标签:加法 技术分享 联系 需要 编写 inf apt 存在 溢出
##所有的学习都是建立在8086CPU的基础上的
CPU的组成
如何描述CPU
(1)16位(字长和位宽相同,均为16位)
(2)准32位CPU(字长32位,位宽16位)
(3)超32位CPU(字长32位,位宽64位)
CPU字长是CPU在单位时间内能一次处理二进制位数
位宽,CPU通过外部数据总线与内存之间一次能够传送的数据位
寄存器的组成
(1)AX BX CX DX为通用寄存器,用来存放一般性的数据
(2)SI DI BP SP为基址和变址寄存器
(3)CS SS DS ES为段寄存器(CS寄存器:代码段段寄存器,用于存放代码段的「段地址」)
(4)IP FR为指令指针和标志寄存器(FR就是书上的PSW,即状态寄存器,是CPU运算器的一部分)(IP寄存器:指令指针寄存器,用于存放CPU将要读取的 指令在代码段中的偏移地址)
补充:状态寄存器用来存放两类信息:一类是体现当前指令执行结果的各种状态信息(条件码),如有无进位(CF位)、有无溢出(OV位)、结果正负(SF位)、结果是否为零(ZF位)、奇偶标志位(P位)等;另一类是存放控制信息(PSW:程序状态字寄存器),如允许中断(IF位)、跟踪标志(TF位)等。
注:以下以CS和IP寄存器为例来演示~~
2.对于兼容性的考虑,8086CPU可以一次性处理两种不同尺寸的数据。一个字由两个字节组成,所以这个字的高位字节和地位字节就分别存储在存储器的高8位存储器和低8位存储器中。如果把存储器看成两个独立的8位存储器来使用的时候,两个存储器之间是相互独立的。
3.数据划分
(1)字节 内存划分的基本单
(2)字 两个字节
(3)双字 四个字节
(4)四字 八个字节
注:指令的两个操作对象的位数应当是一样的,不可以操作一个16位寄存器和8位寄存器,也不能把超出寄存器位数的数据存入寄存器
背景:我们所学习的汇编都是建立在8086CPU的基础上的,8086是16位机(即在8086内部,能够一次性处理、传输、暂时存储的信息的最大长度是16位的),但是8086CPU有20位的地址总线, 所以8086CPU采用一种在内部用两个16位地址合成的方法来形成一个20位的物理地址。
物理地址=段地址x16+偏移地址(0~FFFFH)
以Page33的问题2.3为例:
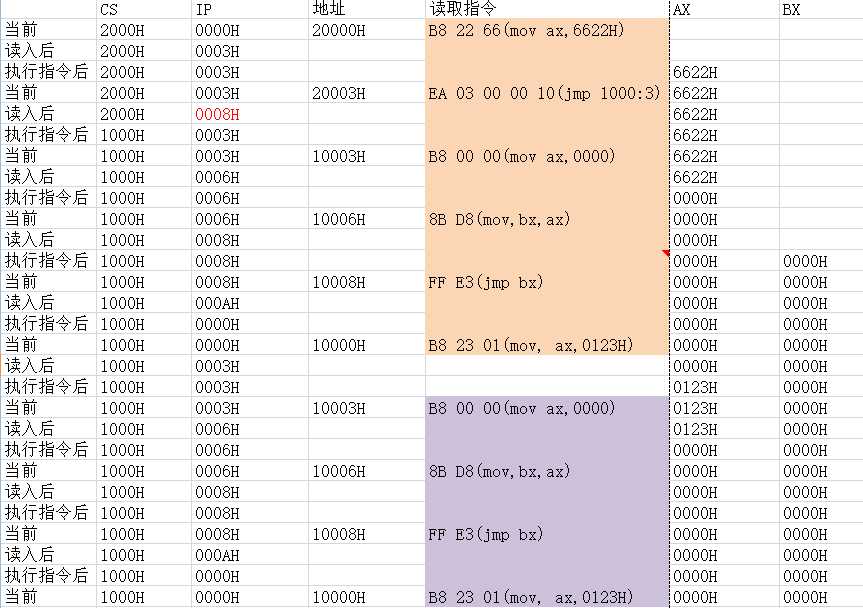
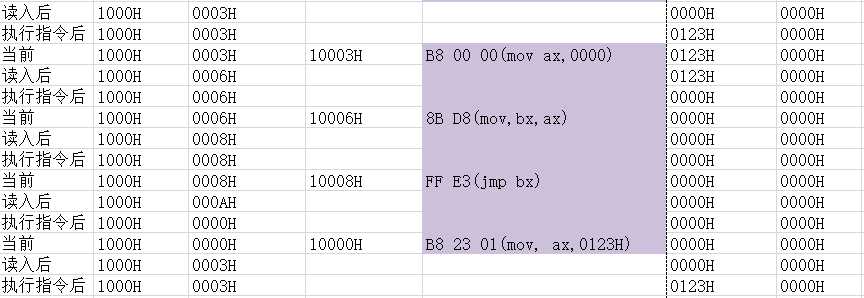
最后得出结论:
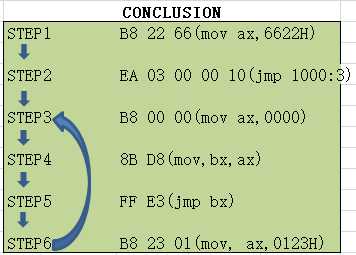
注意点:
拓展:将IA32拓展到64位(选自《深入理解计算机系统》)
我们正在经历一个想Intel指令集64位版本的过渡。最初由AMD提出并命名为x86-64,现在它被大多数的AMD64和Intel64处理器所支持。但是系统还是只运行这些操作系统的32位版本,但是较新的Linux和Windows版本都支持这种拓展。
IA32拓展到64位的原因:机器的字长定义了程序能够使用的虚拟地址范围,而32位字长也就是4GB的虚拟地址空间。对于需要处理大数据集的应用比如科学计算、数据库和数据挖掘来说,32位字长使程序员工作非常困难。他们必须使用out-of-core算法来编写代码。
X86-64
标签:加法 技术分享 联系 需要 编写 inf apt 存在 溢出
原文地址:https://www.cnblogs.com/Sun-Yiwen-blog/p/9745610.html