标签:frame VID png 常用 取出 直接 ams nali ext
Background and Motivation:
现有的处理文本的常规流程第一步就是:Word embedding。也有一些 embedding 的方法是考虑了 phrase 和 sentences 的。这些方法大致可以分为两种: universal sentence(general 的句子)和 certain task(特定的任务);常规的做法:利用 RNN 最后一个隐层的状态,或者 RNN hidden states 的 max or average pooling 或者 convolved n-grams. 也有一些工作考虑到 解析和依赖树(parse and dependence trees);
对于一些工作,人们开始考虑通过引入额外的信息,用 attention 的思路,以辅助 sentence embedding。但是对于某些任务,如:情感分类,并不能直接使用这种方法,因为并没有此类额外的信息:the model is only given one single sentence as input. 此时,最常用的做法就是 max pooling or averaging 所有的 RNN 时间步骤的隐层状态,或者只提取最后一个时刻的状态作为最终的 embedding。
而本文提出一种 self-attention 的机制来替换掉通常使用的 max pooling or averaging step. 因为作者认为:carrying the semantics along all time steps of a recurrent model is relatively hard and not necessary. 不同于前人的方法,本文所提出的 self-attention mechanism 允许提取句子的不同方便的信息,来构成多个向量的表示(allows extracting different aspects of the sentence into multiple vector representation)。在我们的句子映射模型中,是在 LSTM 的顶端执行的。这确保了 attention 模型可以应用于没有额外信息输入的任务当中,并且减少了 lstm 的一些长期记忆负担。另外一个好处是,可视化提取的 embedding 变的非常简单和直观。
Approach Details:
1. Model
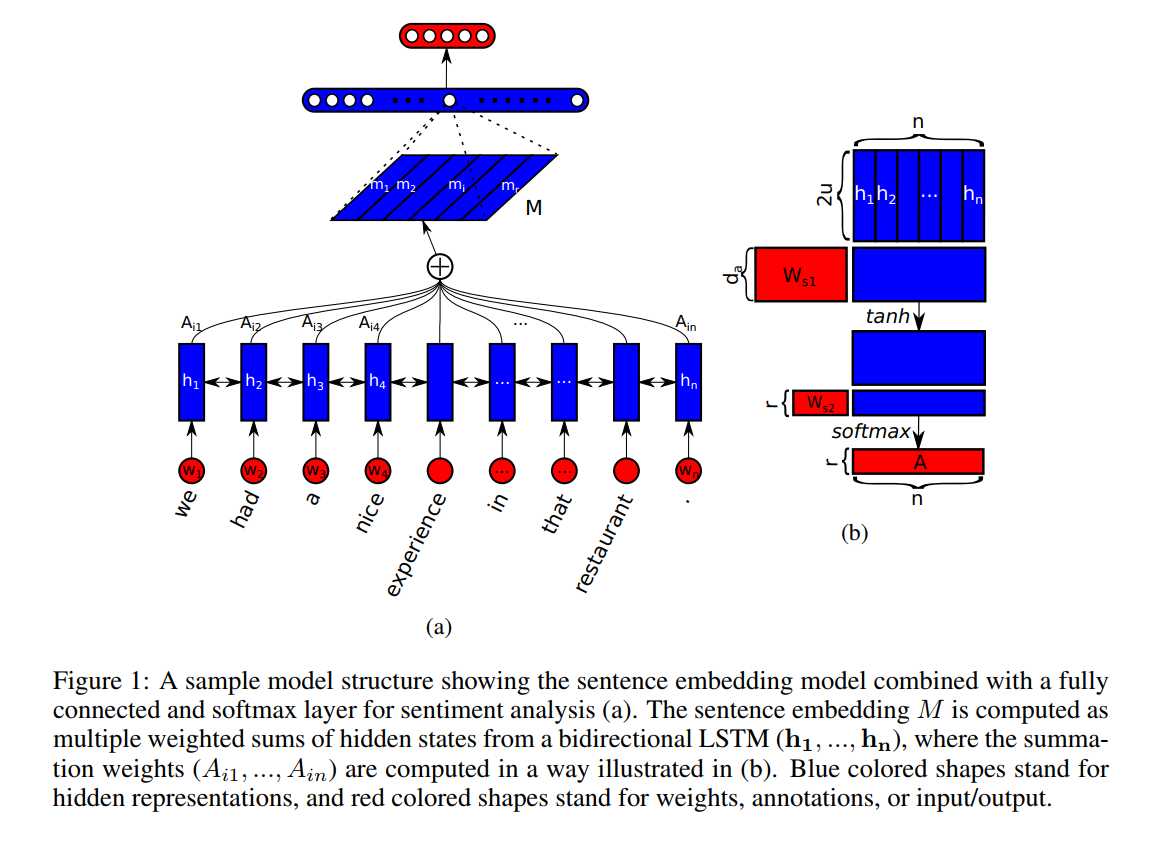
所提出的 sentence embedding model 包含两个部分:(1)双向 lstm;(2)the self-attention mechanism;
给定一个句子,我们首先将其进行 Word embedding,得到:S = (w1, w2, ... , wn),然后讲这些 vector 拼成一个 2-D 的矩阵,维度为:n*d;
然后为了 model 不同单词之间的关系,我们利用双向 lstm 来建模,得到其两个方向的隐层状态,然后,此时我们可以得到维度为:n*2u 的矩阵,记为:H。
为了将变长的句子,编码为固定长度的 embedding。我们想通过选择 n 个 LSTM hidden states 的线性组合,来达到这一目标。计算这样的线性组合,需要利用 self-attention 机制,该机制将 lstm 的所有隐层状态 H 作为输入,并且输出为一个向量权重 a:
![]()
其中,Ws1Ws1 是大小为 da?2uda?2u 的权重矩阵,ws2ws2 是大小为 dada 的向量参数,这里的 dada 是我们可以自己设定的。由于 H 的大小为:n * 2u, annotation vector a 大小为 n,the softmax()函数确保了计算的权重加和为1. 然后我们将 lstm 的隐层状态 H 和 attention weight a 进行加权,即可得到 attend 之后的向量 m。
