标签:try hat drivers current fine question mit most attention
Preface: Most of the answers below are written by myself --- only instructors are given access to the exercise solutions. If you find anything wrong, please let me know so that I can correct them, thank you!
This is because we should saving the current task state on (separate)kernel-level stack instead of user-level stack, for two reasons:
Let‘s say, a server is infected by cryptomining malware/virus. If the screen’s buffer memory can be modified arbitrarily, then the malicious process can modify the CPU occupancy rate displayed by the task manager, making it difficult for the system administrator to detect which process is occupying a large amount of computational resources.
Three checks will be implemented:
a. Explain where in the operating system this instruction would be used.
b. Explain what happens if an application program executes this instruction.
a. As mentioned in question 6, in those four cases the iret command will be used.
b. The iret instruction will use the cs:eip, eflags and ss:esp from kernel‘s interrupt stack to restore the code segment, program counter, execution flags, stack segment, and stack pointer, thus switching the mode of operation from kernel-mode to user-mode.
a. What is the effect on the operating system of having a large number of registers?
b. What hardware features would you recommend adding to the design?
c. What happens if the hardware designer also wants to add a 16-stage pipeline into the CPU, with precise exceptions. How would that affect the user-kernel switching overhead?
a. The operating system will have the ability to execute user- and kernel-mode switches very efficiently, since it almost never need to save current task‘s state on stack with so many available registers.
b. Just like the SPARC architecture, we need to defined a set of register windows that operate like a hardware stack. Each register window includes a full set of the registers defined by the processor instruction set. When the processor performs a procedure call, it shifts to a new windows, so the compiler never needs to save and restore registers across procedure calls or mode switch, making them quite fast.
c. With the pipeline design, there is a chance when an interrupt arrives, the instructions will be in different stages on pipeline. So we have to let the hardware first completes all instructions that occur, in program
order, before the interrupted instruction. Then wait for the hardware to annul any instruction that occurs, in program order, after the interrupt or trap, even if the instruction is in progress when the processor detects the interrupt, which will increase the user-kernel switching overhead.
a. Why do instructions like popf prevent transparent virtualization of the (old) x86 architecture?
b. How would you change the (old) x86 hardware to fix this problem?
a. Let‘s say, a popf instruction is about to be executed in guest kernel mode, but from the respect of hardware, there is only one privileged mode - the host kernel mode, so the popf will only change the ALU flags, which is not what guest kernel expects to happen.
b. We should change the hardware so that the host operating system can trace whether a instruction like popf is executed in guest kernel mode or guest user mode(e.g., a flag bit), thus making transparent virtualization possible.
Actually the definition of "application starts running" is quite vague. Is it means when __libc_start_main starts the main procedure in the program(the first line of code written by programmer), or when the kernel starts the process for the program?
Given that in most contexts, we are talking about the latter case, then it is the kernel(loader) who loads the initial value in the program counter. To start a new process, it copies the program into memory, sets the program counter to the first instruction of the process, sets the stack pointer to the base of the user stack, and finally switches to user mode.
Hardware design for I/O virtualization: For I/O virtualization, underlying processor architecture can be designed such that a user level program like a guest operating system running in a virtual machine has the same hardware support as underlying host operating system and is able to directly handle its own system calls, interrupts and exceptions without delegating them to host operating system. Various I/O devices can also be designed in a way that they are able to have direct transfers with guest operating system without routing them through the host operating system.
Software design for I/O virtualization: On software front, new device drivers will need to be defined that facilitate direct transfers with guest operating system. Moreover, sandboxing feature can be incorporated in order to allow guest operating system to safely execute user-level/third-party applications.
test.c:
#include <stdio.h>
#include <time.h>
#include <unistd.h>
#define CALLTIMES 10000
void simple_procedure(void)
{
return;
}
int main(int argc, char const *argv[])
{
clock_t start, end;
double cpu_time_used_function, cpu_time_used_syscall;
start = clock();
{
for (int i = 0; i < CALLTIMES; ++i)
{
simple_procedure();
}
}
end = clock();
cpu_time_used_function = ((double) (end - start)) / CLOCKS_PER_SEC;
start = clock();
{
for (int i = 0; i < CALLTIMES; ++i)
{
getpid();
}
}
end = clock();
cpu_time_used_syscall = ((double) (end - start)) / CLOCKS_PER_SEC;
printf("simple user function call for 10000 times: %f\n", cpu_time_used_function);
printf("simple kernel system call for 10000 times: %f\n", cpu_time_used_syscall);
return 0;
}
Output:
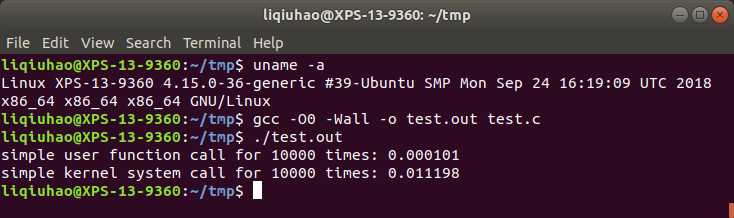
It seems like the overhead of this system call is nearly 100 times more than a user function call. That‘s because operating system have to switch between user mode and kernel mode when a system call happens, which is accompanied by necessary storage (such as saving user task status) and computing operations (such as determining whether the user task‘s status is legal at this time). But for the user mode call, it only requires parameter passing and call operations, which so takes much less time.
