘//input[@id="sid"]/@value‘).extract() # #i[‘name‘] = response.xpath(‘//div[@id="name"]‘).extract() # #i[‘description‘] = response.xpath(‘//div[@id="description"]‘).extract() # return i divs=response.xpath(‘//div[@id="content-left"]/div‘) for div in divs: item=CrawlproItem() #提取糗百中段子的作者 item[‘author‘] = div.xpath(‘./div[@class="author clearfix"]/a[2]/h2/text()‘).extract_first().strip(‘\n‘) # 提取糗百中段子的内容 item[‘content‘] = div.xpath(‘.//div[@class="content"]/span/text()‘).extract_first().strip(‘\n‘) yield item #将item提交到管道
item.py文件设置:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class CrawlproItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() author=scrapy.Field() content=scrapy.Field()
pipelines.py管道文件设置:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class CrawlproPipeline(object): def __init__(self): self.fp = None def open_spider(self,spider): print(‘开始爬虫‘) self.fp = open(‘./data.txt‘,‘w‘,encoding=‘utf-8‘) def process_item(self, item, spider): # 将爬虫文件提交的item写入文件进行持久化存储 self.fp.write(item[‘author‘]+‘:‘+item[‘content‘]+‘\n‘) return item def close_spider(self,spider): print(‘结束爬虫‘) self.fp.close()
爬虫Scrapy框架-Crawlspider链接提取器与规则解析器
标签:auth esc ons line info www. mos https 规则
原文地址:https://www.cnblogs.com/yangzhizong/p/9741196.html