向量的表示通常聚焦于句子的特定成分,像一个特定的相关单词或者词汇的集合。所以,我们需要反映出不同的语义的成分和放慢。但是,一个句子中可能有多个不同的成分,特别是长句子。所以,为了表示句子的总体的语义,我们需要多个 m‘s 来聚焦于不同的部分。所以,我们需要用到:multiple hops of attention. 即:我们想从句子中提取出 r 个不同的部分,我们将 ws2ws2 拓展为:r?dar?da 的 matrix,记为:Ws2Ws2,然后 the resulting annotation vector a 变为了 annotation matrix A. 正式的来说:
![]()
此处,softmax()是沿着输入的 第二个维度执行的。我们可以将公式(6)看做是一个 2-layer MLP without bias。
映射向量 m 然后就变成了:r?2ur?2u 的 embedding matrix M。我们通过将 annotation A 和 lstm 的隐层状态 H 进行相乘,得到 the r weighted sums,结果矩阵就是句子的映射:
M = AH
总结:第一种注意力其实就是对隐层H加入2层全连接,全连接最后一层维度1,第二种注意力最后一层维度不为1
2. Penalization Term
当 attention 机制总是提供类似的 summation weights for all the r hops,映射矩阵 M 可能会受到冗余问题的影响。然后,我们需要一个惩罚项,来估计 summation weight vectors 变的 diverse。
最好的衡量的两个 summation weight vectors 之间的度量方式就是:KL Divergence(Kullback Leibler Divergence),然而,作者发现在这个问题中,并不适合。作者猜想这是由于:we are maximizing a set of KL divergence, we are optimizing the annotation matrix A to have a lot of sufficiently small or even zero values at different softmax output units, and these vast amount of zeros is making the training unstable. 另一个 KL 不具有的特征,但是我们缺需要的是:we want to each individual row to focus on a single aspect of semantics, so we want the probabilty mass in the annotation softmax output to be more focused.
我们将 A 乘以其转置,然后减去单位矩阵,作为其冗余度的度量:
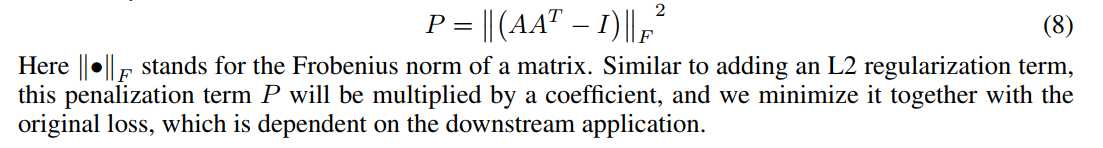


Experiments:

参考:
http://www.cnblogs.com/wangxiaocvpr/p/9501442.html
《A Structured Self-Attentive Sentence Embedding》(注意力机制)
标签:frame VID png 常用 取出 直接 ams nali ext
原文地址:https://www.cnblogs.com/zle1992/p/9744524.html