Yes we can, if we treat trap as a kind of exceptions(actually I think this is what intel x86 implement it - the classes of exceptions are trap, fault and abort).
If the underlying hardware does not provide a trap instruction, an OS can use exceptions hardware support as a hack. For example, an OS can have the convention that executing an invalid instruction with a valid parameter(which was determined by OS) in specific place(e.g., register %rax) will make kernel act as executing a trap(or system call) instruction. This is because an invalid instruction will cause an exception that immediately transfers control to the kernel, and then the kernel can check the parameter user have passed and decide what to do next.
This answer is written by voelker@cs.ucsd.edu
In this situation, it would not be possible to use exceptions or traps to substitute for interrupts.Exceptions and traps are synchronous, and interrupts are inherently asynchronous; exceptions and traps happen as a result of process doing something, whereas interrupts are external events that happen at unpredictable times. Going back to the timer interrupt, for example, we would not be able to interrupt a process that has complete control over the CPU(e.g., an infinite loop) using exceptions or traps.
First, the OS switches to kernel mode, disable the interrupt, and jump to the handler routine at a pre-specified address according to the interrupt vector and interrupt code. The routine starts by saving all registers, possibly setting the allowed interrupts to a level that guarantees correct execution without being interrupted again, and then executes the code to serve the interrupt. When the handler is done, it restores the registers and returns to the kernel code called the handler before, which then restore the user task status and switches to user mode, executing the instruction following the one at which the interrupt occurred. If there is no runnable task, the operating system jumps to the idle loop and waits for another interrupt.
The answer to this question is the same as first question‘s above.
Actually we can just write a simple program and debug it with GDB, in which we can change the registers/syscall_number or memory/stack_pointer before the syscall instruction, then observer what will happen next.
test.c:
#include <stdio.h>
#include <fcntl.h>
#include <errno.h>
int main(int argc, char const *argv[])
{
errno = 0;
if( open("/home/liqiuhao/tmp/main.go", O_RDWR) == -1)
{
perror("Error");
}
return 0;
}
Compile and debug:
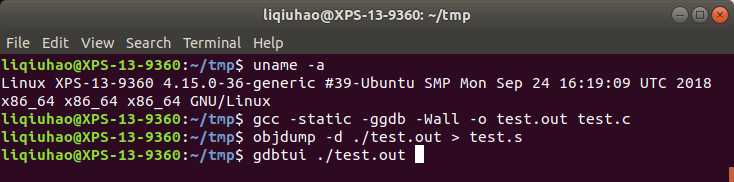
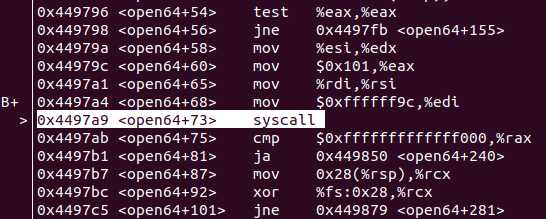
Set a breakpoint just before syscall in user sub __libc_open :
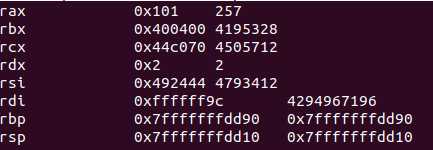
Registers:
By looking up the Linux Syscall Table for x86_64, we know that the compiler use openat instead of open :

First we can change the rax to an invalid system call number to see what will happen:
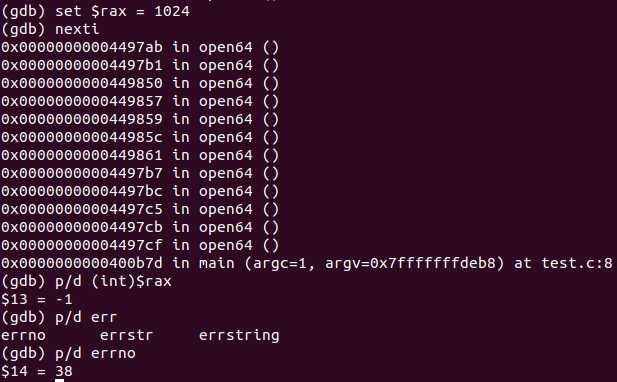
We find that the kernel correctly protects itself from this rogue system call and correctly set the error number:

Now we use an invalid stack pointer to see what will happen:
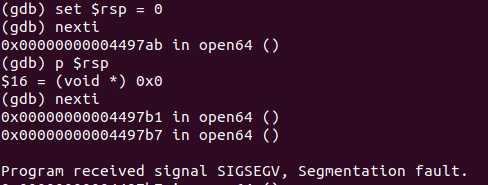
It seems like kernel correctly protects itself again, and it doesn‘t really care about our user ss:rsp registers --- just store and restore them. But the user program will have a highly chance to get a Segment fault later.
The invalid pointer experiment is the same as invalid stack pointer --- the kernel just keep the user stack during system call without any crash in itself.
Operating Systems Principles and Practice 2nd 2Ch Exercises
标签:try hat drivers current fine question mit most attention
原文地址:https://www.cnblogs.com/liqiuhao/p/9742002.html